跟着核算机使用越来越广泛,越来越多的重要信息需求由核算机屏幕显现,因而对核算机屏幕记载的需求越来越火急。一起, 伴跟着显现器的高速开展,核算机屏幕分辩率日益增大,需求记载的图画分辩率也逐步增大,因而,对可以记载核算机屏幕信息的设备需求日益增长。现在的图画紧缩存储计划大都无法支撑高分辩率图画,如ADI公司推出的图画紧缩芯片ADV212[1],该芯片支撑的最大分辩率为1 024×1 024,无法满意SXGA(1 280×1 024)或更高的图画分辩率。别的,在一些DSP解决计划中,由于DSP接口不灵敏以及DSP自身处理才能的约束,很难支撑高分辩图画紧缩。
本规划开发出了一套依据双FPGA+ARM架构的高速核算机屏幕图画紧缩体系。体系经过对图画紧缩体系使命的区分,使用FPGA的并行核算才能和灵敏的编程办法,完结图画紧缩算法。关于紧缩后的码流,体系选用ARM办理,依据linux的嵌入式ARM体系可以以文件的方法存储码流,别的,ARM对网络和音频常用设备能便利地办理。体系支撑干流接口(VGA,DVI),紧缩后的码流可以存储在本地硬盘,也可以经过网络发送到远端服务器。双FPGA的规划对核算机屏幕图画紧缩更为便利,原始图画经过前端预处理FPGA进行帧间检测,以决议该帧图画进入主FPGA的紧缩方法,主FPGA为中心紧缩引擎,担任完结高速图画紧缩算法。
1 体系架构与完结
体系全体架构如图1所示,选用双FPGA+ARM架构,首要包含图画前端预处理、图画紧缩模块和码流办理部分。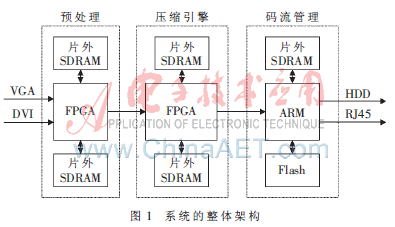
前面一块FPGA完结前端预处理,如分辩率检测、颜色转化和图画剖析等功能;后边一块FPGA用来完结图画实时紧缩,其间ARM对体系进行办理,如紧缩后码流办理、网络办理和音频录制等。
1.1 预处理模块
本体系一起支撑VGA、DVI两种干流显卡接口。选用AD9888[2]作为视频模数转化器,TI公司的TFP403[3]为DVI接纳芯片。Xilinx公司Virtex4[4](XC4VLX40)完结图画预处理,首要包含图画数据的收集、颜色空间转化和帧间检测。前端处理模块如图2所示。
1.1.1 图画数据收集
预处理FPGA接纳到的图画数据为接口芯片送来的图画数据,包含像素时钟信号(PCLK)、场同步信号(VSYNC)、行同步信号(HSYNC)以及数据信号(R[7:0],G[7:0],B[7:0])。图画数据的收集包含判别图画分辩率和提取图画数据两个过程。
当时的核算机屏幕分辩率许多,工业VGA规范规则了各种分辩率的像素时钟及场、行同步信号时序,依据相邻场同步信号(VSYNC)之间行同步信号(HSYNC)数目,以及相邻行同步信号(HSYNC)之间像素时钟(PCLK)数目辨认VGA信号分辩率。依据场同步信号(VSYNC)和行同步信号(HSYNC)提出图画数据。
1.1.2 颜色空间转化
VGA输出为RGB信号,而人眼对图画的亮度重量更为灵敏,所以,对图画数据进行颜色空间转化,将RGB信号转化为YUV信号,转化公式: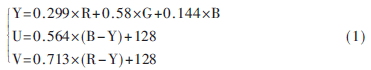
体系完结时选用4:2:2采样方法,FPGA选用定点化处理后,得到亮度重量Y 和色度重量UV。
1.1.3 帧间检测
帧间检测的中心思维是比照相邻两帧图画,判别每个像素点是否改变。以3×3的块为判别单元,假如有改变则将该像素方位和像素值都存起来;假如没有改变则不传输这些信息。当得到了一个4×4的块今后把这个16个点的信息作为一个全体传给后边的模块,然后核算1帧图画总的码流巨细。假如该值低于一个设定的阈值,则以为当时帧没有改变,直接传当时帧改变部分的像素和方位信息到后边的码流收拾模块;假如核算后码流的巨细大于设定的阈值,则将当时帧送入LX100中进行紧缩。
1.2 图画紧缩模块
图画紧缩为体系中心模块,该紧缩引擎包含小波改换和熵编码,算法悉数由体系主FPGA完结。该FPGA芯片选用Xilinx公司的Virtex4[4]系列FPGA(XC4VLX160)。图画紧缩引擎结构如图3。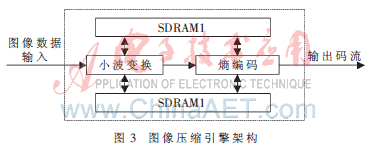
在体系算法规划中,图画小波改换选用了依据离散小波改换的空间推举算法(SCLA)[5]。不同于传统的离散小波改换(DWT),SCLA对行与列一起进行改换,其乘法次数是小波改换算法中最少的,而重建图画质量也很高,PSNR值优于JPEG,挨近JPEG2000。编码算法选用了改善的无链表零树编码算法(SLC),该算法归纳了多层次零树编码算法(SPIHT[6])和无链表零树编码(LZC[7])的特色,在功能上优于LZC,迫临SPIHT,并且易于硬件完结。
体系的架构由FPGA和两片外部SDRAM完结。SDRAM用于缓存小波改换后的小波系数。FPGA完结小波改换算法SCLA和熵编码算法SLC。SCLA算法由5个流水线小波滤波器完结,每个滤波器完结一层小波分化,而小波分化运算需求乘法器,在FPGA芯片选型时,依据小波滤波器中需求乘法器的个数挑选FPGA。在本体系中,5个流水的小波滤波器包含36个乘法器,关于亮度重量Y和色度重量UV两路数据并行处理,则需求72个乘法器,而在Virtex4系列FPGA(XC4VLX160)中有96个DSP单元。由小波改换得到小波系数,体系规划时选用2片外部SDRAM和FPGA片内SRAM结合的办法缓存小波系数。关于亮度重量Y和色度重量UV两路数据并行处理以进步体系吞吐量,SDRAM1和SDRAM2重量用来缓存Y和UV的小波系数。熵编码算法SLC担任对小波系数编码,该算法以一棵小波树为根本处理单元,即当时端小波系数构成一棵小波树时,熵编码模块便发动编码,然后完结一帧图画一切小波树的编码。
1.3 码流办理模块
关于图画经过FPGA紧缩后的码流,体系选用ARM芯片进行办理,该芯片为Cirrus Logic公司的工业级嵌入式处理器EP9315[8]。该处理器具有ARM920T核,最高主频达200 MHz,并具有丰厚的外围接口,包含网络、USB、音频等。FPGA和ARM之间通讯由I2C总线完结,当FPGA完结一帧图画紧缩后,经过FPGA的GPIO发送一个终端信号给ARM,并准备好一帧码流长度等信息。ARM中止服务程序响应该中止,经过I2C接口读走码流长度,经过映射SRAM的办法从FPGA读取紧缩码流到ARM内存,然后以文件的方法存储码流到本地硬盘,或许经过网络发送到远端服务器。
2 试验结果与功能
2.1 算法功能验证
体系规划初期,用软件对算法的功能进行了验证。在PC上对一组Lena等规范图画进行紧缩,得到不同的重建图画,对重建图画求解PSNR值,式(2)为PSNR核算公式。其间Mean Square Error(MSE)表明原始图画和重建图画对应像素的均方误差值。
表1为本体系选用算法与JPEG及JPEG2000对规范图画紧缩后重建图画的PSNR比较。从表中可以看出,本体系选用算法远优于JPEG,挨近JPEG2000。PSNR值的比较以紧缩比(对应表中Bitrate)为基准,即在相同紧缩比的情况下比照PSNR值。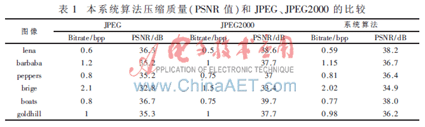
2.2 硬件完结和硬件紧缩
硬件体系电路板选用10层板制造工艺,电路板面积为30.8 cm×16.7 cm,在100 MHz作业频率下对体系测验,结果表明体系作业安稳。表2为体系对1 600×1 200、1 280×1 024和1 024×768三种常见分辩率的核算机屏幕进行的记载,记载的图画源选用了各类核算机屏幕常见图画,如Word文档、PPT文件、动态雷达图画和一段视频。其间,PPT的均匀翻页速度为60 s。由表2可以看出,体系关于Word文档、PPT文档等只要部分改变的图画可以到达十分高的紧缩比,紧缩帧率约为60帧/s。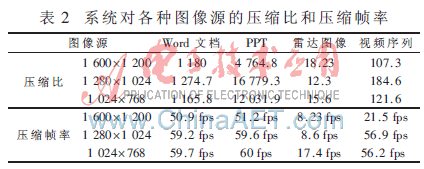
本文结合使用提出图画紧缩算,以FPGA为中心核算渠道,规划了一套核算机屏幕图画记载体系。体系完结了对1 280×1 024×24 bit图画每秒记载27帧,对1 600×1 200×24 bit图画每秒记载17帧,对PPT、Word文档等只要部分改变的屏幕图画每秒可记载60帧,且紧缩后重建图画质量优于JPEG,与JPEG2000挨近。一起,关于紧缩后的码流,体系选用ARM以文件的办法办理,有利于码流本地存储以及经过网络传输等灵敏的使用。别的,体系支撑多种输入接口,进步了硬件体系的灵敏性,具有宽广的使用远景。