近十年来,人工智能又到了一个快速开展的阶段。深度学习在其开展中起到了国家栋梁的效果,虽然具有强壮的仿照猜测才能,深度学习还面临着超大核算量的问题。在硬件层面上,GPU,ASIC,FPGA都是处理巨大核算量的计划。本文将阐释深度学习和FPGA各自的结构特色以及为什么用FPGA加快深度学习是有用的,而且将介绍一种递归神经网络(RNN)在FPGA渠道上的完成计划。
揭开深度学习的面纱
深度学习是机器学习的一个范畴,都归于人工智能的范畴。深度学习首要研讨的是人工神经网络的算法、理论、运用。自从2006年Hinton等人提出来之后,深度学习高速开展,在自然言语处理、图画处理、语音处理等范畴都取得了特殊的成果,受到了巨大的重视。在互联网概念被人们遍及重视的年代,深度学习给人工智能带来的影响是巨大的,人们会为它隐含的巨大潜能以及广泛的运用价值感到难以想象。
事实上,人工智能是上世纪就提出来的概念。1957年,Rosenblatt提出了感知机模型(Perception),即两层的线性网络;1986年,Rumelhart等人提出了后向传达算法(Back PropagaTIon),用于三层的神经网络的练习,使得练习优化参数巨大的神经网络成为可能;1995年,Vapnik等人发明晰支撑向量机(Support Vector Machines),在分类问题中展示了其强壮的才能。以上都是人工智能历史上比较有代表性的工作,可是受限于其时核算才能,AI总是在一段高光之后便要堕入暗淡韶光——称为:“AI隆冬”。
可是,跟着核算机硬件才能和存储才能的提高,加上巨大的数据集,现在正是人AI开展的最好机遇。自Hinton提出DBN(深度相信网络)以来,人工智能就在不断的高速开展。在图画处理范畴,CNN(卷积神经网络)发挥了不行代替的效果,在语音辨认范畴,RNN(递归神经网络)也体现的可圈可点。而科技巨子也在赶紧自己的脚步,谷歌的领军人物是Hinton,其重头戏是Google brain,而且在上一年还收买了运用AI在游戏中打败人类的DeepMind;Facebook的领军人物是Yann LeCun,别的还组建了Facebook的AI实验室,Deepface在人脸辨认的准确率更抵达了惊人的97.35%;而国内的巨子当属百度,在挖来了斯坦福大学教授Andrew Ng(Coursera的联合创始人)并成立了百度大脑项目之后,百度在语音辨认范畴的体现一向非常强势。
一览深度学习
简略来说,深度学习与传统的机器学习算法的分类是一起的,首要分为监督学习(supervised learning)和非监督学习(unsupervised learning)。所谓监督学习,便是输出是有符号的学习,让模型经过练习,迭代收敛到方针值;而非监督学习不需求人为输入标签,模型经过学习发现数据的结构特征。比较常见的监督学习办法有逻辑回归、多层感知机、卷积神经网络登;而非监督学习首要有稀少编码器、受限玻尔兹曼机、深度相信网络等。一切的这些都是经过神经网络来完成的,他们一般来说都是非常复杂的结构,需求学习的参数也非常多。可是神经网络也可以做简略的工作,比方XNOR门,如图。
在图1(a)中,两个输入x_1和x_2都是分别由一个神经元表明,在输入中还加入了一个作为偏置(bias)的神经元,经过练习学习参数,终究整个模型的参数收敛,功用和图1(b)真值表如出一辙。图1(c)分类成果。
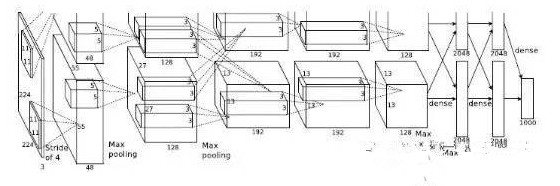
而一般来说,模型都是比较复杂的。比方ILSVRC2012年图画辨认大赛中Krizhevsky等人构建出来的 Alex Net。他们总共构建了11层的神经网络(5个卷积层,3个全衔接层,3个池化层),总共有65万个神经元,6千万个参数,终究抵达了15.2%的辨认错误率,大大领先于第二名的26.2%。
其时深度学习得以盛行,是得益于大数据和核算功用的提高。但其依然遭受核算才能和数据量的瓶颈。针对数据量的需求,专家们可以经过模型的调整、改动来缓解,但核算力的应战没有捷径。科大讯飞、百度、阿里、360在深度学习方面也面临着核算力的困扰。科大讯飞的深度学习渠道归于核算密集型的渠道,集群几百台机器之间要完成高速互联,是相似超算的结构,但它又不是一个非常典型的超算。科大讯飞最开端探究传统的办法,用很多CPU来支撑大规模数据预处理,运转GMM-HMM等经典模型的练习,在千小时的数据量下,效果很欠好。而360每天处理的数据有上亿条,参数50万以上,假如用CPU,每次模型练习就要花几天,这关于崇尚快速迭代的互联网公司运营来说简直是不行承受的。
为什么挑选FPGA
FPGA(Field Programmable Gate Array)是在PAL、GAL、CPLD等可编程逻辑器件的基础上进一步开展的产品。它是作为专用集成电路范畴中的一种半定制电路而呈现的,既处理了全定制电路的缺乏,又克服了原有可编程逻辑器件门电路数有限的缺陷。FPGA的开发相关于传统PC、单片机的开发有很大不同。FPGA以并行运算为主,以硬件描绘言语来完成;比较于PC或单片机(无论是冯诺依曼结构仍是哈佛结构)的次序操作有很大差异。FPGA开发需求从顶层规划、模块分层、逻辑完成、软硬件调试等多方面着手。FPGA可以经过烧写位流文件对其进行重复编程,现在,绝大多数 FPGA 都选用依据 SRAM(StaTIc Random Access Memory 静态随机存储器)工艺的查找表结构,经过烧写位流文件改动查找表内容完成装备。
运用CPU。在2006年的时分,人们仍是用串行处理器处理机器学习的问题,其时Mutch 和 Lowe开发了一个东西FHLib(feature hierarchy library)用来处理hierarchical 模型。关于CPU来说,它所要求的编程量是比较少的而且有可迁移性的优点,可是串行处理的特色变成了它在深度学习范畴的缺陷,而这个缺陷是丧命的。时至今日,据2006年现已曩昔了十年,曩昔的十年集成电路的开展仍是遵从着摩尔定律,CPU的功用得到了极大的提高,可是,这并没有让CPU再次走入深度学习研讨者的视界。虽然在小数据集上CPU能有必定的核算才能体现,多核使得它可以并行处理,可是这对深度学习来说仍是远远不够的。
运用GPU。GPU走进了研讨者的视野,比较于CPU,GPU的核心数大大提高了,这也让它有更强壮的并行处理才能,它还有愈加强壮的操控数据流和贮存数据的才能。Chikkerur进行了CPU和GPU在处理方针辨认才能上的不同,终究GPU的处理速度是CPU的3-10倍。
运用ASIC。专用集成电路芯片(ASIC)因为其定制化的特色,是一种比GPU更高效的办法。可是其定制化也决议了它的可迁移性低,一旦专用于一个规划好的体系中,要迁移到其它的体系是不行能的。而且,其造价昂扬,出产周期长,使得它在现在的研讨中是不被考虑的。当然,其优胜的功用仍是能在一些范畴担任。用的便是ASIC 的计划,在640×480pixel的图画中辨认速率能抵达 60帧/秒。
运用FPGA。FPGA在GPU和ASIC中取得了权衡,很好的统筹了处理速度和操控才能。一方面,FPGA是可编程重构的硬件,因而比较GPU有更强壮的可调控才能;另一方面,与日增加的门资源和内存带宽使得它有更大的规划空间。更便利的是,FPGA还省去了ASIC计划中所需求的流片进程。FPGA的一个缺陷是其要求运用者能运用硬件描绘言语对其进行编程。可是,现已有科技公司和研讨机构开发了愈加简略运用的言语比方Impulse Accelerated Technologies Inc. 开发了C-to-FPGA编译器使得FPGA愈加贴合用户的运用,耶鲁的E-Lab 开发了Lua脚本言语。这些东西在必定程度上缩短了研讨者的开发时限,使研讨愈加简略易行。
在FPGA上运转LSTM神经网络
LSTM简介
传统的RNN由一个三层的网络:输入层it,躲藏层ht,输出层yt;其间ht的信息效果到下一时刻的输入,这样的结构简略的仿照了人脑的回忆功用,图3是其拓扑图:
只要一个躲藏层方程:
其间 Wx和 Wh分别是输入和躲藏层的权重,b 是偏置。
LSTM 是RNN(递归神经网络)的一种,在处理时序数据得到了最广泛的运用,它由门操控信息总共有三个个门:输入门it,忘记门ft,输出门ot,别的还有躲藏层ht和回忆细胞ct。图4是其拓扑图:
输入门操控了某一时刻的输入;忘记门经过效果到上一时刻回忆细胞上,操控了上一时刻的数据流要流多少进入下一时刻;回忆细胞是由上一时刻的输入和这一时刻的候选输入一起决议的;输出门效果到回忆细胞上,决议了这一时刻的躲藏层信息,而且送到下一层神经网络上。悉数方程如下:
其间W 代表各自的权重,b 代表各自的偏置, σ 是logisTIc sigmoid 函数:
规划FPGA模块
一种递归神经网络在FPGA渠道上的完成计划详解
LSTM首要进行的是矩阵的乘法和非线性函数的核算(tanh,sigmoid),因而,挑选了Q8.8定点。
矩阵乘法由MAC单元进行(MulTIply Accumulate),总共有两个数据流:向量和权重矩阵流,如图6(a)。在迭代完一次之后MAC就会重置以避免之前的数据混入下一时刻的数据。两个MAC单元的数据相加之后进行非线性函数核算。一起用一个rescale模块将32位的数据转变为16位的数据。
标量核算的模块,是为了核算ct和ht,终究传入下一时刻的核算。如图6(b)。
整个模型总共用了三个图6(a)和一个图6(b)的模块,如图6(c)。数据的流入流出用了DMA(Direct Memory Access)串口操控。因为DMA串口是独立的,因而,还需求一个时钟模块对其进行时序操控。时钟模块首要是一个缓冲存储器组成并暂存了一些数据直到数据都抵达。当最终的一个端口数据流入时钟模块才开端传送数据,这确保了输入跟权重矩阵是同个时刻相关的。
经过在不同渠道上练习LSTM网络,咱们得到了不同模型的比照。表1是渠道的参数,运转成果如图7,可以发现:即便在142MHz的时钟频率下,FPGA渠道下的运转时刻远远小于其他渠道,并行八个LSTM 回忆细胞的处理取得了比 Exynos5422 快16倍的成果。
深度学习选用包括多个躲藏层的深层神经网络(DeepNeural Networks,DNN)模型。DNN内涵的并行性,使得具有大规模并行体系结构的GPU和FPGA成为加快深度学习的干流硬件渠道,其杰出优势是可以依据运用的特征来定制核算和存储结构,抵达硬件结构与深度学习算法的最优匹配,取得更高的功用功耗比;而且,FPGA灵敏的重构功用也便利了算法的微谐和优化,可以大大缩短开发周期。毫无疑问,FPGA在深度学习的未来是非常值得等待的。