现已安定运转了 50 年之久的摩尔规则就将迎来完结,但这背面也蕴藏着许多的时机。原文来自 Rodney Brooks 的博客。
摩尔规则究竟从何而来
Moore, Gordon E., Cramming more components onto integrated circuits, Electronics, Vol 32, No. 8, April 19, 1965.
Electronics 是一本 1930 年到 1995 年期间出刊的交易期刊。1965 年,戈登·摩尔(Gordon Moore)宣布于上的一篇长达四页半的文章或许是这本期刊最著名的文章了。这篇文章不只阐明晰一个趋势的开端,并且这种趋势逐步成为一个方针/规则,统治了硅基电路工业(这是咱们的国际中每一个数字设备的根底)五十年。摩尔是加州理工学院博士,是 1957 年树立的仙童半导体公司的创始人之一,一同自 1959 年起担任该公司的研制试验室主任。仙童是以制作硅基半导体发家的,其时大多数半导体仍是以锗为资料的,这种半导体工艺非常缓慢。
你可以从网络上搜到许多宣称其原稿复印件的文件,可是我留意到其间有一些所谓的原稿中的图是从头画上去的,与我一向看到的原稿有些不同。下面我将再现原稿中的两张图表,据我所知,我的这份仿制版是该杂志原稿的仅有仿制版别,没有手动/人工的痕迹。
首要我要再现的是摩尔规则来历精华。可是,该论文中还有一个相同重要的前期图表,猜测或许呈现的硅基功用电路的未来产值。它的实践数据比这个少,并且正如咱们所看到的,这张图表包括了实在的未来。
这是一张关于集成电路上元件数量的图。集成电路是经由一个相似于印刷的进程出产出来的。光以数种不同的办法打到薄薄的硅晶圆(wafer)上,一同会有不同的气体填充进它的气囊中。不同的气体会在硅晶圆外表引起不同的光致化学反响,有时会堆积某些类型的资料,有时会腐蚀资料。有了能刻画光线的准确光掩模(mask),准确操控好温度和曝光时刻,就能打印出一个二维电路。该电路上有晶体管、电阻和其它元件。其间许多或许是在单个晶圆上一次成型的,就像许多字母在一页纸上一次性印刷相同。在恣意一个做好的晶圆上电路上,其良率是质量合格的芯片占一个晶圆上芯片总数的份额。然后这块硅晶圆会被切成几块,每一块上都包括了一个芯片,并且每一个电路都放在自己的塑料封装中,只显露几只小「腿」作为衔接线,假如你查询一张曩昔四十年里芯片地图,你会上面充满了许多的集成电路。
单个集成电路中的元件数量很重要。已然集成芯片是打印出来的,进程中就没有人工的痕迹,这不同于前期的电子产品,其间的每个元件都需求手艺放置和添加。现在一个包括了多个集成电路的杂乱电路仅需求手艺拼装这些集成芯片就可以了,并且后来这道工序也很大程度上了。只需有一个良率不错的出产进程,那么造出一块单个集成芯片的时刻便是稳定的,不论组件的数量是多少。这意味着一共需求手艺或许机器衔接的集成芯片数量较少。所以,就像摩尔那篇论文的标题所说,把更多的元件集成到一个单个集成芯片上是一个很好的主见。
该图竖轴标明的是一块集成芯片上的组件数的以 2 为底的对数,横轴标明的是年份。左起一向向上延伸的每一个缺口都会将元件的数量添加一倍。所以 3 指的是 2 的三次方,等于 8,13 指的是 2 的 13 次方,等于 18192。从 1962 年到 1972 年,元件数量添加了 1000 倍。

这儿有两件事需求留意
榜首是摩尔这儿谈论的是一块集成电路上的元件,不只仅是晶体管的数量。一般来说元件的数量比晶体管要多出许多,虽然这一比率会因为运用不同底子类型的晶体管而跟着时刻的推移下降。但在后来的几年里,摩尔规则常常变成朴实的晶体管计数。
另一件事是 1965 年宣布这张图中只需四个实在的数据点。而在 1959 年组件的数量是 2 的零次方,也便是 1,底子算不上是一块集成电路,因为那只是单个电路元件——那时集成芯片没有创造。所以这是一个空数据点。之后他制作了四个实践数据点,咱们假设是从仙童公司或许发生的数据中收集的。1962、1963、1964、1965 这四个年份对应的数据点分别是 8、16、32 和 64。
这儿面的机制是什么,它怎么能起效果的?它能起效果是因为它在数字域中,也便是 yes 或 no 的域,0 或 1 的域。
在这篇四页半页的文章的后半页,摩尔解说了他的预言的局限性。他说关于一些东西,如储能,他猜测的趋势就不起效果。能量占用必定数量的原子和电子来贮存必定数量的能量,所以你不只不能随意改动原子的个数还需求存储相同量的能量。相同,假如你有一个半加仑的牛奶容器,你不能在里边放一加仑牛奶。
可是底子的数字笼统是 yes 或许 no。集成芯片中的电路元件只需求知道从前的元件是 yes 仍是 no,不论是否存在电压或电流。在规划阶段一决议多少伏特或安培以上为 yes,多少以下为 no。这些数字之间需求有一个很好的切割,区分出一个明显的中心区域与最大值区域或最小值区域。可是区域的起伏不会有什么影响。
我喜爱把它幻想成一堆沙子。桌子上有或没有一堆沙子?或许咱们需求确认一下大约多少沙子才干算得上是一堆沙子。可是正常状况下,把一堆沙子折半,咱们依然可以说桌子上有一堆沙子。
然后咱们能再次将这个数量折半。并且,yes 或 no 的数字笼统依然可以起效果。咱们还可以再折半,相同没问题。就这样,一次一次一次折半下去。
这便是摩尔规则的原理,开端的定理是这样描绘的:咱们将会看到集成芯片上的元件数量每年添加一倍,从 1965 年到 1975 年持续 10 年。
其他版别的摩尔规则接二连三;这些规则都是关于翻倍的,可是有时翻倍的是其他东西,并且翻倍需求的时刻常数会稍长。最盛行的版别是晶体管数翻倍、晶体管的开关速度翻倍、单个芯片上的存储空间翻一倍、核算机的二级内存翻一倍——其开端是在机械磁盘上,可是最近五年现已升级成固态闪存的办法。还有许多其他的版别。
让咱们暂时回到开端版的摩尔规则。一块集成芯片上的元件是散布在一块二维硅晶圆上的。因而,为了使相同数量的硅的数量添加一倍,就需求将每单位面积的元件数量添加一倍。那就意味着一个元件的巨细,在硅晶圆的每一个线性维度上要下降到本来的二分之一。反过来,那便是说,摩尔知道每个元件的线性维度会逐年下降 71%。
可是为什么会束缚在每年两倍的数量上?考虑一下上面说到的沙堆模仿,为什么不能是四分之一或许十六分之一堆的沙子作为基数呢?当你缩小元件的尺度(一般称为 feature size,特征尺度)时,问题就又回到某个集成芯片的良率上,也便是合格集成芯片的数量。跟着特征尺度越来越小,芯片制作进程中广每一步的光的投射办法的对准需求愈加准确。因为√2=1.41,当你将特征尺度折半才干得到更好的良率。并且因为资猜中的杂质也会被带到芯片中,从循环中的气体中而来并且经过光化学反响的资料,因而气体有必要是高纯度的,这样每个元件中的留存的坏原子才会更少。摩尔规则开端的版别中隐晦说到出产设备有望鄙人面的 10 年中,每年前进 29%。
在后来多种版别的摩尔规则中,翻倍的时刻常数延伸到 2 年,乃至还要长一点。可是处理设备会在每个周期前进 29%。
要才智摩尔规则原理的法力,让咱们先来看看 25 次翻倍。该设备有必要用比它小√2 的 25 次方倍的东西操作,即,大约小 5793 倍。可是咱们可以在单个芯片上设备 2 的 25 次方个组件,其数量可以抵达 33,554,432 倍之多。咱们设备的准确度现已前进了 5793 倍,可是,因为线性对区域的影响,在本来 5793 倍的根底上,这一数字进一步加快了 5793 倍。这便是摩尔规则收益的来历。
Moore 只是在开端的论文中隐晦地提出了这必规则,设备在接下来十年内逐年得到 29% 的前进。事实上,翻倍所用的时刻常数会更长。
现在总算到头了。并不是因为设备良率的准确度不再前进了。不是的。而是因为咱们拿来做比方的沙堆变得小到里边只需一粒沙子了。
戈登·摩尔令人难以置信的洞察力
或许让人形象最深入的是摩尔对该规则对国际发生的巨大影响的远见。下面是他文章中的第二段的榜首句话:集成芯片会带来许多令人惊奇的技能,比方家用核算机,或许至少是终端衔接在中心主动核算操控中心上的核算机,以及个人便携式通讯设备。
摩尔说到的这些东西在 1965 年都算的上惊世骇俗。其时所谓的「微型核算机」仍是桌子那么大的,用起来一般还要接一些外围设备,如磁带机、读卡器或打印机,这样的机器是很难进入日常家用厨房的,即便是把冰箱、烤箱和水池都扔出去,也很难放得下它。其时的绝大多数人还没有见过核算机,跟核算机互动过的人就更少了。并且一般状况下,运用这种设备的人需求把打孔卡片一张张拆开,然后当人把卡片都放入机器后,一天今后才干打印好。
以今日的规范来看,其时轿车电子体系非常简略,大约只需 6 个开关,若干个简略机电设备驱动转向指示,有挡风玻璃雨刮器,「分电盘」守时点着火花塞——在主动电子设备中每一个独自的功用发生的一点点机械都能大到用肉眼看见。其时的个人交流设备仍是转盘拨号电话机,一个家庭一部,牢牢地固定在墙上。
趁便提一下,集成芯片做成的榜首台核算机是用于阿波罗使命的制导体系核算机,指令模块(Command Module)中一台,月球登陆器(Lunar Lander)上一台。这些集成芯片都是由戈登·摩尔的仙童半导体公司制作的。榜首版的核算机上有 4100 个集成电路,每一块都有一个 3 输入或非门(NOR gate)。1968 年榜首台功用更强壮的载人飞行器仅有 2800 块集成芯片,每块芯片上有两个 3 输入或非门。摩尔规则在初具成形时就现已开端影响月球了。
一点题外话
原版的杂志文章中有这么一个漫画:

在摩尔规则 40 周年庆上,我问摩尔博士这幅漫画是不是出自他自己的构思。他回答说此事与他无关,文章中呈现这个卡通也让他很吃惊。
我找不到关于这幅漫画来历的一点点头绪,我猜测是这幅漫画的作者或许对我上面引证的这句话有些不满。漫画中的场景设在一个百货商店中,其时美国百货公司一般有一个「Notions」货台区,我自己没有去过这样的当地,因为现在现已没有了(我是 1977 年到的美国)。看起来,Notions 像是卖服饰用品的,比方一些用于缝纫的徽章、棉线、彩带等常用品。另一边是化妆品专柜。而这两个专柜的中心是便携式家用电脑专柜,售货员手里正拿着一台电脑。
我猜这位漫画家是想借此嘲笑摩尔的那个主意,企图指出它的荒唐。可是 25 年后全部都曩昔了,其时百货店里卖的东西也云消雾散了。买化妆品的专柜还在那里,notions 的货台早已不见踪影。这位漫画家只看到了他眼前的东西,却看不见未来的趋势。
摩尔规则中有许多不同的办法,不只是他开端提出的单个芯片上的元件数量。
在摩尔规则中,关于芯片运转速度有多快的说法有许多版别,其间一个是,晶体管越小,开关的速度越慢。一同关于 RAM存储量运转核算机的主内存有多少。还有关于文件存储和磁盘驱动巨细和速度也有多个版别。
多个摩尔规则混在一同对技能怎么开展发生了巨大的影响。我会谈论这种影响的三种办法:核算机规划中的竞赛、协谐和从众现象。
竞赛
内存芯片是数据和程序运转时的存储方位。摩尔规则适用于单个芯片可以存储的内存字节数,字节数一般是定时地四倍数的添加。因为是四倍的添加,所以硅晶圆代工厂的本钱就会长时刻内下降,这样一来可以坚持盈余了(今日,一家硅晶圆代工厂的本钱本钱大约是 70 亿美元!),此外还需求将每个 memory cell 在每个维度上添加一倍,以确保规划的平衡,因而这就又添加了四倍。
在前期的台式电脑的内存芯片中 2 的 14 次方(16384)个字节,其时的内存芯片是 RAM(随机存取存储器,即内存中的任何方位都需求相同长的拜访时刻,没有快慢之分),并且这样巨细的芯片被称为 16K 芯片,K 不是整好的 1000,而是 1024(即 2 的 10 次方)。许多公司都出产过 16K 的 RAM 芯片。可是他们从摩尔规则中学到的仅有相同东西便是商场上何时有望呈现 64K RAM 的芯片何时会呈现。所以他们也了解自己有必要要做什么才干坚持竞赛优势,他们也知道何时需求做好供工程师规划新机器的样品。他们会早早准备好芯片只需新机器一出来,就等着规划设备上去。他们还能判别出在什么时刻值得需求支付什么样的价值以在竞赛中坚持一点抢先优势。每家公司都了解这个游戏(事实上,关于摩尔规则的时钟什么时候需求调慢一些,他们现已达成了一起),他们竞赛的是作战功率。
协作
MIT科技谈论从前发文谈论过摩尔规则的完结。假如你是一名规划师,要为台式机器规划一个新的核算机机箱,或许其他相似的数字机器,你可以查询一下打入核算机商场的某个好时机,了解各种巨细的 RAM 内存所需求的电路板空间有多大,因为你现已知道了每个芯片有多少字节空间可用。你知道了磁盘空间的巨细与其价格和尺度的联系(磁盘直径的巨细会跟着其存储总量的前进而前进。)你会清楚最新的处理器芯片的运转速度会有多快。你会知道各种分辩率的显示器的价格。所以,当你方案向商场投进新式核算机时,你可以提早几年结合这些数字了解什么样的挑选和装备是有潜力的。
出售此款核算机的公司或许可以造出一两个要害芯片,可是大部分元件还得从供货商那里买。摩尔规则的周期功用让他们不必忧虑会忽然呈现一个颠覆性产品而打乱自己的业务流程和方案。这才是让数字改造墨守成规持续下去的本源地点。每件事都是有次序可以猜测的,所以很少遇到盲阱。在整个人类前史上的任何技能范畴,咱们或许具有了一个持续性和可猜测性最强的前进通道。
核算机规划中的从众心思
可是这种优点带来的一些影响也可以被看做是负面的(虽然我信赖有人会争辩论其优点是不折不扣的)。我将把其间之一作为谈论摩尔规则所深入影响的第三件作业。
当中心处理器可以被置于一张芯片(见下面的英特尔 4004)中时,通用核算机规划的一个特定办法呈现了,很快,芯片上的这些处理器(即众所周知的微处理器)就可以支撑通用架构,即冯诺依曼架构 。
这种架构的一个明显特色是:有一个很大的 RAM 内存包括着 RAM 芯片中发生的指令和数据,咱们在上文谈到了这个内容。内存被安排成可进行接连索引(或寻址)的方位区域,每个方位都包括同一数量的二进制比特信息或数字。微处理器自身有一些专门的存储单元(称为寄存器/ registers)和一个可进行加、乘、(最近呈现的)除运算的运算单元等。其间一种专门的寄存器被称为程序计数器(Program Counter/PC),它为当时指令保存内存中的一个地址。CPU 在当时的指令方位上查看比特信息的办法并将其解码成所应履行的操作。这个行为或许是为了取回 RAM 中的另一个方位,并将其放进某个专门的寄存器中(这个进程称为负载/LOAD),或是为了将内容发送到其他方向(STORE),或是为了将两个特别寄存器中的内容输送到运算单元中,接着对该单元的输出数据求和,将其存储在另一个专门的寄存器中。然后中心处理单元添加其 PC 的数量并查看下一个接连寻址指令。一些特别指令可以改动 PC 并使机器转去履行程序的其他部分,这个便是分支(branching)。例如,关于存储在 RAM 中的某个接连值数组,假如其间一个专门的寄存器被用来计数其求和元素的数量,那么紧跟在加法指令后边的就有或许是一条递减计数寄存器的指令,然后在程序前期进行兼并,履行另一个负载,假如该计数寄存器依然大于零就进行添加。
绝大多数数字核算机都是这样。其他破例都只是黑客们使其运转得更快,但本质上依然与此模型相似。不过请留意,冯诺依曼核算机以两种办法运用 RAM——用以包括程序中的数据以及包括程序自身。咱们稍后再谈这一点。
因为摩尔规则的全部版别都在坚定地运作以支撑这个底子模型,要想打破它好不容易。人类的大脑必定不会这样作业,所以好像存在其它一些强壮的办法来安排核算。可是企图改动底子安排是一件危险的作业,因为依据现有架构的摩尔规则将势不行挡地持续运作下去。测验新事物最有或许使开展后退几年。因而,比方来自 MIT 人工智能试验室(变成了至少三个不同的公司)的 Lisp Machine 或 Connection Machine 和日本第五代核算机方案(其研讨了两种非常规的思维:数据流/ data flow 和逻辑推理/logical inference)等英勇的大规模试验都失利了,因为之前长时刻的摩尔规则效应使传统核算机的功用翻了一番又一番,其效果逾越了新机器的许多高档功用,而软件却可以更好地模仿新思路。
大多数核算机架构师被锁在了已存在了几十年的传统核算机安排中。他们竞相改动指令的编码,使程序在每平方毫米上的履行功率略高一点。他们竞相更改战略,以求在主处理器芯片上缓存更大、更多的 RAM 内存副本。他们竞相讨论怎么在一张芯片上放置多个处理器、怎么在一张一同运转有多个处理器单元的芯片上同享 RAM 中的缓存信息。他们竞相研讨怎么使硬件在运转着的程序中更好地猜测未来决议方案,然后可以在白费心机之前预先进行下一个核算。可是底子上,他们都被锁在了核算的同一种办法上。三十年前,有几十种详细的处理器规划,但现在只需少量几个类别:X86、ARM 和 PowerPC。X86 大多是台式机、笔记本电脑和云服务器。ARM 多用于手机和平板电脑。你或许会用一个 PowerPC 来调整轿车的全部引擎参数。
图形处理单元(Graphical Processing Units/GPU)是打破摩尔规则桎梏的一个有目共睹的破例。 它们不同于冯诺依曼机。为了取得(特别是在游戏中)更好的视频图画功用,摩尔规则主导下的主处理器已变得越来越好,可是底层模仿也在变得越来越好,这并不足以前进实时烘托的效果。这种状况催生了一种新式的处理器。它关于通用核算不是特别有用,可是在(进行屏幕上的图形化烘托所需求的)数据流的加法和乘法运算方面被优化得很好。至此,一个新式的芯片被添加到摩尔规则池中,远远晚于传统的微处理器、RAM 和磁盘。新的 GPU 没有替代现有的处理器,而是作为图形烘托所需求的合作伙伴被添加进来。我在这儿说到 GPU 是因为本来它们对另一种类型的核算(在曩昔三年中现已变得非常盛行)很有用处,这正成为摩尔规则还未完毕的一个观念。我依然以为它会完结,下一节将回到 GPU 的论题。
咱们确认它会完毕吗?
如前所述,咱们将一堆沙子分红两半,却无法再分那终究一粒,这便是现在的境况,咱们面临的是一粒沙子,传统意义上的戈登·摩尔规则现已完毕了。
前面我谈到了集成电路的特征尺度(feature size)及其密度改动。1971 年,戈登·摩尔在英特尔,他们推出了其榜首个单芯片微处理器 4004 ——12 平方毫米巨细的芯片上散布有 2300 个晶体管,特征尺度为 10μm。这意味着该芯片上任何组件的最小可分辩尺度是千分之一毫米。
尔后,特征尺度有规则地下降,必定面积上的组件数量定时翻一番。虽然该期限正在逐步延伸。在摩尔开端宣布该规则的时代,芯片改造周期是一年。现在是两年多一点。在 2017 的榜首季度,咱们希望在群众商场上看到榜首款特征尺度为 10nm 的商用芯片产品,连 1971 年的千分之一都不到,或许说它是摩尔规则 46 年来收效了 20 次的效果。有时技能腾跃得比以往更快一些,因而 10 μm 到 10nm 之间实践上只需 17 次腾跃。你可以在维基百科上查看详细内容 。2012 年时特征尺度是 22nm,2014 年是 14nm,现在到了 2017 年的榜首个季度,咱们将会看到 10nm 特征尺度的芯片被送到终端用户手中,并有望于 2019 年左右看到 7nm 的产品面世。仍有一些活泼的研讨范畴致力于处理 7nm 特征尺度的难题,不过业界却对此信心十足。有预言说 2021 年会打破 5nm,可是就在一年前,能否处理与此相关的工程问题及其在各行业中的经济可行性怎么还存有很大的不确认性。
5nm 只需大约 20 个硅原子的巨细。假如再小的话,该种资料就会遭到量子效应的主导,经典物理学性质则会开端坍缩。这便是我所说的沙堆只剩一粒沙子的状况。
今日的微处理器有一张几百平方毫米巨细的芯片和 50 亿到 100 亿个晶体管。现在它们有许多额定的电路用以缓存 RAM、猜测分支等,然后抵达前进功用的意图。可是越来越大的尺度在变得更快的一同也带来了许多本钱。许多信号于转化进程中所运用的能量在很短的时刻内会散发出一些热量,而一个信号从芯片一边搬运到另一边的时刻终究会受限于光速(实践上光在铜介质中的速度会小一些),因而该时刻效应开端变得明显起来。光速大约是 30 万 km/s,或 3×10^11mm/s。因而光(或信号)在不超越 1×10^(-10)s 的时刻内可以传达 30 mm(一英寸多点,和今日的一个大芯片的尺度差不多),这个时刻不低于一百亿分之一秒。
当时最快的处理器的时钟速度是 8.760 GHz,这意味着在信号从芯片的一边传达至另一边的时刻内,芯片的这一边现已开端搬运下一个信号了。这使得单芯片微处理器的同步性成为了一个噩梦,而一个规划师充其量只能提早知道来自处理器不同部分的不同信号会迟到多久,并相应地测验进行规划。所以与其把时钟速度加快(这也很难),不如将单芯片微处理器做得更大、加上更多晶体管,让它在每个时钟周期内做更多作业,在曩昔的几年里,咱们现已看到大尺度芯片朝着「多核(multicore)」方向开展,一片芯片上有着 2、4 或 8 个独立的微处理器。
多核保存了「每秒履行的操作数」(摩尔规则的说法),可是该进程献身了简略程序的平等程度的加快履行功用——你不能简略地在多个处理单元上一同运转某一个单一的程序。关于企图一同运转许多使命的笔记本电脑或许智能手机来说,这种献身影响不大,因为一般会有足够多需求当即完结的不同使命被分包给同一芯片上的不同内核,然后使其得到充分运用。可是除了用于特别核算的使命,当核数量添加几倍时状况就不同了。在芯片被搁置时,加快便开端消失,因为没有足够多的不同使命需求被履行。
虽然我在上文中提出了为什么摩尔规则将会完结于芯片的相关论据,依然有许多人标明不认同,因为咱们方案经过多核和 GPU 来找到少量原子束缚问题的处理办法。但我以为这大大改动了界说内容。
这是 DFJ (Draper Fisher Jurvetson)出资公司的创始人 Steve Jurvetson 最近宣布在其 Facebook 主页上的一张图表。他说这是由 Ray Kurzweil 编写的对前期图表的一个更新。
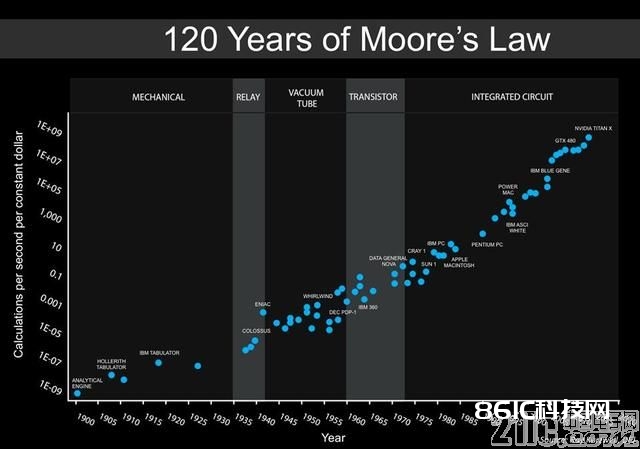
图表左轴是每秒每单位美元的核算次数(以对数标度)。它代表了核算随时刻推移的价格下降指数。20 世纪 40 时代有一些特别用处的核算机,比方布莱切利园(Bletchley Park,又称 X 电台)为破译暗码而制作的电磁核算机,它到了 50 时代就成为了通用型的冯诺依曼核算机并一向坚持到了图表终究的几个时刻点。
图中的终究两个点都要归功于 GPU :GTX 450 和 NVIDIA Titan X。Steve 没有符号出其之前的几个点,可是在我能查找到的(有许多)每一张前期版别的图表中,2010 年后的点都要归功于多核。首要是双核,然后是四核,比方英特尔四核 i7 处理器。
GPU 之所以存在以及人们对它感到振奋的原因是:除了图形处理,它们在另一个时尚的核算范畴也体现非凡——深度学习——一个开端被称为反向传达神经网络的东西——最近在技能范畴发生了巨大的影响。它使得语音辨认技能在曩昔三年间取得了飞快开展,然后令苹果的 Siri、亚马逊的 Echo 和 Google Home 成为了有用且令人满意的程序和设备。它也使得图画符号的质量比 5 年前前进了一大截,还有主动驾驶轿车的一部分态势感知试验,运用了许多的路途场景来练习网络。深度学习的练习阶段一般是在云端的数百万个样本之上进行的。它发生了几百万个数字,代表着所习得的网络。然后当它在辨认一个单词或符号一张图画时,输入数据会被送入某个程序,履行数百万个乘法和加法运算然后触发该网络的生成。偶然的是,GPU 只需在网络以这种办法被构建的状况下才干抵达最优的功用,所以咱们估计会有更多网络被归入到咱们的轿车中。GPU 制作商的春天来了!而 GPU 可以做巨大核算的这种才能在任何问题上都体现欠佳。但它们在深度学习网络方面体现优异,而深度学习正敏捷成为这十年的技能发力点。
咱们确认无疑地宣称着会持续看到指数式添加之时(如图),正是被测量量现已发生改动之时。这有点像是在变戏法。
我以为这种改动会发生非常大的影响。
摩尔规则的完结意味着什么?
我以为摩尔规则的完结——正如我对完结的界说——将会带来核算机架构的一个簇新的黄金纪元。架构师们不必再畏缩于摩尔规则的恶性竞赛中。他们将能花时刻去测验一些芯片方面的新主意,因为现在的传统核算机架构将无法在短短两年或四年内跟上软件迭代的脚步。并且他们或许不会测验去前进核算速度,或许是以其它办法来改进核算。
机器学习运转时刻
咱们现已看到运用用于深度学习网络的 GPU 作为运转时刻的引擎。但咱们也看到一些更详细的架构。例如,间隔谷歌具有自己的 TensorFlow Units(TPU) 芯片现已曩昔了一年左右的时刻了,该芯片经过有用下降(因为神经网络在低精度时体现适当杰出而保存下来的)重要数字的数量来为深度学习网络节省功率。谷歌现已把许多这种核算机中运用的芯片设备在其服务器集群或云端上,并可以将学习后的网络用于各种查找查询使命,它的速度更快且电力耗费更低。
专用芯片
现在一张典型的手机芯片有四个 ARM 处理器内核以及一些高度优化的特别用处的处理器。这些处理器办理着摄像头的数据流入并优化语音质量,乃至在一些芯片上有一个特别的高度优化过的处理器用于检测人脸。这是相机应用程序中所运用的处理器——你在摄影时或许留意到了人脸周围的小矩形——用来决议图画的哪些区域应该被要点重视并供给最好的曝光时刻——当然是脸!
通用用处的新办法
咱们现已看到为特定核算所规划的特别用处架构的兴起。但或许还会看到更多通用架构以一种不同的核算风格奋勇赶上。
可以想见,现在或许值得再次对日本第五代核算机方案的数据流和逻辑模型进行讨论。可是当咱们把国际数字化时,有害的核算机安全的本钱将要挟到咱们的生计。因而假如作业开展不错,或许被(摩尔规则的恶性竞赛)释放出来的核算机架构师们可以渐渐开端将咱们从现在的糟糕状况中解救出来。
安全核算
咱们都听说过网络黑客攻破核算机的作业,他们往往在地球的另一边,或许是彼时还在一台核算机上操控着引擎,而很快就开端操控其他的东西,比方一辆驶过的轿车。这是怎样发生的呢?
网络黑客很有创造力,但他们进入体系的许多办法底子上是借由程序中的一些常见的编程过错,这些程序树立在咱们之前谈过的冯诺依曼架构之上。
一个常见的办法是运用所谓的「缓存溢出(Buffer overflow)」。保存一个固定巨细的内存,例如输入到浏览器或谷歌查询框中的网页地址。假如全部程序员的代码都写得非常细心,而有人键入了过多的字符,那么其超出束缚的部分将不会被存储在 RAM 中。但一般状况是,一个程序员运用了一种简略而快速的编码技巧,这种办法不查看溢出,且键入字符以超出缓冲区规模的办法被保存起来,它或许会掩盖一些代码而使该程序跳到后方。这取决于冯诺依曼架构的特色——数据和程序存储在同一个内存中。所以,假如黑客挑选了一些字符,其二进制码对应于一些歹意行为的指令,比方为自己树立一个运用特定暗码的帐户,然后全部就像施了魔法般,黑客有了一个(相似许多其他人和程序服务或许会具有的)核算机长途拜访帐户。程序员不应该犯这种过错,但前史标明这种状况一次又一次地发生着。
另一种常见的办法是:在现代网页服务中,笔记本电脑、平板电脑或智能手机上的浏览器以及云中的核算机,它们有时需求在彼此之间传递一些非常杂乱的东西。无需程序员事前了解全部杂乱的或许状况并处理音讯,其设置办法是:使一方或两边可以来回传递一点程序源码并在其他核算机上履行代码。这种办法供给了在现有体系中推延作业而无需更新应用程序的强壮功用。无法确认一段代码不会去做某些作业,所以假如该程序员决议经过这一机制供给一个彻底通用的功用,那么接收机便无法提早知晓代码的安全与否以及它们是否会做一些歹意行为(这是停机问题的一般化——我可以持续进行下去…但不会)。所以有时网络黑客会运用这个缺点,并直接向一些承受代码的服务发送一点歹意代码。
除此之外,网络黑客总在创造新招——以上两例只是用来阐明黑客当下的一些行为办法。
可以编写代码来避免这些问题,可是代码编写依然是一项人为活动,而国际上存在太多人为创立的缝隙。一个应对办法是运用额定的芯片,该芯片对程序员躲藏了低层次的冯诺依曼架构的或许性,只是向内存中的指令供给更有限的或许行为调集。
这不是一个新主意。大多数微处理器有一些版别的「保护环(protection rings)」,这些保护环可以让更多不受信赖的代码仅能拜访越来越有限的内存区域,即便它们企图以正常的指令来进行拜访。这种主意现已存在了很长一段时刻,但它一向受阻于短少一个规范的办法去运用或履行它,所以大多数企图运转于大多数机器上的软件,一般只是指定 2~3 个保护环。这是一个非常粗糙的东西,它放过了太多的代码。当只是寻求速度已变得不再有用时,或许现在可以更认真地考虑一下这个主意,测验让环境变得愈加安全。
另一个主意——首要只在软件中完成过,或许有 1、2 个破例——被称为依据功用的安全(capability based security),来历于依据功用的寻址( capability based addressing)这个概念。程序不能直接拜访所需运用的存储器区域,但能取得不行假造的参阅加密处理,以及一个被界说的、被答应效果于内存的操作的子集。现在硬件架构师或许有时刻来持续推进该办法的彻底强制性履行,使其在硬件方面成功一次,因而朴实的人类程序员——他们被要求在许诺的发布期限内完成新软件——就不会把作业搞砸了。
从某个视点来看,我前面谈到的 Lisp 机是树立在一个非常详细而有限的、依据架构的功用的版别之上。实践状况是,那些机器是冯诺依曼机,可是它们可履行的指令是遭到成心束缚的。在硬件层面,经过运用被称为「类型指针(typed pointers)」的东西,对每一个内存的每一次引证,都会依据指针中所编码的类型来束缚指令对内存的效果。而内存只能在其被存储时经过一个指针被引证到一个固定巨细的内存块的起点。因而,在缓冲区溢出的状况下,一个字符串的缓冲区将不答应数据的写入或读取超出其规模。而指令只能从另一类型的指针——一个代码指针——中引证。硬件运用存储时被颁发的指针类型来将通用用处内存分红一个个非常细微的区域。粗略地讲,指针的类型永久不能被被变,RAM 中的实践地址也不或许被任何可拜访指针的指令看到。
怎么经过运用这种对通用用处的冯诺依曼架构的硬件束缚来前进安全性——这些主意现已呈现了很长一段时刻。我在这儿谈过其间的几个主意。现在我以为它会成为一个愈加招引硬件架构师去投入精力的范畴,因为咱们的核算体系的安全成为了确保咱们的企业、日子、社会可以顺畅运转的一个首要的丧命缺点。
量子核算机
现在量子核算机是一个以试验性为主且花费昂扬的技能。因为需求将它们冷却到物理试验等级的超冷温度且费用不菲,因而关于人们的一些困惑——它们或许会为传统的依据核算机的芯片带来多少加快,以及它们针对的是什么类型的问题——来说,现在量子核算机是一项出资大、危险高的研讨课题。我不会去考虑全部的参数(我没有读过全部的参数,坦白说我也不具备使我对自己或许构建出的任何观念都感到自傲的专业知识)可是 Scott Aaronson 有关核算杂乱性和量子核算的博客对感兴趣的人来说或许是最好的参阅来历。现已完成或被希望完成的对实践问题的加快宣言,其规模从 一 倍到几千倍(或许我所知道的这个上限有误)不等。在曩昔,只需等上 10 年或 20 年的时刻,就可以让摩尔规则带你抵达意图地。咱们反倒现已看到了对某项技能长达超越 10 年的持续性出资,人们依然在争辩该技能是否凑效。对我来说,这也进一步阐明,摩尔规则的完结正在鼓舞新的出资和新的探究。
无法幻想的东西
即便在摩尔规则的完结所触发的各种立异包围下,或许咱们所能看到的最好的事物还不在人类的一起认识中。我以为,在没有摩尔规则悬置的状况下,立异自在、需求时刻来研讨猎奇范畴的自在,很或许会发生核算模型方面的一个新的伊甸园。5 至 10 年后,咱们或许会在传统的(不是量子)芯片中看到一种全新的核算机安排办法,其速度会超呈现在的幻想。再往后开展 30 年,这些芯片或许会做出一些在今日看来与戏法并无差异的作业,就像今日的智能手机对 50年前的我来说近乎天方夜谭。