0 引 言
跟着计 算机的 硬件, 特别 是 CPU 主 频的不 断提 升, 依据软件的音、视频编码功率也越来越高, 因而考虑 到本钱与各方面的要素, 软件 MCU 必定成为今后的主 流方向。但如今大多的 MCU 都是软硬件相结合, 纯软件的MCU 很少且功率不高。当时 H.323 视频会议体系大都是以 Open h323 协议库为 基 础 开 发 的 视 频 和 语 音传输体系 软 件。 Openh323 是由澳大利亚 Equivalence PtyLtd。公司组 织开 发 的, 能 实 现 基 本 的 H.32 3 协议框 架, 在Openh323V4 中, 依据视频缓存池的 MCU 最多只能处 理组成 4 路终端, 不能适应如今商场开展的需求, 因而从头设 计 MCU 的 架 构, 便成为 研 发 软 件 MCU 的要害 。
1 源MCU 的缺点和缺乏
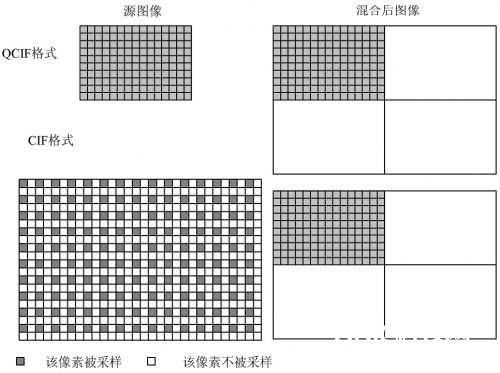
( 1) OpenH 3 23 中源 MCU 只能构成不超越 4 个终 端画面的图画。其间, 4 *1 为 CIF 格局 ( 35 2 * 28 8) ;1 * 1 为QCIF 格局( 176* 144) , 因而视频混合存在两种不同办法, 包含 QCIF 格局源图画混组成CIF格局图画以及 CIF格局源图 像 混 组成 CIF 格 式 图画, 如 图 1所示。
 |
| 图 1 传统MCU 图画组成 |
当源图画为QCIF格局时, 源图画巨细正好是混合 后图画巨细的1/4, 这时能够将源图画整幅地复制到混 合图画的相应方位; 当源图画为 CIF 格局时, 源图画与 混合后图画的巨细相同, 因而源图画 3/ 4 的像素有必要被 丢掉, 选用的办法是: 对源图画在水平方向进行隔点采 样, 在笔直方向进行隔行采样。这样处理之后, 源图画 巨细也正好是混合后图画巨细的 1/ 4 , 尽管图画的分辩 率现已下降, 可是坚持了源图画画面的完整性; 假如将MCU 变成可包容 16 个终端的显现画面, 在将 QCIF 源图画转换为 CIF 的组成图画 过程中, 只能将源图画 的采 样点按倍数削减。也 便是将 CIF 格 式 等 分 为16 份, 相 当 于 用 88 * 7 2 的 像 素 点 去 存 储 176 *144 QCIF 图画, 组成图画显现的像素点只有源图画的1/ 4; 假如将 MCU 可包容的终端数目扩大为 32, 乃至更多时, 图画的清晰度将大打折扣。
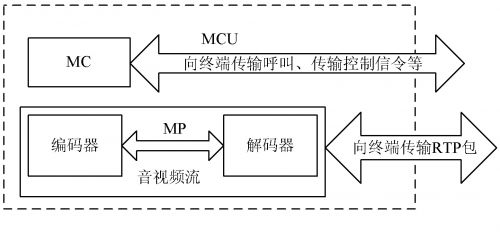
( 2) 传统软件 MCU 的架构是从硬件 MCU 承继过 来的, MCU 包含 MC 和 MP 部分。MC 部分对终端进 行衔接操控以及逻辑通道的办理; MP 部分对音频进行混合, 视频进行组成。传统 MCU 的规划如图 2 所示, 这种架构适用于硬件 MCU ; 但对用软件完成的 MCU 并不太合适。用软件完成的 MCU 的编解码都是经过 CPU 来运算 的, 这样 必定添加 CPU 的运算 负荷。例 如: 要编码一路 30 f/ s 的 CIF ( 352 * 288 ) 图画, 大约编 码后的字节数为 30 * 3 52 * 28 8 * 2 = 6 MB, CPU 要处 理如此大的视频数据量, 经测验, P4- 2.6 G 的 CPU 在 这种架构下, 最多支撑 5 路终端, 如超越 5 路, CPU 运 算负 荷过大, 其资源 根本耗尽, 图画 组成的效 果严峻 下降。因而, 要完成高功能的 MCU , 有必要把 MCU 对多路音、视频编码的大数据量处理的作业环节转移到各个终 端上, 让终端对相应的音、视频编码进行处理, 而 MCU 只对各路 的音 视频 流 进行 存 储转 发, 这 样才 能 减轻MCU 的负荷, 然后进步体系的全体功率。
 |
| 图 2 传统 M C U 规划图 |
2 帧缓冲映射的软交流形式的 MCU 的规划
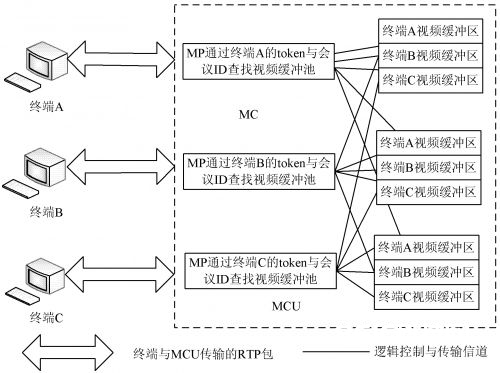
综上所述, 在此提出选用依据帧缓冲映射软交流的 MCU 体系规划形式, 所谓的软交流形式便是模仿交流 机的形式, 不对音、视频流进行编解码的处理, 只对数据 进行转发与操控。该MCU 也包含 MC 与 MP。依据软交流的 MP ,经过帧缓冲映射算法, 查找终端对应的缓冲区, 然后到把接纳到的音、视频流寄存到该缓冲区里边, 经过 MC操控, 把音、视频数据流通发到终端。
2. 1 M C 部分总体规划思维
MC 部分的规划 首要包含会议组 办理、会 议 RTP流通发办理。
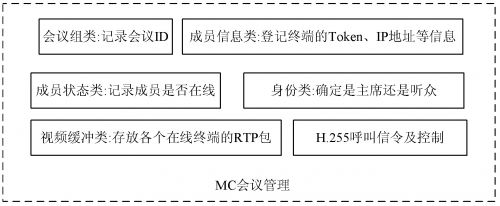
( 1) 会议办理。该体系只默许一组会议, 且默许的 会议房间为/ r oom1010 。对一组会议来说, 首要办理睬 议的成员信息, 处理与会者的参加与退出等。为了完成 这些功用, 树立一个会议 组类、成员信息 类、成员状 态 类、成员身份类和成员视频缓冲类。会议组类首要记载 终端所选的会议 ID; 成员信息类首要记载终端的 To- ken , IP 地址等信息; 成员类状况首要记载成员是否在 线; 成员身份类能够确定是主席, 仍是听众; 成员视频缓 冲类首要是寄存在线各个终端的 RTP 包, 一个缓冲类 里边能够存在多个缓冲区。MC 首要经过设定 TCP 特 定的端口, 并在端口上树立一个 TCP 监听线程, 终端通 过这个端 口与 MCU 进 行 TCP 连 接, 并由 MC 建 立 一个H.225 呼叫线程, 用于监听 H.22 5 呼叫信令, 经过 这个 H.225 通道, 终端把自己的会议组 ID, IP, Token 等身份认证注册到 MC。图 3 为 MC 的会议办理体系框图。
 |
|
图 3 MC 会议办理体系框图 |
( 2) 会议 RTP 流通发办理。MCU 对登陆终端进 行注册后, MC 树立一个 H. 245 操控信令线程, 并与该终 端进行衔接操控, 经过 H.245 操控信令与 MC 进行呼叫、 信令处理与才能洽谈、主从决议; 然后树立音、视频的接 收逻辑通道, 经过 RTP 接纳类开端接纳终端发送的 RTP 帧, 把 RT P 帧保存到分配给该终端缓存区里。MC 为已 经进行了呼叫衔接的终端分配了一一对应的视频缓冲接 收区, 该缓冲区是一个分配在堆里边的数据结构, 例如: 在终端 A 的在线人员列表上, 能够看到登陆注册到 MCU 的人员名单; 经过对终端的人员名单的挑选, 例如挑选 B, 那么终端 A 能够要求 MC 转发终端 B 的音、视频, 当MC 收到终端 A 提交的要求转发终端 B 的信 息后, 在MC 的 A 终端缓冲池里边, 为终端 B 新建一个缓冲区, 通 过 MP 对终端 B 的 Token 的帧缓冲映射查找到终端 B 的 音视频缓冲池, 并在终端 A 与终端 B 之间树立一条逻辑 通道, 用于向终端 A 传输终端 B 的 RTP 包, 当 MC 的终 端 A 缓冲类接纳到终端 B 的 RTP 包后, 把 RTP 包复制 到本来的接纳缓冲区里; 然后相同把终端 B 的专一 Token 经过哈希函数映射到这个缓冲区上。
图 4 为 MC 的 RTP 办理体系框图。MC 的软交流形式如图 5 所示。
 |
| 图 4 MC 的RTP 办理体系框图 |
 |
| 图 5 依据软交流的 MCU |
2. 2 MP 部分总体规划思维
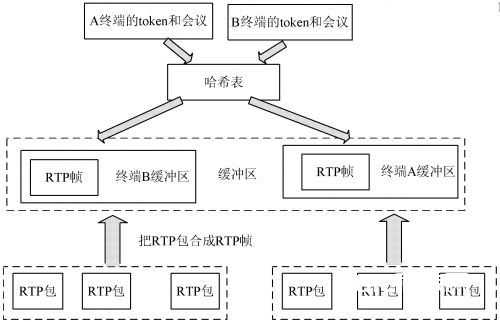
依据软交流的 MP, 经过帧缓冲映射算法查找终端 对应的缓冲区, 然后把接纳到的音、视频流寄存到该缓冲 区里边, 经过 M C 的操控, 把音、视频数据流通发到终端。 因为 MCU 需求处理很多的实时 RTP 包, 功率成为了最 首要的问题。因而怎么从缓冲区里边快速查找相应的数 据包是 M P 能否快速处理数据的要害。考虑到 M P 要处 理不同的终端, 不同的终端对应不同的缓冲区, 所以选用 哈希函数映射法, 它将恣意长度的二进制值映射为固定 长度的较小二进制值, 并把这个哈希表寄存到相应的内 存区, 以便屡次的查找, 这样经过这个较小的二进制值就 能够以非常快的速度找到比较大的数值。因而把视频缓 冲区的首地址寄存到一个哈希表里边, 并经过这个哈希 表把终端的Token 映射于这个缓冲区, 这样经过终端的 专一Token 便能够敏捷找到其对应的缓冲区。
完成 MP 部分帧缓冲映射算法的详细规划过程是: 首要 MCU 把登陆的在线终端 Token ( 终端的专一标识) 与会议 ID 默许为 room101, 经过哈希函数, 映射到一个 缓冲区, 经过终端的 Tok en 和会议 ID, 就能够直接找到 本终端 的缓冲区, 当 MP 收到 终端的 RTP 包后, 通 过 RTP 包的鸿沟剖析, 把多个 RTP 组成一个数据帧, 然后 把数据帧放到相应的终端缓冲区里边。帧缓冲映射的查 找如图 6 所示。假定当终端 A 要求转发终端 B 的音、视 频数据流时, M P 经过哈希函数找到相应终端 B 的缓冲区域, 然后把该缓冲区的数据读出到数据帧里边, 最终通 过 RTP 包进行发送到终端 A , 而终端 A 在接纳到 MCU 发送的终端 B 的音视频数据压缩包后, 再对其进行音视 频进行解码。
 |
| 图 6 帧缓冲映射查找图 |
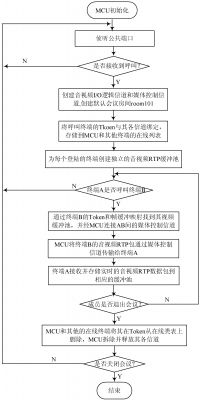
2. 3 MCU 体系完成
依据以上的规划思维, 得出如图 7 所示的 MCU 体系流程图。
 |
| 图 7 MCU 体系流程图 |
2. 4 测验结果与定论
经过从头规划 MCU 的 MC 和 MP 后, MCU 的性 能有了较大的进步。从功能方面进行测验, 因为传统的 MCU 在 MC 进步 行编解码, 只能容 纳4 路音、视频终 端, 而经过修正的 MCU , MC 没有进行编解码, 只对音、 视频进行存储转发, 因而在 9 路音、视频的情况下, 体系 的 CPU 只占有 5% 。从功率、质量方面进行比较, 因为 传统的 MCU 进行了 4 路编解码, 返回到终端的数据包 推迟比较大, 而修正过的 M CU 没有进行到编解码, 因 此数据包的延时很小。传统的 MCU 在 MC 里边进行 图画的混合, 图画的分辩率变为本来的 1/ 4, 因而图画 质量有较大的下降, 而依据软交流的 MCU 坚持了本来 图画的分辩率, 因而图画质量较好。从视频的帧数来比 较, 传统的 M CU 架构不能到达15 f/ s, 而依据软交流的 MCU 能到达 30 f / s 。因为依据软交流的 MCU 的视频 传输的是 本来 图画 的 分辩 率, 因 此 传输 率比 传 统的 MCU 要高, 但能够经过在终端选用传输率较低的编码 器来下降 传输 率。 表 1 为 M CU 改善 前与 改善 后的 比照。
| 表1 MCU 改善前与改善后的比照数据 |
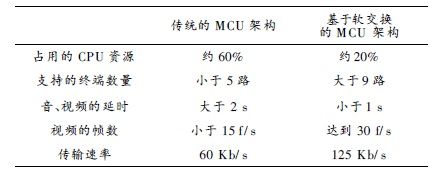 |
传统的 架构 依据软交流 的 MCU 架构占用的 CPU 资源 约 60% 约 20% 支撑的终端数量 小于 5 路 大于 9 路 音、视频的延时 大于 2 s 小于 1 s视频的帧数 小于 15 f / s 到达 30 f/ s传输速率 60 K b/ s 125 K b/ s终端的 6 分界面如图 8 所示。
 |
| 图8 终端6 分屏界面 |
3 结 语
从以上的测验证明, 依据软交流的 MCU 架构, 使 MCU 的功能有了很大的提 高。本文一起也说明晰只 要体系程序规划 合理, 依据 软件的 MCU 是 切实可行 的。跟着硬件水平的不断进步, 纯软件的 MCU 将以其低本钱、简易操作而遍及到低端用户。