本文列举了多核嵌入式体系存在的一些首要约束,并对处理这些约束的可行计划进行了评论。将以一些嵌入式体系为例,指出使用现有架构改善体系节能效果的时机。多核处理器与新式的嵌入式渠道的结合能够满意现代嵌入式使用所需的高核算才能。可是,此类嵌入式使用需求进行高频切换,这将导致功耗较大、芯片温度过高,以及电源接地噪声。开发人员能够经过本文找出改善现代嵌入式体系节能效果的时机,并了解完结电源功率最大化的可行计划。
多核处理器的自主节能
本文以甲骨文(Oracle)/SunMicrosystem公司的UltraSPARC T1处理器为例打开论说。图1所示为一款UltraSPARC T1多核嵌入式处理器中的一个硬件线程的流水线微架构。挑选UltraSPARC T1的原因是,其规划源代码、仿真东西及规划验证套件均为开源,并且能够从Oracle公司网站上下载。本文将使用此事例评论从哪方面以及经过何种办法完结节能。

图1:Ultra-SPARC T1嵌入式处理器的流水线微架构。
图2显现了与处理器每个内核相关的圈套逻辑单元。圈套完结了软件从初级到高档特权形式(例如从用户形式到办理或监督形式)的操控矢量传递。就UltraSPARC T1处理器而言,Tcc指令以及因指令引起的反常、复位、异步过错或中止恳求均会导致圈套的产生。
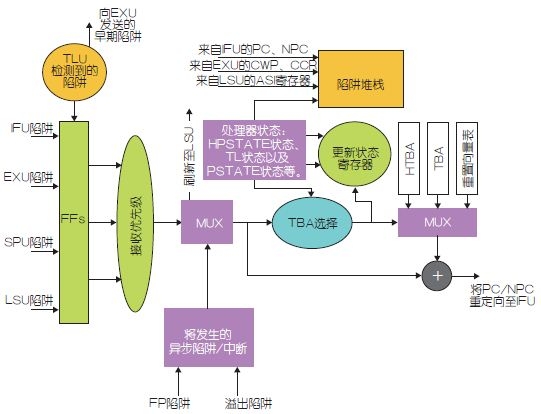
图2:圈套逻辑单元。
一般,圈套会导致SPARC流水线被冲刷(Flush)。处理器状况将被存储在圈套寄存器仓库中,而圈套处理程序代码则将被履行。操控的实践传递是经过含有每个圈套处理程序前八个指令的圈套表来完结的。用于将圈套传递到特权形式中的表格的虚拟基址在圈套基址(TBA)寄存器中被指定。表格中的位移则取决于圈套的类型和当时的圈套等级。当遇到DONE(完结)或RETRY(重试)指令时,圈套处理程序代码履行结束。圈套或许与SPARC内核流水线同步或异步。图2显现了与SPARC内核其他硬件模块相关的TLU中的圈套操控和数据流。从IFU、EXU、LSU及TLU传入的圈套的优先级最早被解析,解析的圈套类型被确认。依据圈套类型,以及在行列中没有其他更高优先级的中止或异步圈套待处理的情况下,体系将向LSU发送冲刷信号,以提交之前未完结的一切指令。此外,圈套类型也决议了什么样的处理器状况寄存器需求被存储到圈套寄存器仓库中。之后,将挑选圈套基址并将其发往流水线做进一步履行。
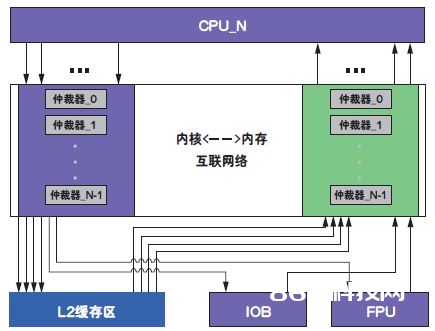
图3:芯片框图。
图3显现了多核嵌入式处理器的芯片布局。该处理器有可变数量的内核、L2缓存体(bank)、内核外浮点单元(FPU)及输入输出逻辑,并且它们经过芯片上的网络互连。在CASPER仿真环境中,规划师能够对各种架构参数进行修正。
节能时机
关于上述多核嵌入式处理器,已确认了以下内核级和芯片级节能候选元素(PSC):
1.寄存器文件,即线程专用单元。每个线程都有一个160双字(64位)的寄存器文件,并且当线程的某个使命被堵塞或空转时能够节约很多功耗。
2.数据缓存未射中时,用以摆放数据的加载未射中行列(LMQ)。线程之间能够同享加载未射中行列,但经过这种办法节约的功耗较少。
3.分支预测器。分支前史表能够是线程专用的,因而能够节约很多功耗。
4.当内核中一切线程的一切使命产生堵塞或闲暇时,或没有使命被调度到内核中的任何线程时,整个内核能够节约很多功耗。
5.内核中用于硬件和软件中止的圈套单元。研讨结果显现,在UltraSPARC T1处理器中,用于典型SPECJBB网络处理使用的圈套指令在一切指令中所占的百分比还不到1%。这表明,圈套单元是非常好的潜在节能元素。请注意,虽然在大部分时间内其他的圈套逻辑或许处在节能形式下,接纳圈套的输入接纳行列需一向保持在活泼状况,但行列的功耗能够忽略不计。
6.在缓存体和输入输出缓冲器之间操控数据流的用于L2缓存的DMA操控器。
7.内核和L2缓存体之间的指令和数据行列。
8.当需求拜访片外缓存或主存储器时,只要在片上L2缓存有缓存未射中时才会被激活的缓存未射中途径逻辑。
节能战略
依据上述PSC拟定出的自主硬件节能计划包含电源门控(数据不被保存)、时钟门控(数据在正常操作时被保存)和DVFS(同步电压及频率调整)。DVFS仅用于整个内核,或类似于DMS操控器、互连网络、缓存体、输入输出缓冲器或FPU的片上核算单元这样的一个芯片级组件(图3)。可是,关于内核中的组件和芯片级组件而言,电源和时钟门控均适用。图4显现了引荐的核内(部分电源办理)级和大局芯片级分层节能架构。在图4中的虚线上方,部分电源办理单元在内核中运转,对电源状况寄存器(PSR,与不同的PSC相关)中的内容进行监控,履行节能算法,以及对相应电源操控寄存器(PCR)傍边的数值进行修正以激活或封闭节能形式。片上模仿电压调节器和时钟调节器将读取PCR中的内容,并经过读取的数据对PSC上的DVFS、电源门控、时钟门控进行操控。请注意,LPMU并不直接操控整个内核中的节能单元(如DVFS)。反之,LPMU将经过内核操控状况寄存器(CSR)向大局电源办理单元(GPMU)发送信号,CSR转而经过内核操控寄存器(CCR)完结内核级节能。内核中的电源状况寄存器经过圈套逻辑和解码器进行更新,当需求进行特定中止服务或要对特定指令进行解码时,圈套逻辑和解码器将会宣布PSC行将激活的信号。相同,PSC也能够对本身的PSR进行更新,然后在体系长期不作业(闲暇或堵塞状况,最好在内核中对其进行部分监控)时宣布行将节能的信号。
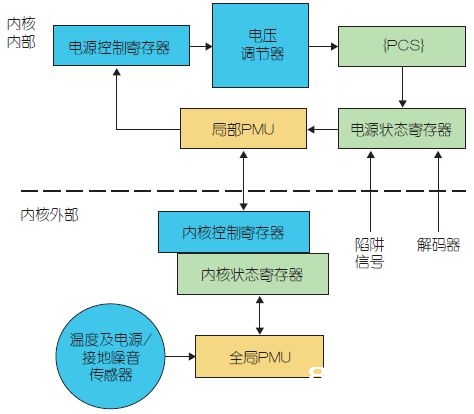
图4:自主硬件节能逻辑的架构。
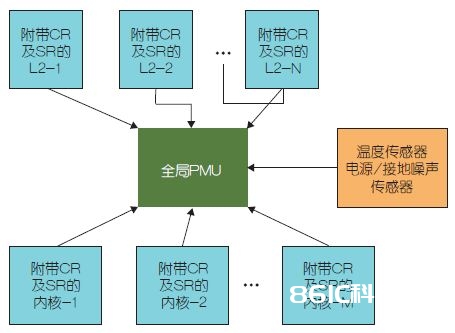
图5:大局电源办理单元。
在图4中的虚线下方及内核外部是芯片级GPMU,它将会读取片上传感器上热门和电源接地噪声(它们是大局可观测现象)的数据,并为内核及其他芯片级组件做出相应的智能节能决议。GPMU经过内核状况寄存器(CSR)和内核操控寄存器(CCR)与内核及其他组件进行交互。整个内核的电源门控、时钟门控以及DVFS经过GPMU进行操控。图5展现了GPMU的交互(CR和SR别离表明操控寄存器和状况寄存器)。请注意,本文在逻辑大将一切芯片级组件都视为内核。
事例研讨:英特尔迅驰中的节能
英特尔迅驰双核处理器(Core Duo)部分选用了自主电源办理计划,它是英特尔公司针对移动商场开发的首款通用芯片多处理(CMP)商用嵌入式处理器。这种内核可完结两个首要方针:首要,在渠道所能接受的最高温度下完结功能的最大化;其次,电池的续航才能比前几代处理器更强。
操作体系将英特尔双核处理器视为两个独立的履行单元,但在与电源办理相关的一切操作中,渠道则将整个处理器视为单一实体。英特尔挑选将内核电源办理与整个CPU和渠道的电源办理分隔。为了完结这个方针,有必要让电源及温度操控单元成为内核逻辑单元的一部分,而不是像以往那样作为芯片组的一部分。将电源及温度办理数据流迁移至处理器后,就能够选用一种答应一切内核依据本身需求恳求节能状况的硬件和谐机制,然后最大化单个内核的节能效果。CPU将依照两个内核恳求中的最低标准确认并进入相应的节能状况,例如芯片组电源办理硬件和数据流的单一CPU实体。由此,软件能够依照ACPI协议对每个内核独自进行办理,而实践的电源办理则恪守渠道和CPU的同享资源约束条件。多核处理器内核之间的相关性较杂乱,内核对体系级参数的效果还不确认,并且ACPI电源办理协议也不是针对如此杂乱的多核处理器而开发的。因而,需求开发一种新式的电源办理计划,这样的计划有必要能在新式的多核嵌入式处理器中将硬件节能逻辑和由操作体系操控的调度更好地整合到一同。
英特尔推出的双核处理器被分割成三个域。内核、各内核的一级缓存以及部分温度办理逻辑单元作为电源办理域独立运转。此外,包含二级缓存、总线接口及中止操控器在内的同享资源构成另一个电源办理域。一切域将同享同一个电源平面和同一个单核PLL,因而均在相同的频率和电平下运转。与细粒度节能计划比较,这是一个根本约束。可是,每个域都有独立的时钟分配(骨干(spine))。内核的时钟散布主线独自进行门控,然后完结最根本的内核级节能计划。只要在两个内核都处在闲暇状况且没有同享操作(总线操作和缓存拜访)的情况下,才能对资源同享骨干进行门控。若需求,即便在两个内核的时钟都中止的情况下,也能够将资源同享时钟保持在活泼状况,以便进行L2侦听和中止操控器信息剖析。英特尔Core Duo技能还引入了包含L2动态调整在内的增强型电源办理特性。为了完结节能,体系有必要进入更低电压的闲暇状况,而为了到达这一意图,有必要动态地调整/封闭L2缓存,然后为DeepC4状况做准备。