


摘要:根据FPGA硬件技能,以资源和时刻相结合的思路,提出了一种串并结合的比较排序算法。该算法经过对数据的分时并行比较,核算出每个数据在排序中的方位完结数据排序。该算法可在较短的时刻内完结数字序列的排序,经过试验证明,资源耗费少,实时性号,通用性强。
关键词:排序;FPGA;并行;串行
在雷达抗干扰处理以及空时二维处理进程中数据排序将必不可免,在传统的DSP、CPU等惯例软件排序现已不能够满意雷达体系实时性要求,运用 FPGA排序的趋势将势不可当。FPGA因为具有较高的并行处理才能,现在已成为雷达阵列信号处理中的干流处理器材。核算耗费的时刻和耗费的硬件资源成为 处理的首要对立,怎么处理这个对立,自己将提出处理方案。
1 算法描绘与剖析
排序便是将数据元素的一个恣意序列,从头排列成一个按关键字有序的序列。各种传统串行排序算法如冒泡,大多都是以两两之间次序比较为根底,不能满意 实时性要求。假如将传统的串行排序在FPGA中进行分段串行排序再排序,能够削减排序时刻,但却大大添加规划难度。本文提出根据并行比较思路,经过将逻辑 比较成果求和,用此和值确认排序成果的方位,然后到达完结排序成果的意图。
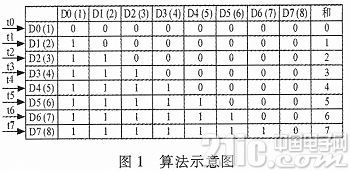
假定待排序数据元素个数为N,全并行比较便是在同一时刻将N个数两两比较,再在下一时刻进行累加求和以确认排序成果。这样需求耗费N*N个比较器,假如元素个数较多,将耗费很多逻辑资源。本算法选用N个比较器,用N倍时刻完结比较。算法如上图所示。
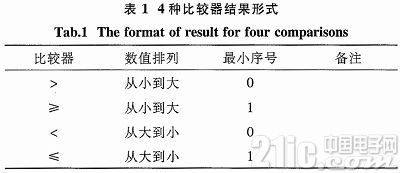
不同的比较器将有不同的比较成果输出,下表列出了4种比较器输出成果方式。
2 工程完结
排序算法在FPGA内进行,整个完结进程如下图。运用verilog言语规划,做到模块化、参数化,以习惯不同数量的排序以及各自逻辑资源的操控,首要有以下几步:
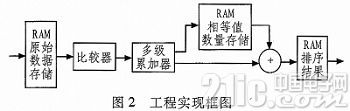
1)将流水线上的待排序的Ⅳ个数据存储到RAM中,一起对相等值数量的RAM写零;
2)读取N个赋给N个变量预备比较;
3)读取数据和N个变量一起比较;
4)将比较成果累加求和;
5)将和值作为地址读取此数据的个数,将此个数和累加和相加写到排序成果RAM中,一起将个数加1写入相等值数量的RAM中。
相等值数量RAM首要处理待排序数据流有过个相同数值巨细的数据排序的状况。
读取N个赋给N个变量预备比较需求N个时钟周期,比较需求N个时钟周期,多级累加需求3*N个时钟周期(N≤512),相同数值排序需求3*N个时钟周期,算计需求8*N个时钟周期。
3 仿真与验证
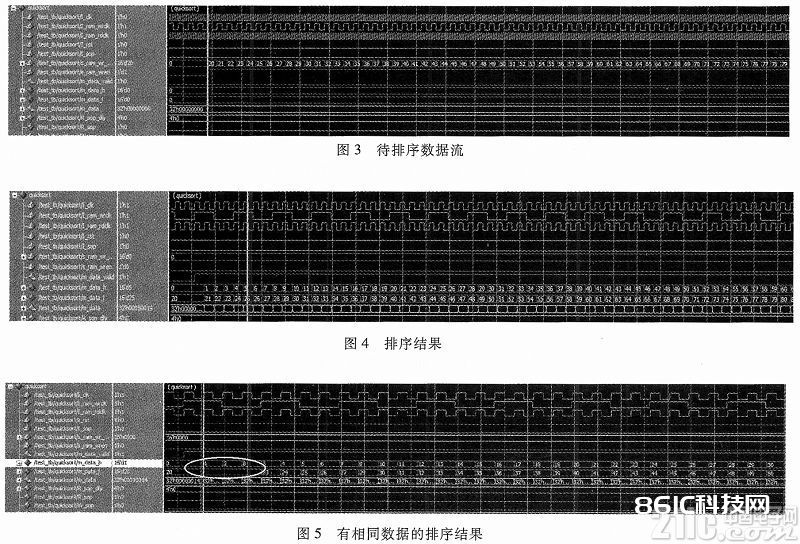
本算法Verilog代码以及IP核模块的新建根据Xilinxvp690,功用级仿真在Modsim中完结。图3是待排序数据流截图,待排序数据 是从20到319的300个递加数据,图4是图3输入数据的从小到大的排序成果,其间m_data_h是是排序后原先数据的序号,m_data_l是排序 后从小到大的成果;为了验证相同数值的排序状况,将上述待排序数据的第2、39个数改成和第1个数相同,即20,再排序,其成果如图5所示,圆圈标出了相 同数据及相同数据的排序成果。
4 算法在工程运用中的功用剖析
经过实践树立工程,归纳、仿真剖析别离得出128点、256点以及512点排序,别离运用全并行算法、串行(冒泡)算法和本文串并结合的算法得到的 逻辑资源运用状况以及运算时钟周期。从表中能够看出,全并行算法速度最快,但数据点数翻倍时耗费的资源耗费平方级翻倍,256点排序现已超出了芯片的范 围;串行冒泡算法耗费的资源较少,但数据点数翻倍时耗费的时刻却是平方级翻倍;只要本文提出的算法耗费的资源和时钟周期都能接纳,具有可行性含义。

选用240 MHz时钟,512点排序,只需求8μs。
5 结束语
排序在雷达信号处理进程中仅仅其间的一个功用,这要求咱们逻辑资源不能耗费太多,而雷达的实时性要求又要求咱们有必要快速的完结排序。从上述论说可 知,单纯的串行和并行排序都不能满意要求,只要本文这种根据FPGA技能的串并行结合处理排序算法才能够满意实践工程要求,到达了实时排序的作用。该算法 具有通用性,能够运用到各种数据快速排序运算范畴。





