今日给咱们带来的是咱们在FPGA规划中常常要遇到的规划技巧与思维,即乒乓操作,串并转化,流水线操作和跨时钟域信号的同步问题。
之前也看过一些书,也在网上找过一些材料,不过小墨发现大部分都是理论解说,只是是给一个框图就没事了,或许是好几个网站的材料都是相同的,都是仿制的一个当地的,只是是解说,没有实例,要不便是某个网站供给源码,可是要注册,还要花什么积分,没有积分还得要钱…很不利于初学者的学习(人与人之间怎样就不能多点信赖呢~还要钱…)。所以小墨想写这么一篇文章来介绍一下这4种思维,理论部分书上多得是,我就不过多的解说,首要给咱们讲一些实例型的帮咱们了解。
一、乒乓操作
乒乓操作首要用于数据流的处理,是用面积交换速度的表现之一,要知道面积与速度的交换贯穿FPGA规划的一直,下面先给一个框图
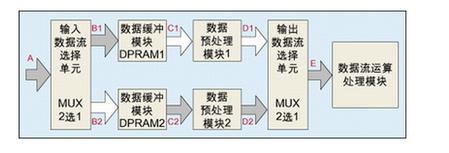
我先来解说一下乒乓操作的进程:
首要数据需求经过一个2选一数据挑选器,在榜首个时钟周期将数据缓存到缓存模块1,常用的缓存模块可所以fifo,双口RAM(DPRAM),单口RAM(SPRAM),第二个时钟周期的时分,数据流开端往缓存模块2里边写数据,与此同时,预处理模块会从缓存模块1里边读取数据,到了第三个时钟周期数据流再往缓存模块1里边写数据,与此同时,预处理模块2开端从缓存模块2读取数据,循环往复…这样,输入数据流和输出数据流按节拍来回切换,能够使数据没有中止的进行传输,使传输速率大大前进。
小墨同学发现,在给这个框图配实例的时分,简直一切的网站都是这个解说,我用红字标出,个人感觉解说的不怎样样,还有些当地是错的
假定端口 A 的输入数据流的速率为 100Mbps ,乒乓操作的缓冲周期是 10ms 。以下剖析各个节点端口的数据速率。
A 端口处输入数据流速率为 100Mbps ,在第 1 个缓冲周期 10ms 内,经过 “ 输入数据挑选单元 ” ,从 B1 抵达 DPRAM1 。 B1 的数据速率也是 100Mbps , DPRAM1 要在 10ms 内写入 1Mb 数据。同理,在第 2 个 10ms ,数据流被切换到 DPRAM2 ,端口 B2 的数据速率也是 100Mbps , DPRAM2 在第 2 个 10ms 被写入 1Mb 数据。在第 3 个 10ms ,数据流又切换到 DPRAM1 , DPRAM1 被写入 1Mb 数据。
仔细剖析就会发现到第 3 个缓冲周期时,留给 DPRAM1 读取数据并送到 “ 数据预处理模块 1” 的时刻一共是 20ms 。有的工程师困惑于 DPRAM1 的读数时刻为什么是 20ms ,这个时刻是这样得来的:首要,在在第 2 个缓冲周期向 DPRAM2 写数据的 10ms 内, DPRAM1 能够进行读操作;别的,在第 1 个缓冲周期的第 5ms 起 ( 肯定时刻为 5ms 时刻 ) , DPRAM1 就能够一边向 500K 今后的地址写数据,一边从地址 0 读数,抵达 10ms 时, DPRAM1 刚好写完了 1Mb 数据,并且读了 500K 数据,这个缓冲时刻内 DPRAM1 读了 5ms ;在第 3 个缓冲周期的第 5ms 起 ( 肯定时刻为 35ms 时刻 ) ,同理能够一边向 500K 今后的地址写数据一边从地址 0 读数,又读取了 5 个 ms ,所以截止 DPRAM1 榜首个周期存入的数据被彻底掩盖曾经, DPRAM1 最多能够读取 20ms 时刻,而所需读取的数据为 1Mb ,所以端口 C1 的数据速率为: 1Mb/20ms=50Mbps 。因而, “ 数据预处理模块 1” 的最低数据吞吐能力也只是要求为 50Mbps 。同理, “ 数据预处理模块 2” 的最低数据吞吐能力也只是要求为 50Mbps 。换言之,经过乒乓操作, “ 数据预处理模块 ” 的时序压力减轻了,所要求的数据处理速率只是为输入数据速率的 1/2 。
尽管各个网站上都是这么解说的,可是个人感觉解说的不怎样样,下面我用我自己的了解给咱们解说一下这个比如
先看我给咱们画的一个图,尽管画的不怎样样
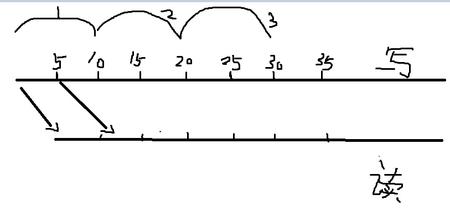
这儿咱们只核算缓存模块1的速率
首要看榜首个周期10ms,数据流往缓存模块1里边写数据,到第5ms时,预处理模块1开端从缓存模块1里边读数据,到10ms时,缓存模块1写了1M数据,读了5K数据,下面切换到第二个周期,因为在第二个周期的时分预处理模块1还能够从缓存模块1里边读数据,所以到第15ms时,缓存模块1里边的数据被读完
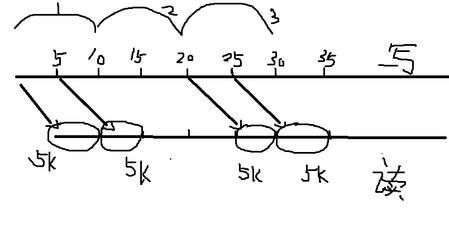
到了第三个时钟周期,也便是从第20ms开端数据流往缓存模块1写数据,到第25ms时,预处理模块开端从缓存模块读数据,直到35ms时才读完,这样咱们来算一下,在榜首个时钟周期读了5K数据,留意我上面画的时钟周期数,便是那个半圆形的,
在第三个时钟周期读了5k数据,留意每个时钟周期只要5K,别的5K到了下一个时钟周期了,所以咱们不考虑,咱们只考虑缓存模块1的速率。再看一下时刻,从第10ms读完榜首个5K,到第30ms读完第2个5k,共用了20ms,读了1M数据,所以速率为1M/20ms=50M/s。
下面再给咱们讲一个实例,详细代码我会附在文章后边
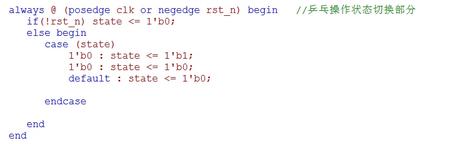
用state来操控乒乓操作的来回切换

依据方才讲的,操控缓存器的读写,这儿只列些部分代码,详细代码请咱们在文章后边下载
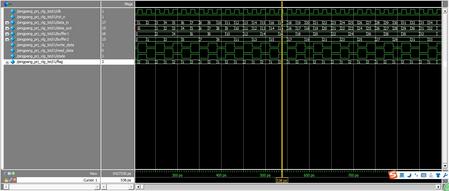
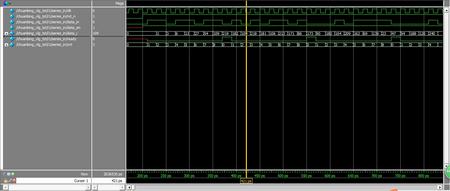
下面附上仿真时序图,我在testbench中将数据设为从0 递加的,能够看到仿真波形中是将奇偶数分隔的,证明咱们代码是正确的
二、串并转化
串并转化总的来说便是将串行输入信号转化为并行输出,也是用面积交换速度的一种办法,串并转化总的来说比较简单,小墨就只给咱们讲一下我自己写的代码吧
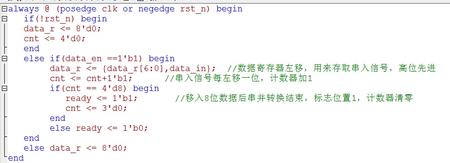
首要要先对串入信号进行收集,参加咱们是8位一输出,每进来一位数据,咱们便将原数据左移一位,确保数据是高位在前
然后再将数据并行输出即可,下面附上仿真波形,我在testbench中给串入信号设为随机数,看仿真图的,榜首串信号为1101_1011,一位一位的移进寄存器能够由波形的,别离是1,3,6……所以咱们的代码是正确的
三、流水线操作
流水线操作是高速规划中的一种常用手法,假设摸个规划的处理流程分为若干个过程,并且数据处理是单向流的,也便是没有反应或许迭代运算,前一个过程是后一个过程的输出,咱们就能够选用流水线规划的办法来前进规划速率。
举个比如,假设咱们要核算A+B+C的值,假设不必流水线操作的话,那么需求先核算A+B的值,再核算A+B+C的值,需求两个时钟周期,假设我用了流水线操作那么我需求在两个always块中别离核算sum1= A+B,sum2= sum1+C,因为两个always块是并行的,输出数据只需求等候一个时钟周期,今后就能够稀有据连绵不断的输出,就像流水线相同,然后前进体系速率
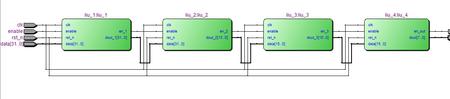
下面咱们来规划一个实例,假设我要收集一系列的32位数据,要对它进行处理,处理方式假设是,先对这个数据进行加16运算,再进行紧缩为16位数据运算,再进行减10运算
,最终进行取低8位运算,选用流水线规划的话,输出成果只需求等候几个时钟周期,今后就会有连绵不断地数据输出,流程框图如下,代码请在后边下载
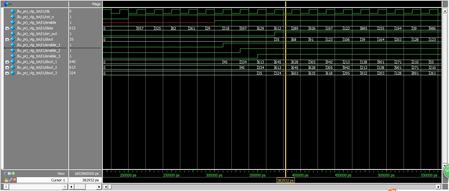
我在testbench中界说输入信号是随机的32位信号,别离进行分级处理,每处理完一级要给下一级发使能信号,并把数据送到下一级,例如当榜首级使能信号到来时,数据为29,29加16为45,即榜首级输出信号,对45取前16位仍为45,45减10为35,35取低8位仍为35,对照波形,证明咱们的规划是对的
四、跨时钟域信号同步
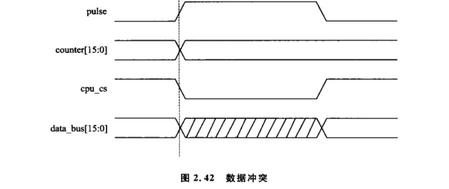
先来看一张图
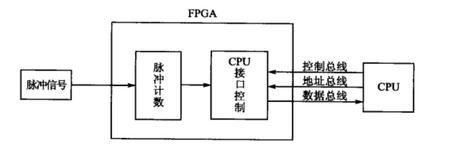
这个图的意思便是,脉冲信号为一个时钟信号,FPGA要对其进行计数,在CPU给FPGA发送读信号的时分,将计数器的值送至CPU的数据总线, 这儿就触及三个时钟信号,一个脉冲信号,一个CPU的读信号,一个FPGA的本身时钟,这三个时钟是不同步的,咱们这样想,假设在脉冲计数的时钟,cnt是自加1的,因为三个时钟不同步,CPU的读信号随时都有可能来,参加当cnt自加的时分,也便是cnt = cnt +1,这是对cnt的写状况,忽然来一个CPU的读信号,即那么就要把cnt送到数据总线,即data < = cnt,这是一个读状况,试问,一个数据既要读又要写,那读的是写之前的数据呢仍是写之后的数据呢?这便是亚稳态,切当便是不确定的意思,所以,咱们要将不同的时钟尽心同步处理,即在一个时钟的操控下进行脉冲计数和读操作,这样就不会产生亚稳态了,要知道,在一个大的体系中,亚稳态的损害是很大的
要处理同步问题,咱们能够用FIFO,DPRAM 进行同步,即用其他时钟域对fifo进行写操作,再用FPGA对fifo进行读操作,但要留意是否稀有据溢出,还有一种办法便是边缘脉冲检测法,这儿咱们讲第二种
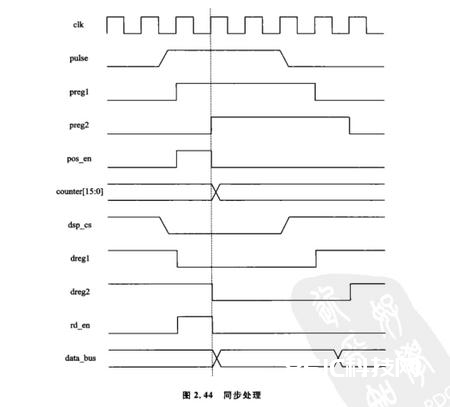
即选用两级寄存器,这两级寄存器均有FPGA的时钟操控,详细操作便是将不同域的信号都先赋值给榜首级寄存器,再在另一个always块中把榜首级寄存器的值赋给第二级寄存器,假设是信号是高脉冲,那么就把第二级寄存器取反与榜首级寄存器相与,便会得到一个高的脉冲采样信号,用这个信号在检测其他域信号的到来,假设是信号是低脉冲,那么就把榜首级寄存器取反与第二级寄存器相与,相同得到一个高的脉冲采样信号,用这个信号在检测其他域信号的到来,小墨同学把它记为“上2下1”准则,便利回忆~
详细代码在前面键盘部分现已有所解说,这儿就不副代码了
写了好几个小时,手都敲酸了,还望各位大神多多指教,有什么讲的不对的当地还请指出,一同前进~