深度学习在无人驾驶范畴首要用于图画处理,也便是摄像头上面。当然也能够用于雷达的数据处理,可是根据图画极大丰富的信息以及难以手艺建模的特性,深度学习能最大极限的发挥其优势。
现在介绍一下全球摄像头范畴的巨头,以色列的mobileye公司是怎样在他们的产品中运用深度学习的。 深度学习能够用于感知,辨认周围环境,各种对车辆有用的信息;也能够用于决议计划,比方AlphaGo的走子网络(Policy Network),便是直接用DNN练习, 怎样根据当时状况作出决议计划。
环境辨认方面,mobileye把他们辨认方面的作业首要分为三部分,物体辨认,可行进区域检测,行进途径辨认。
物体辨认
一般的物体辨认是这姿态的:
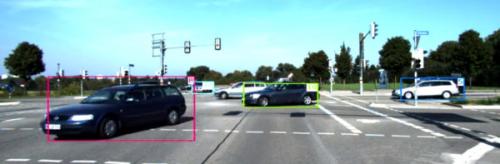
有一个长方形框框能辨认出来车在哪里,很好,很不错,可是Mobileye出来的是这姿态的:

以及这姿态的:

很明显的差异便是Mobileye能够完成十分精确的车的正面以及旁边面的检测,以及彻底正确的区别左面旁边面以及右边旁边面(黄色和蓝色)。

这两种检测成果的信息量是彻底不同的,左面这个检测成果告知咱们什么方位大约有一辆车,可是他的具体方位,车的朝向信息彻底没有。可是从右边的检测成果,就能够相对精确的预算出来车的方位,行进方向等重要信息,跟咱们人看到后能够估测的信息差不多了。
这样拔尖的成果,关于较近间隔的车,用其他根据几许的办法,多盯梢几帧,或许能够做到挨近的作用,可是留心远处很小的车,成果也彻底正确,这就只或许是深度学习的威力了。惋惜Mobileye创始人兼CTO总爱四处显摆他们技能怎样怎样牛,之前也常发论文同享一些技能,可是在车辆辨认怎样建模神经网络能够输出这么精确带orientation的bounding box,他仅仅微微一笑,说这儿面有许多tricks……可行进区域(free space)检测深度学习曾经的可行进区域检测,有两种办法,一是根据双目摄像头立体视觉或许Structure from motion, 二是根据部分特征,马尔科夫场之类的图画切割。成果是这样的:
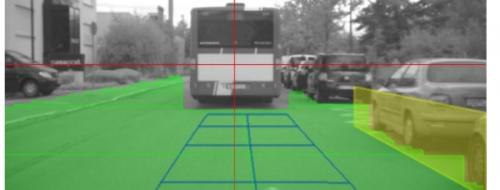
绿色部分是可行进区域检测,看着还不错对不对? 可是留意左面的绿色部分涵盖了马路“倒鸭子”以及人行道部分,由于“倒鸭子”也就比路面高十厘米左右, 靠立体视觉是很难跟马路区别开来的。而传统的图画切割也很困难,由于部分特征上,“倒鸭子”上和路面的色彩极点挨近。区别二者需要对环境整个context的归纳了解。
自从有了深度学习能够做scene understanding之后,这个问题总算被霸占了:

绿色部分仍是可行进区域,马路右边的路肩跟路面的高度相差无几,色彩texture也是如出一辙,用立体视觉的办法不或许区别开来。
并且不只仅可行进区域的鸿沟精确检测出来了,连为什么是鸿沟的原因也能够检测出来:

赤色表明是物体跟路途的鸿沟,鼠标方位那里表明的是Guard rail(护栏),而上一张图应该是Flat。这样在正常状况下知道哪些区域是能够行进的,而在紧迫状况下,也能够知道哪里是能够冲过去的。
当然,相较于榜首部分,这一部分的原理是比较清楚的,便是根据深度学习的scene understanding。学术界也有蛮不错的成果了,比方下图(Cambridge的作业),路面跟倒鸭子就分的很好(蓝色跟紫色):
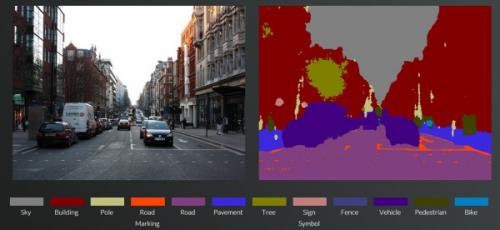
行进途径检测
这一部分作业要处理的问题首要是在没有车辆线或许车辆线状况很差的状况下,车怎样开的问题。假如一切的路况都如下:

那当然很完美,可是由于路况或许气候,有些时分车辆线是很难检测到的。
深度学习为此供给了一个处理办法。咱们能够用人在没有车道线的路况下开车的数据来练习神经网络,练习好之后,神经网络在没有车道线的时分也能大约判别未来车能够怎样开。这一部分原理也是比较清楚的,找一个人开车,把整个开车的进程摄像头的录像保存下来,把人开车的战略车辆的行进途径也保存下来。用每一帧图片作为输入,车辆未来一段时刻(很短的时刻)的途径作为输出练习神经网络。之前很火的Comma公司,黑苹果手机那个创建的,做的无人驾驶便是这种思路,由于其可靠性以及原创性还被LeCun轻视了。
成果如下,能够看到神经网络供给的行进途径基本上契合人类的判别:

更极点的状况:

绿色是猜测的行进途径。没有深度学习,这种场景也是彻底不或许的。当然,我在最近的别的一个答案里边说到了,不能彻底依托神经网络来做途径规划,Mobileye也是归纳传统的车道线检测,上面说到的场景切割检测到的护栏等,这一部分的神经网络输出等等,做信息交融最终得到一个安稳的完美的行进途径。