


摘要:介绍了契合CCSDS规范的RS(255,223)码译码器的硬件完结结构。译码器选用8位并行时域译码算法,首要包括了修正后的无逆BM迭代译码算法,钱查找算法和Forney算法。选用了三级流水线结构完结,减小了译码器的时延,进步了译码的速率,运用了VHDL言语完结译码器的规划与完结。测验标明,该译码器功用优秀,适用于高速通讯。
要害词:RS码;FPGA;译码器;有限域;改善的BM算法
在数字通讯中,信号在有噪信道中传输,不行避免的会遭到噪声的搅扰,引起误码。在已知信噪比的情况下要到达必定的误码率目标,在合理规划基带信号,挑选调制解调办法,及时域均衡或频域均衡的基础上,运用过失操控技能能够使误码率进一步的下降。RS码归于分组码,是BCH码的一个子类,是最大间隔可分码,它是由Reed和Solomon于1960年结构出来。因为它具有很强的纠正随机过错和突发过错的才能,以及极低的不行勘探的过失率,所以RS码现已广泛运用于深空通讯、卫星通讯、存储介质、数字视频播送和扩频数字通讯中。
在一些特定运用域中,RS码的规划和完结是比较困难的,RS码是在有限域上进行的代数运算,不同于常用的二进制体系,实践相对杂乱一些,其杂乱度首要决定于有限域的巨细、码字的长度,选用的编码算法等。FPGA能够快速和经济的将电路描绘转化为硬件完结,而且对规划的修订也比较便利。文中运用VHDL言语规划了RS(255,223)译码器,并经过了PFGA芯片上的验证。整个规划选用流水线结构,进步译码器的数据吞吐量,一起对电路结构进行优化,削减体积和时延,十分有利于细小卫星中运用。
1 RS码译码原理及完结
1.1 RS(255,223)码的参数
RS(255,223)是在有限域GF(28)上钩算得到的,其详细参数为:
1)每个符号的bit数:m=8;
2)每个码字包括的符号个数:n=28-1=255;
3)每个码字包括的信息位的符号个数:k=223;
4)码字中校验位的符号个数:2t=255-223=32;
5)一个码字所能纠错的最大符号数:t=16;
6)GF(28)域的来源多项式:f(x)=x8+x7+x2+x+1;
7)生成多项式:
1.2 RS码译码原理
RS译码算法有两类:时域译码和频域译码。在实践工程中,因为RS码符号一般取自有限域GF(28)上,选用时域体系码编码办法,体系码编码办法可较简略缩短,满意工程运用的需求。如图1所示,RS码时域译码器首要分为四个模块:随同式核算模块、过错方位多项式核算模块、钱查找模块、过错值计模块。其间过错方位多项式核算选用修正后的无逆BM迭代算法,过错值核算选用Forney算法,还需求一个FIFO来
缓存所承受的码字,使与经过译码后核算出的过错值同步。
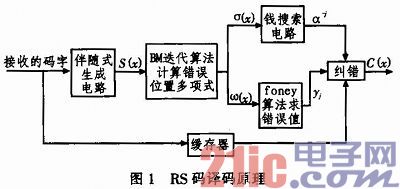
RS码时域译码的一般过程为:
1)依据接纳的码字核算随同式,假如核算出来的2t个随同式都等于0,那么表明接纳的码字没有过错,不再进行下面的过程,不然进行下面的过程;
2)运用核算好的随同式核算过错方位多项式和过错值多项式;
3)核算过错方位和过错值;
4)依据核算的过错方位和过错值可得到过错多项式E(x),将接纳的码字R(x)与E(x)相加,即可译码。
1.2.1 域内加法器和乘法器
有限域GF(2m)中的元素都能够用二元域GF(2)中的元素的m重来表明,域中的恣意元素都能够用次数小于m的多项式表明,加法和乘法运算是有限域GF(2m)中最简略的运算。
有限域上的加法比较简略,只需求对m维并行数据进行异或即可。
有限域上的乘法一般认为是时延较大,结构杂乱的运算操作。有限域的乘法器,即关于域内的恣意两个元素,能够用m-1次多项式来表明,这样两个元素的乘积为2m-2次多项式,再把乘积对有限域的来源多项式求余,所得的成果即为两个元素的乘积。文中的乘法器是选用八位并行与门和异或门来完结的,这种有限域乘法器的规划充分运用了特征为2的有限域元素的加减法运算即为异或运算的特征,大大简化了规划,一起也使算法描绘更简略,且简略完结。
1.2.2 核算随同式模块
BS(255,223)译码的第一步就是核算2t个随同式Si: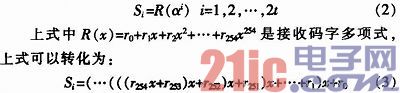
其完结结构如图2所示,在初始阶段,寄存器被清零,输入第一个码字(接纳的码字高位)在与零相加后被送入寄存器,再乘以与第二个输入的码字相加,如此循环,直到255个码字悉数进去寄存器经过核算后,寄存器内的值就是咱们需求的随同式Si。
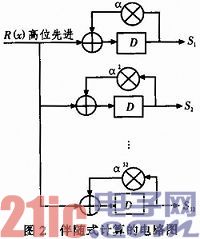
1.2.3 修正后的无逆BM迭代算法模块
求解要害方程是解码器完结中最杂乱和占用资源最多的模块,其意图是为了求出过错方位多项式σ(x),根是过错方位的t次多项式:

关于求解要害方程的算法的已有许多,例如,Euclid算法,非二进制的BM算法等。文中选用修正后的无逆BM迭代算法完结。传统的BM迭代译码算法,每次迭代都有一个求逆的运算,求逆是比较杂乱且对硬件要求高的算法。无逆BM迭代算法避免了进行繁琐耗时的求逆运算,可是迭代过程中只核算了过错方位多项式,最终还需求依据要害方程和得到的过错方位多项式来求的过错值多项式,这样也增加了译码的时延。改善后的无逆BM迭代算法,在核算了过错方位多项式的一起也核算了过错值多项式,削减了时钟的损耗,进步了译码的速率。详细完结流程如图3所示。

图3中λ(x)是核算过错方位多项式σ(x)的辅佐多项式,α(x)是核算过错值多项式ω(x)的辅佐多项式,k为迭代的次数,δ为前一次迭代和这次迭代的修正项。
1.2.4 钱查找和Forney算法模块
过错方位多项式σ(x)和过错值多项式ω(x)确认后,过错方位能够经过求解过错方位多项式的根求得的,工程上用的最多的是钱查找算法。译码器经过钱查找算法查看当x=α0,α1,…,αn时,代入过错方位多项式σ(x)中,若σ(αi)=0,则表明αi为犯错的方位。
运用Forney算法能够求得过错方位上的过错值,在已求得过错方位多项式和过错值多项式前提下:


在完结过程中,钱查找和Forney算法是在一个模块中完结的。对αi进行钱查找的一起,也把αi输入Forney算法完结结构中,选用流水线结构,这样能够削减时钟周期,经过t+1个时钟后即能够输出第一个纠错后的成果。结构如图4所示,σ0,σ1,…,σ16别离表明σ(x)的系数,ω0,ω1,…,ω16表明ω(x)的系数,x1,…,x16表明αi,…,α16i,关于求σ’(x)时,中心需求等一个时钟,流水线结构必定要注意同步,错开一个时钟都会发生过错。这部分有一个求逆的运算,本文中的求逆运算是用的查表法完结的,查表法的基本思想是GF(28)域上的元素的逆元先核算出来存储到ROM中,将待求逆元作为读取ROM的地址,读出ROM的存储值,该值就是所求成果,这种办法的核算速度十分快。运用这种结构进步了译码的速率。
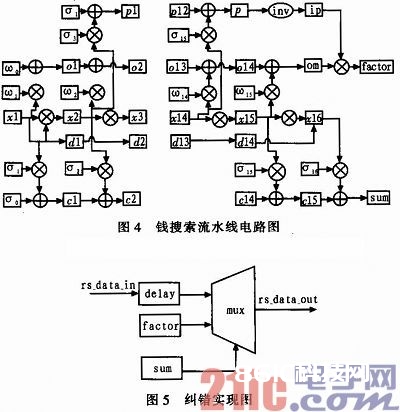
1.2.5 纠错模块
当确认可误码的方位及详细的误码值后,也就确认了过错多项式,将得到的过错多项式与接纳多项式相加,即完结误码的纠正。
![]()
纠错的硬件完结结构如图5所示,是一个二选一的多项挑选器,假如代入过错方位多项式后得到的值为0,那么需求将接纳值与核算得到的过错值相加,假如不等以0,则直接输出接纳值。接纳码字需求经过一个缓存器,这样接纳值才能与经过译码算法输出的过错值同步,到达纠错的意图。
2 FPGA完结及测验成果
运用上文提出的硬件完结结构结构,选用VHDL输入,在FPGA上完结了RS(255,223)码的接连译码,运用了XilinxISE10.1编译,选用了xc4vsx55芯片归纳,Slice个数为5 209个,占用芯片总数的21%,最高速率到达了149.836 MHz。经过Modelsim6.2验证,选用了三级流水线结构,译码所需时钟周期为255+2*t+2+t+1,文中译码器的时钟周期为306个时钟。

仿真选用时钟为100 M,将正确的编码后的码字人为的输入16个接连过错和16个涣散过错,发动仿真,由波形中引出核算的所得的过错值和相应的过错方位,16个过错均得到了纠正。由图6能够看到输入信号rs_data_in,人为的将27—42改为30、35、128、60、167、250、75、43、108、89、135、40、79、191、2、9。由图7能够看到输出信号rs_data_out,过错的数据现已得到了纠正,验证了译码器的正确性。
3 结束语
文中完结了RS码时域译码器结构,依据该结构完结了符号取自有限域GF(256)上的RS(255,223)码译码器。这种RS码译码器硬件完结结构具有功用模块化、结构规则化的特色,选用了流水线结构,最大极限进步译码数据的吞吐量,进步了译码速度,适用于高速通讯。而且在此基础上只需进行少数更动就能够较简略完结其它码型的译码器,该计划已运用于多个军事通讯设备中。






