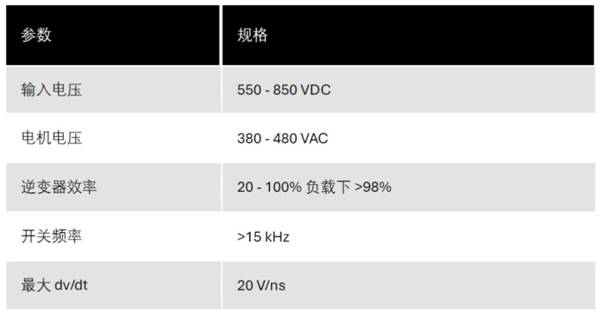
目录:
1.两种cpu架构:冯洛伊曼和哈佛
2.x86架构和arm架构剖析
3.x86架构和arm架构功耗探求
一.两种cpu架构:
现在干流的cpu处理器都选用了冯洛伊曼架构或许哈佛架构,那么这和x86\arm架构的联系是什么呢, 冯洛伊曼和哈佛这两个架构指的是cpu架构,是操控数据和代码存储的架构. 而x86和arm架构指的的cpu操控指令的调集,每一个指令代表cpu内部规划的一个硬件电路完结.在详细剖析x86和arm架构前先剖析下cpu存储架构:
1.哈佛结构:
哈佛结构(英语:Harvard architecture):是一种将程序指令存储和数据存储分隔的存储器结构。中央处理器首要到程序指令存储器中读取程序指令内容,解码后得到数据地址,再到相应的数据存储器中读取数据,并进行下一步的操作(一般是履行)。程序指令存储和数据存储分隔,能够使指令和数据有不同的数据宽度,如Microchip公司的 PIC16芯片的程序指令是14位宽度,而数据是8位宽度.哈佛结构的微处理器一般具有较高的履行功率。其程序指令和数据指令分隔安排和贮存的,履行时能够预先读取下一条指令。
现在运用哈佛结构的中央处理器和微操控器有许多,除了上面提到的Microchip公司的PIC系列芯片,还有摩托罗拉公司的MC68系列、Zilog公司的Z8系列、ATMEL公司的AVR系列和安谋公司的ARM9、ARM10和ARM11,51单片机也归于哈佛结构
2.冯·诺伊曼结构:

也称普林斯顿结构,是一种将程序指令存储器和数据存储器兼并在一起的存储器结构。程序指令存储地址和数据存储地址指向同一个存储器的不同物理方位,因而程序指令和数据的宽度相同,如英特尔公司的8086中央处理器的程序指令和数据都是16位宽。本结构含糊辅导了将贮存设备与中央处理器分隔的概念,因而依本结构规划出的核算机又称贮存程式型电脑
最早的核算机器仅内在固定用处的程式。例如一个核算器仅有固定的数学核算程式,它不能拿来当作文书处理软件,更不能拿来玩游戏。若想要改动此机器的程式,你有必要更改线路、更改结构乃至从头规划此机器。而贮存程式型电脑的概念改动了这一切。借由创造一组指令集结构,并将所谓的运算转化成一串程式指令的履行细节,让此机器更有弹性。借着将指令当成一种特别型态的静态材料,一台贮存程式型电脑可简单改动其程式,并在程控下改动其运算内容。冯·诺伊曼结构与贮存程式型电脑是相互通用的名词,其用法将于下述。而哈佛结构则是一种将程式材料与一般材料分隔贮存的规划概念,可是它并未彻底打破冯.诺伊曼架构。
贮存程式型概念也可让程式履行时自我修正程式的运算内容。本概念的规划动机之一便是可让程式自行添加内容或改动程式指令的内存方位,由于前期的规划都要运用者手动修正。但随着索引暂存器与直接方位存取变成硬件结构的必备机制后,本功用就不如以往重要了。而程式自我修正这项特征也被现代程式规划所弃扬,由于它会形成了解与除错的难度,且现代中央处理器的管线与快取机制会让此功用功率下降。
从全体而言,将指令当成材料的概念使得组合言语、编译器与其他主动编程东西得以完结;能够用这些“主动编程的程式”,以人类较易了解的办法编写程式[1];从部分来看,着重I/O的机器,例如Bitblt,想要修正画面上的图样,以往是以为若没有客制化硬件就办不到。但之后显现这些功用能够借由“履行中编译”技能而有用到达。
此结构当然有所缺陷,除了下列将述的冯·诺伊曼瓶颈之外,修正程式很或许是十分具损伤性的,不管无意或规划过错。在一个简略的贮存程式型电脑上,一个规划不良的程式或许会损伤自己、其他程式甚或是操作体系,导致当机。缓冲区溢位便是一个典型比方。而创造或更改其他程式的才干也导致了歹意软件的呈现。运用缓冲区溢位,一个歹意程式能够掩盖呼叫仓库(Call stack)并覆写程式码,而且修正其他程式档案以形成连锁损坏。内存维护机制及其他办法的存取操控能够维护意外或歹意的程式码更动。
谈论:
哈佛结构和冯.诺依曼结构都是一种存储器结构。哈佛结构是将指令存储器和数据存储器分隔的一种存储器结构;而冯.诺依曼结构将指令存储器和数据存储器合在一起的存储器结构。哈佛结构与冯·诺依曼结构的最大差异在于冯·诺依曼结构的核算机选用代码与数据的一致编址,而哈佛结构是独立编址的,代码空间与数据空间彻底分隔。
二.x86架构和arm架构差异点剖析:
英文缩写:
ISA指令集架构,Instruction Set Architecture
CISC杂乱指令集核算机,Complex Instruction Set Computer
RISC精简指令集核算机,Reduced Instruction Set Computer
EP%&&&&&%显性并行指令核算,Explicitly Parallel Instruction Computing
MMX多媒体扩展指令集,Multi Media Extended
SSE单指令多数据流扩展,Streaming-Single instruction multiple data-Extensions
1>硬件的功用逻辑完结不同:
什么是架构,咱们要了解CPU是一个履行部件,它之所以能履行,也是由于人们在里边制作了履行各种功用的硬件电路,然后再用必定的逻辑让它依照必定的次第作业, 这样就能完结人们给它的使命。也便是说,假如把CPU看作一个人,首要它要有正常的作业才干(既履行才干),然后又有满足的逻辑才干(能了解干事的顺 序),最终还要听的懂他人的话(既指令集),才干正常作业。而这些会集在一起就构成了所谓的“架构”,它能够了解为一套“东西”、“办法”和“标准”的集 合。不同的架构之间,东西或许不同,办法或许不同,标准也或许不同,这也形成了它们之间的不兼容——你给一个意大利泥瓦匠看一份中文写成的烹饪攻略,他当 然不知道应该干什么了。
2>CISC和RISC
cpu关于机器码的每一个bit的解说都不同,arm是类risc中比较成功的一种,指令集简略,一切指令都是32位或许16位的,而cisc的x86不等长,所以指令猜测都比risc要难做一些。
假如还看不理解,没联系,咱们持续。从CPU创造到现在,有十分多种架构,从咱们了解的X86,ARM,到不太了解的MIPS,IA64,它们之间的间隔都 十分大。可是假如从最底子的逻辑视点来分类的话,它们能够被分为两大类,即所谓的“杂乱指令集”与“精简指令集”体系,也便是常常看到的“CISC”与 “RISC”。归于这两种类中的各种架构之间最大的差异,在于它们的规划者考虑问题办法的不同。咱们能够持续举个比方,比方说咱们要指令一个人吃饭,那么 咱们应该怎样指令呢?咱们能够直接对他下达“吃饭”的指令,也能够指令他“先拿勺子,然后舀起一勺饭,然后张嘴,然后送到嘴里,最终咽下去”。从这儿能够 看到,关于指令他人干事这样一件作业,不同的人有不同的了解,有人以为,假如我首要给接受指令的人以满足的练习,让他把握各种杂乱技能(即在硬件中完结对 应的杂乱功用),那么今后就能够用十分简略的指令让他去做很杂乱的作业——比方只需说一句“吃饭”,他就会吃饭。可是也有人以为这样会让作业变的太杂乱, 究竟接受指令的人要做的作业很杂乱,假如你这时分想让他吃菜怎样办?莫非持续练习他吃菜的办法?咱们为什么不能够把作业分为许多十分底子的过程,这样只需 要接受指令的人懂得很少的底子技能,就能够完结相同的作业,无非是下达指令的人略微累一点——比方现在我要他吃菜,只需求把刚刚吃饭指令里的“舀起一勺 饭”改成“舀起一勺菜”,问题就处理了,多么简略。
这便是“杂乱指令集”和“精简指令集”的逻辑差异。或许有人说,显着是精简指令集好啊,可是咱们欠好去判别它们之间究竟谁好谁坏,由于现在他们两种指令集 都在蓬勃开展,而且都很成功——X86是杂乱指令集(CISC)的代表,而ARM则是精简指令集(RISC)的代表,乃至ARM的姓名就直接表明晰它的技 术:Advanced RISC Machine——高档RISC机。
这便是RISC和CISC之间欠好直接比较功用的原因,由于它们之间的规划思路差异太大。这样的思路导致了CISC和RISC各奔前程 ——前者愈加专心于高功用但一起高功耗的完结,而后者则专心于小尺度低功耗范畴。实践上也有许多作业CISC愈加适宜,而别的一些作业则是RISC愈加合 适,比方在履行高密度的运算使命的时分CISC就更具有优势,而在履行简略重复劳动的时分RISC就能占到优势,比方假定咱们是在举行吃饭大赛,那么 CISC只需求不断的喊“吃饭吃饭吃饭”就行了,而RISC则要一遍一遍重复吃饭流程,担任喊话的人假如嘴巴不够快(即内存带宽不够大),那么RISC就 很难吃的过CISC。可是假如咱们仅仅要两个人把饭舀出来,那么CISC就费事得多,由于CISC里没有这么简略的舀饭动作,而RISC就只需求不断喊 “舀饭舀饭舀饭”就OK。
这便是CISC和RISC之间的差异。可是在实践状况中问题要比这杂乱许许多多,由于各个阵营的规划者都想要提高自家架构的功用。这儿面最遍及的便是所谓 的“发射”概念。什么叫发射?发射便是一起能够履行多少指令的意思,例如双发射就意味着CPU能够一起拾取两条指令,三发射则天然便是三条了。现代高档处 理器现已很少有单发射的完结,例如Cortex A8和A9都是双发射的RISC,而Cortex A15则是三发射。ATOM是双发射CISC,Core系列乃至做到了四发射——这个方面咱们却是平起平坐,可是不要忘了CISC的指令愈加杂乱,也就意 味着指令愈加强壮,仍是吃饭的比方,CISC只需求1个指令,而RISC需求5个,那么在内存带宽相同的状况下,CISC能到达的功用是要超越RISC的(就吃饭而言是5倍),而 实践中CISC的Core i处理器内存带宽现已超越了100GB/s,而ARM还在为10GB/s而苦苦斗争,一个愈加吃带宽的架构,带宽却只需他人的十分之一,功用天然会遭到非 常大的约束。为什么说ARM和X86欠好比,这也是很重要的一个原因,由于不同的运用对带宽需求是不同的。一旦遇到带宽瓶颈,哪怕ARM处理器现已到达了 很高的运算功用,实践上底子发挥不出来,天然也就会落败了。
提到这儿咱们应该也现已了解CISC和RISC的差异和特征了。简而言之,CISC实践上是以添加处理器自身杂乱度作为价值,去交换更高的功用,而 RISC则是将杂乱度交给了编译器,献身了程序巨细和指令带宽,交换了简略和低功耗的硬件完结。但假如作业就这样开展下去,为了提高功用,CISC的处理 器将越来越大,而RISC需求的内存带宽则会打破天边,这都是遭到技能约束的。所以进十多年来,关于CISC和RISC的差异现已渐渐的在含糊,例如自 P6体系(即Pentium Pro)以来,作为CISC代表的X86架构引进了微码概念,与此对应的,处理器内部也添加了所谓的译码器,担任将传统的CISC指令“拆包”为愈加矮小 的微码(uOPs)。一条CISC指令进来今后,会被译码器拆分为数量不等的微码,然后送入处理器的履行管线——这实践上能够了解为RISC内 核+CISC解码器。而RISC也引进了指令集这个就逻辑视点而言十分不精简的东西,来添加运算功用。正常而言,一条X86指令会被拆解为2~4个 uOPs,均匀来看便是3个,因而相同的指令密度下,现在X86的实践指令履行才干应该大约是ARM的3倍左右。不过不要忘了这是根据“相同指令密度”下 的一个假定,实践上X86能够到达的指令密度是十倍乃至百倍于ARM的。
3>选用不同指令集
最终一个需求考虑的当地便是指令集。这个东西的引进,是为了加快处理器在某些特定运用上功用而规划的,现已有了几十年的前史了。而实践上在现在的运用环境 内,起到决议作用的许多时分是指令集而不是CPU中心。X86架构的强壮,许多时分也源于指令集的强壮,比方咱们知道的ATOM,尽管它的X86中心十分 瘦弱,可是由于它支撑SSE3,在许多时分功用乃至能够超越中心功用远远强壮于它的Pentium M,这便是指令集的威力。现在X86指令集现已从MMX,开展到了SSE,AVX,而ARM仍然还只需简略而根底的NEON。它们之间不成比例的间隔形成 了实践运用中成百上千倍的功用落差,例如即便是如今最强壮的ARM内核仍然还在为软解1080p H.264而斗争,但一颗一般的中端Core i处理器却能够用挨近十倍播映速度的速度去紧缩1080p H.264视频。至少在这点上,说PC处理器的功用百倍于ARM是无可辩驳的,而实践中这样的比方举目皆是。这也是为什么我在之前说均匀下来ARM只需 X86几十分之一的功用的原因。
打了这么多字,其实便是为了阐明一点,尽管现在ARM很强壮,但它间隔X86仍是十分悠远,并没有由于这几年的前进而缩短,实践上反而在被更快的拉大。毕 竟它们规划的起点不一样,因而底子不具有多少可比性,X86无法做到ARM的功耗,而ARM也无法做到X86的功用。这也是为什么ATOM一直以来都不 成功的原因地点——Intel试图用自己的矮处去和他人的利益对立,成果天然是不太好的,要不是Intel具有这个星球上最先进的半导体工艺,ATOM根 本都不或许呈现。而ARM假如测验去和X86拼功用,那成果天然也好不到哪儿去,原因刚刚也解说过了。不过这也不意味着ARM今后就只能占有低端,究竟任 何架构都有其长处,一旦有运用针对其进行优化,那么就能够取长补短。X86的昌盛也正是由于整个国际的资源都针对它进行了优化所形成的。只需能为ARM找到合 适的运用与合适的范畴,未来ARM也未必不能够进入更高的层次
4>寻觅办法不同
寻址办法也不一样,这个就得看各个架构的reference manual了。这方面一个比较大的差异是x86运用了分段(实践上在linux中,绕过了分段形式,可是cpu确实是分段的),而arm是分页。
至于是否冯诺依曼或许哈佛,这个没有太多争辩的必要,现在为止我所触摸过的朴实哈佛结构的只需51系列的单片机。在arm9以上的带独立 icache/dcache的cpu中,从cache的视点来看确实是哈佛结构的,由于icache和dcache和外部总线的接口是截然别离的,而从实 际的外部总线体系规划来看,你仍然能够以为是冯诺依曼的,由于代码和数据共用了外部的amba总线,而且都在一个地址空间中,并没有真实别离。这样的规划关于当时的操作体系来说是最合理,最便利的
三.ARM和X86功耗不同:
ARM和X86功耗的不同一直是个很热的论题.ARM能够做的很低,乃至1瓦都不到.而X86服务器的芯片能够到达100-200瓦,就算是嵌入式处理器 Atom系列也需求几瓦.许多人说这是指令集的联系.ARM选用精简指令集,X86选用杂乱指令集,前者每条功用简略,单挑指令耗电低.而后者每条指令复 杂,单个指令耗电高.可是这种解说很含糊.假如咱们都做相同的作业,完结一个大功用,精简指令集需求指令较多,而杂乱指令集需求指令少,加起来究竟谁耗电 多呢.还有,现在处理器遍及选用微指令,大的指令会被拆分红更小的指令,以到达更高的流水线功率.简略指令集的单条微指令和杂乱指令集的单条微指令比较的 话,状况就更杂乱.我手头没有关于比较的详细数据,可是至少前文所列出关于功耗和指令集相关的解说不是很有说服力.
今日碰到一个资深人士,总算找到一个比较合理的解说.
首要,功耗和工艺制程相关. ARM的处理器,不管是哪家,首要是靠台积电等专业制作商出产的.而Intel的是自己的工厂制作的.一般来说后者比前者的工艺抢先一代,也便是2-3 年.假如相同的规划,造出来的处理器因该是Intel的更紧凑,比方一个是22纳米,一个是28纳米,相同功用必定是22纳米的耗电更少.
那为什么反而ARM的比X86耗电少得多呢.这就和别的一个要素相关了,那便是规划.
规划又分为前端和后端规划,前端规划表现了处理器的构架,精简指令集和杂乱指令集的差异是经过前端规划表现的.后端规划处理电压,时钟等问题,是耗电的直接要素.
先说下后端怎样影响耗电的.咱们都学过,晶体管耗电首要两个原因,一个是动态功耗,一个是漏电功耗.动态功耗是指晶体管在输入电压切换的时分发生的耗电, 而一切的逻辑功用的0/1切换,归根到底都是时钟信号的切换.假如时钟信号坚持不变,那么这部分的功耗就为0.这便是所谓的门控时钟(Clock Gating).而漏电功耗能够经过关掉某个模块的电源来操控(Power Gating).当然,其间任何一项都会使得时钟和电源所操控的模块无法作业.他们的差异在于,门控时钟的康复时刻较短,而电源操控的时刻较长.此外,如 果条单条指令运用多个模块的功用,在康复功用的时分,并不是最慢的那个模块的时刻,而或许是几个模块时刻相加,由于这牵涉到一个上电次第(Power Sequence)的问题,也便是康复作业时分模块间是有先后次第的,不遵循这个次第,就无法康复.而遵循这个次第,就会使得总康复时刻很长.所以在后端 这块,能够得到一个定论,为了省电,能够封闭一些暂时不会用到的处理器模块.可是也不能简单的封闭,不然一旦需求,康复的话会让完结某个指令的时刻会很 长,全体功用明显下降.此外,子模块的门控时钟和电源开关一般是规划电路时就决议的,关于操作体系是通明的,无法经过软件来优化.
再来看前端.ARM的处理器有个特色,便是乱序履行才干不如X86.换句话说,便是用户在运用电脑的时分,他的操作是随机的,无法猜测的,形成了指令也无 法猜测.X86为了增强对这种状况下的处理才干,加强了乱序指令的履行.此外,X86还增强了单核的多线程才干.这样做的缺陷便是,无法很有用的封闭和恢 复处理器子模块,由于一旦封闭,康复起来就很慢,然后形成低功用.为了坚持高功用,就不得不让大部分的模块都坚持敞开, 而且时钟也坚持切换.这样做的直接结果便是耗电高.而ARM的指令强在确认次第的履行,而且依托多核而不是单核多线程来履行.这样简单坚持子模块和时钟信 号的封闭,明显就更省电.
此外,在操作体系这个等级,个人电脑上一般会开许多线程,而移动渠道一般会做优化,只坚持必要的线程.这样使得耗电间隔进一步加大.当然,假如X86用在 移动渠道,必定也会由于线程少而省电.凌动系列(ATOM)专门为这些特性做了优化,在必定程度上下降乱序履行和多线程的处理才干,然后到达省电.
此外,现在移动处理器都是片上体系(SoC)结构,也便是说,处理器之外,图形,视频,音频,网络等功用都在一个芯片里.这些模块的翻开与封闭就简单猜测 的多,而且能够经过软件来操控.这样,全体功耗就愈加取决于软件和制作工艺而不是处理机结构.在这点上,X86的处理器占优势,由于Intel的工艺有很 大优势,而软件优化只需去做必定就能够做到.
以上原因我觉得较好的解说了ARM和X86的功耗不同.