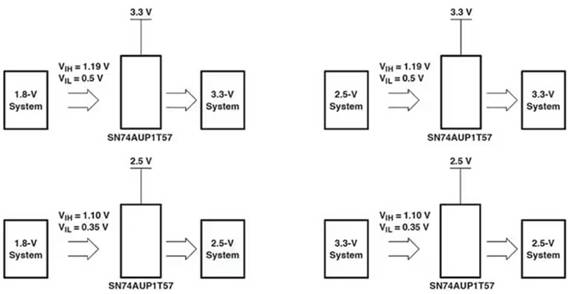
1 引 言
小波改换是近几年发展起来的一门数学理论和东西.由于它具有杰出的时频部分特性和多分辨率剖析特性,因而在现代信号处理,特别是在图画数据紧缩和处理中得到了广泛的运用.新一代静止图画紧缩规范JPEG2000也将小波改换归入规范之中,并选用二维离散小波改换(2D,DWT)作为体系编码算法的中心.
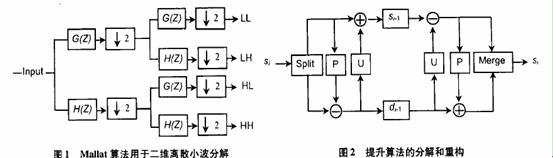
二维离散小波改换最有用的完成办法之一是选用Mallat算法,经过在图画的水平缓笔直方向替换选用低通和高通滤波完成,如图1所示.这种传统的依据卷积的离散小波改换核算量大,核算杂乱度高,对存储空间的要求高,不利于硬件完成.提高小波的呈现有用地处理了这一问题.提高算法相关于Mallat算法而言,是一种更为快速有用的小波改换完成办法,被誉为第2代小波改换.它不依赖于傅立叶改换,承继了第1代小波的多分辨率特征,小波改换后的系数是整数,核算速度快,核算时无需额定的存储开支.Daubechies现已证明,任何离散小波改换或具有有限长滤波器的两阶滤波改换都能够被分化成为一系列简略的提高进程,一切能够用Mallat算法完成的小波,都能够用提高算法来完成.
2 提高算法
对信号进行离散小波改换便是用多分辨率的方式分化信号,消除信号间的相关性。在每层分化信号都是用小波信号分化为高频段信号和低频段信号,即别离由相应的高通滤波器和低通滤波器来取得。提高办法是完成这些滤波运算的一个有用办法,并且办法适当简略。它运用根本的多项式插补来获取信号的高频重量,然后经过构建标准函数来获取信号的低频重量。每一步提高包括个进程分化,猜测和更新.如图2所示.
分化
分化便是把信号at-1,分为偶数抽样点at,和奇数抽样点dt,这也称为懒小波改换(Lazy Wavelet Transform)。设信号at-1为有限长度的一维离散输入序列,它们之间存在必定的相关性。为了消除相关性,首选把信号at-1分化为两个子信号at和dt。一般来说,关于信号分化的方式、两个子信号的巨细等,没有什么特别的约束,但要求存在某一与分化相对应的算子,能够从子信号at和dt,复原到at-1,这是离散小波改换和子带编码中最根本的要求,是由彻底重构性质所决议的。在离散小波改换和子带编码中常用的是二通道向下抽样(Downsampling),也便是把信号at-1分化为偶数采样点at,和奇数抽样点dt。这个改换实际上什么也没做,对信号表明方式也没什么改善,但这是后边进程的根底,一切的二进小波改换都是从这一步开端的。
猜测
猜测也被称对偶提高(Dual Lifting),便是由at猜测dt,用猜测差错替代dt,
dtdt-P(at)
at-1之间存在必定的相关性,故能够从at估量dt,令dt=P(at)这便是猜测。也能够说,是将at作为at-1的近似值。若信号之间的相关性很大,那么猜测作用会很好,将at作为at-1的近似表明不会“丢掉”许多信息。这就意味着能够“丢掉”部分信息,即dt,以到达简练表明的意图。为了彻底重建信号at-1,就只能“丢掉”包括在dt中的关于at的那部分信息,即可用dt-P(at)替代dt,既到达消除相关性的意图,也能确保存在某种逆算子,能够重建信号at-1。
更新
更新又称为首要提高(Primal Lifting),即用dt更新at,
atat+U(dt)
猜测后得到的这样一种新的表明方式中,很或许会丢掉信号的某些特征,如信号的均值,而这正是咱们所期望的如对信号进行紧缩时。为了康复这些特征,在提高算法中又引入了别的一种操作逐个更新(U),即用新得到的dt来更新at.
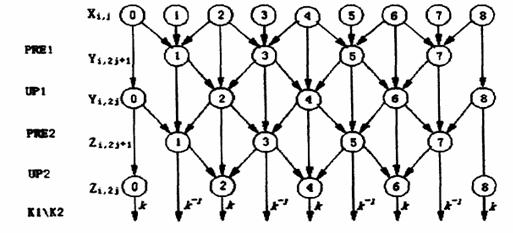
图3 提高算法的数据相关性
如图3所示,提高办法能够完成原位运算,即该算法不需求除了前级提高进程的输出之外的数据,这样在每个点都能够用新的数据流替换旧的数据流.当重复运用原位提高滤波器组时,就取得了交错的小波改换系数.由于小波改换需求较大的核算量,且核算杂乱度高,靠软件完成无法满意有用需求,其硬件完成日益遭到重视.其间,依据FPGA的小波改换及编码办法一直是研讨的热门.
3.算法剖析
内存需求剖析
对任何规划来说,咱们都期望所耗的内存越小越好。针对这点,在整数小波改换的规划中,首先要考虑到的便是整数小波系数的动态规模,由于它直接决议内部存储器的字宽,在存储器数量必定的状况下也就决议了一切存储器的容量。
以整数5/3小波改换为例,设输入信号为8位无符号数。那么沿行进行核算时,最大的或许值为255,最小或许值为-255,故细节值d的最坏状况有必要用S9(表明9位有符号数.对一个J级分化的小波改换来说,为了能共同的表明一切小波系数,内部存储器字的位宽有必要满意最坏的状况(便是在第J级的字长),这个字长便是S(8+2J)。例如,个J=4级的分化需求S16来表明得到的小波系数。
鸿沟延拓处理
小波改换中,有必要对原始图画分块鸿沟数据进行对称周期性延拓。设有信号ABCDEFGH,则延拓进程 如图4所示

图4 对称周期数据延拓进程
假如将对原始图画鸿沟数据的对称周期延拓作为独自的模块独立于小波改换模块之外,将添加存储器的数量和读写操作,增大硬件的面积。因而文献[1]提出了一种将对称周期延拓与小波改换模块彻底结合在一起的针对5/3小波改换的算法,文献[2]又对该算法进行了必定的改善,使该算法在硬件完成时有更低的核算杂乱度。该算法选用分段函数表明,用以将鸿沟延拓进程内嵌于小波改换模块中,分为3个阶段:1)开始阶段, 2)长期的正常运转阶段,中心数据的处理;3)完毕阶段,处理右端数据,奇、偶数序号信号完毕别离。
算法改善
针对上面的改善算法[2],咱们规划了一个5/3小波改换FPGA硬件结构,如图5。将猜测系数改为正,猜测部分加改为减,采纳直接运算,下降运算杂乱度;采纳添加操控状况,复用正常核算时的硬件结构。很明显,这种改善的“内嵌延拓提高小波改换”FPGA硬件结构与文献[1]比较,每行(每列)削减二个额定的硬件运算模块,下降了核算杂乱度。对图画的小波紧缩处理来说,提高了运算速度和硬件芯片的利用率,一起下降功耗。
4.FPGA完成
依据以上的论说,咱们规划以如下的完成计划,如图5所示。
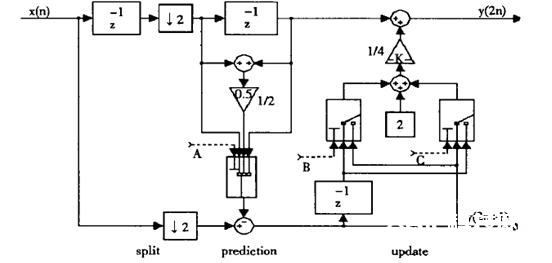
图5 整数小波硬件体系结构
5 功用剖析
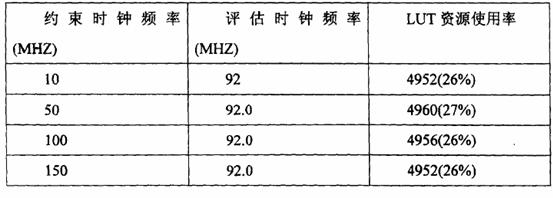
咱们选用FPGA为Xilinx公司出产的 Virtex2-Pro 系列XC2VP30,所需求的资源如表1所示。
表1 整数小波改换占用FPGA资源
6 展望
假如选用更高系列的FPGA芯片, 无疑会到达更高的处理速度,但性价比是工程中考虑的一个重要因素。跟着FPGA内部集成了越多越多的功用,用FPGA完成杂乱运算会遭到人们越来越多的喜爱。