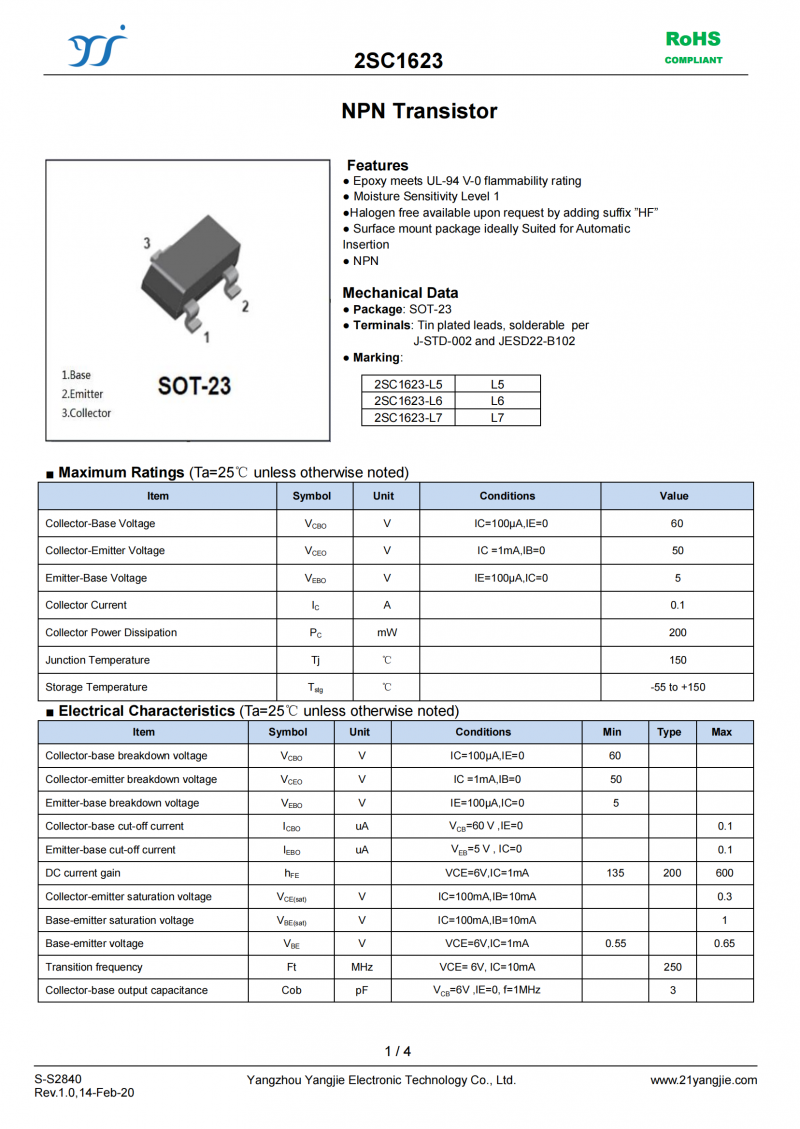
深度学习概述
o 受限玻尔兹曼机和深度信仰网络
o Dropout
o 处理不平衡的技巧
o SMOTE :组成少量过采样技能
o 神经网络中对本钱灵敏的学习
深度学习概述
在 2006 年之前,练习深度监督前馈神经网络总是失利的,其主要原因都是导致过度拟合,即练习过错削减,而验证过错添加。
深度网络一般意味着具有多于 1 个躲藏层的人工神经网络。练习深层躲藏层需求更多的核算才能,具有更深的深度好像更好,由于直觉神经元能够运用下面图层中的神经元完结的作业,然后导致数据的散布式标明。
Bengio 以为躲藏层中的神经元可被看作是其下面的层中的神经元所学到的特征检测器( feature detector )。这个成果处于作为一个神经元子集的更好泛化( generalization )中,而这个神经元子集可从输入空间中的特定区域的数据上进行学习。
而且,由于相同功用所需的核算单元越少,功率就越高,所以更深的架构能够更高效。散布式背面的中心思维是同享核算优势,将不同架构的组件重用于不同的意图。
深度神经架构是由多个运用非线性操作的层组成的,例如在带有许多躲藏层的神经网络中。数据会集常常存在各种改变的要素,例如数据各自的性质常常或许独登时改变。
深度学习算法能够获取解说数据中的核算改变,以及它们怎么相互作用以生成咱们调查到的数据类型。较低层次的笼统更直接地与特定的调查联络在一起,另一方面,更高层次的更笼统,由于他们与感知数据的联络愈加偏僻。
深度架构学习的重点是主动发现从初级特征到更高等级概念的笼统。算法能够在不需求手动界说必要笼统的情况下启用发现这些界说。
数据会集的练习样本的多样性有必要至少与测验会集的相同多,不然算法就不能混为一谈。深度学习办法旨在学习特征层次结构,将更低层次的特征组组成更高层次的笼统。
具有许多参数的深度神经网络是十分强壮的机器学习体系。可是,过度拟合在深度网络中是一个严峻的问题。过度拟合是指当验证过错开端添加而练习过错下降时。 Dropout 是处理这个问题的正则化技能之一,这将在后面评论。
今日,深度学习技能取得成功的最重要要素之一是核算才能的进步。图形处理单元( GPU )和云核算关于将深度学习应用于许多问题至关重要。
云核算答应核算机集群和按需处理,经过并行练习神经网络来协助削减核算时刻。另一方面, GPU 是用于高性能数学核算的专用芯片,加快了矩阵的核算。
在 06-07 这一年,三篇论文彻底改变了深度学习的学科。他们作业中的要害原则是每层都能够经过无监督学习进行预先练习,一次完结一层。最终,经过差错反向传达的监督练习微调一切层,使得这种经过无监督学习进行的初始化比随机初始化更好。
受限玻尔兹曼机和深度信仰网络
其间有一种无监督算法是受限玻尔兹曼机( RBM ),可用于预练习深层信仰网络。 RBM 是波尔兹曼机的简化版别,它的规划创意来自于核算力学,它能够模仿给定数据集的根本散布的依据能量的概率,从中能够得出条件散布。
玻尔兹曼机是随机处理可见单元和躲藏单元的双向衔接网络。原始数据对应于 ' 可见 ' 神经元和样本到调查状况,而特征检测器对应 ' 躲藏 ' 神经元。在波尔兹曼机中,可见神经元为网络和其运转环境供给输入。练习进程中,可见神经元被胁迫(设置成界说值,由练习数据确认)。另一方面,躲藏的神经元能够自在操作。
可是,玻尔兹曼机由于其连通性而十分难以练习。一个 RBM 约束了连通性然后使得学习变得简略。在组成二分图( bipartite graph )的单层中,躲藏单元没有衔接。它的优势是躲藏单位能够独立更新,而且与给定的可见状况平行。
这些网络由确认躲藏 / 可见状况概率的能量函数操控。躲藏 / 可见单位的每个或许的衔接结构( joint configurations )都有一个由权重和差错决议的 Hopfield 能量。衔接结构的能量由吉布斯采样优化,它可经过最小化 RBM 的最低能量函数学习参数。

在上图中,左层代表可见层,右层代表躲藏层
在深度信仰网络( DBN )中, RBM 由输入数据进行练习,输入数据具有躲藏层中随机神经元捕获的输入数据的重要特征。在第二层中,练习特征的激活被视为输入数据。第二个 RBM 层的学习进程能够看作是学习特征的特征 。 每次当一个新的层被添加到深度信仰网络中时,原始练习数据的对数概率上的可变的更低的边界就会取得提高。

上图显现了 RBM 将其数据散布转换为躲藏单元的后验散布
随机初始化 RBM 的权重,导致 p ( x )和 q ( x )的散布差异。学习期间,迭代调整权重以最小化 p ( x )和 q ( x )之间的差错。 q ( x )是原始数据的近似值, p ( x )是原始数据。
调整来自神经元和另一神经元的突触权重的规矩不依赖于神经元是可见的仍是躲藏的。由 RBM 层更新的参数被用作 DBN 中的初始化,经过反向传达的监督练习来微调一切层。
关于 KDD Cup 1999 的 IDS 数据,运用多模态( Bernoulli-Gaussian ) RBM 是不错的挑选,由于 KDD Cup 1999 由混合数据类型组成,特别是接连和分类。在多模 RBM 中是运用两个不同的通道输入层,一个是用于接连特征的高斯输入单元,另一个是运用二进制特征的伯努利输入单元层。今日咱们就不进行具体解说。
Dropout
最近的开展是想深度网络引进强壮的正规化矩阵来削减过度拟合。在机器学习中,正则化是附加信息,一般是一种赏罚机制被引进,以赏罚导致过度拟合的模型的复杂性。
Dropout 是由 Hinton 引进的深度神经网络的正则化技能,其包含经过在每一个练习迭代上随机关掉一部分神经元,而是在测验时刻运用整个网络(权重按份额缩小),然后避免特征检测器的共习惯。
Dropout 经过等同于练习一个同享权重的指数模型削减过拟合。关于给定的练习迭代,存在不同 dropout 装备的不同指数,所以简直能够必定每次练习出的模型都不相同。在测验阶段,运用了一切模型的均匀值,作为强壮的整体办法。

在上图中, dropout 随机放弃神经网络层之间的衔接
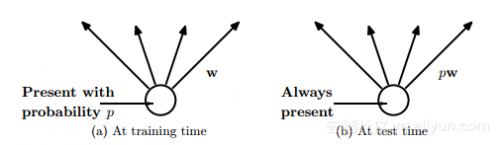
在上图中,衔接被丢掉的概率,一起在练习时刻中权重按份额缩小到 pw
在机器学习比赛中,均匀许多模型一般是许多机器学习比赛获胜者的要害,运用许多不同类型的模型,然后在测验时刻将其结合起来进行猜测。
随机森林是一个十分强壮的 bagging 算法,它是经过对许多决策树进行均匀而创立的,给它们供给了不同的练习样本集和替换。众所周知,决策树很简单习惯数据而且在测验时刻快速,因而经过给予不同的练习调集来均匀不同的独自树木是能够接受的。
可是,对深度神经网络运用相同的办法,在核算上是十分贵重。练习独自的深度神经网络和练习多个深度神经网络核算本钱现已很高了,然后均匀好像是不切实际的。此外,咱们需求的是在测验有用的单个网络,而不是有许多的大型神经网络。
Dropout 是均匀许多大型神经网络的有用办法。每次练习模型时,躲藏单元都能够省掉。因而,在测验时咱们应该运用权重折半的“均匀网络”模型。均匀网络等同于将 一切或许网络猜测的标签上概率散布的几许均匀值与单个躲藏的单位层和 softmax 输出层。
另一种看待 Dropout 的办法是,它能够避免特征检测器之间的共习惯( co-adaption )。特征检测器的共习惯意味着假如躲藏单元知道存在哪些其他躲藏单元,则能够在练习数据上与它们进行和谐。可是,在测验数据集上,复合和谐很或许无法混为一谈。
Dropout 也能够以一种较低的概率在输入层中运用,一般为 20 %的概率。这儿的概念和降噪主动编码器开展出的概念相同。在此办法中,一些输入会被遗失。这会对准确性形成损伤,但也能改善泛化才能,其办法类似于在练习时将噪声添加到数据会集。
在 2013 年呈现了 Dropout 的一种变体,称为 Drop connect 。它不再是以特定的概率权重放弃躲藏单位,而是以必定的概率随机放弃。试验成果现已标明,在 MNIST 数据集上 Drop connect 网络比的 dropout 网络体现的更好。
处理类别失衡的技巧
当一个类别(少量类)比较于其他类别(大都类)显着代表性缺乏的时分就会发生类别失衡问题。这个难题有着现实意义,会对误分类少量类形成极高的价值,比方检测诈骗或侵略这样的反常活动。这儿有多种技能能够处理类别失衡难题,如下面解说的这一种:
SMOTE :组成少量过采样技能
处理类失衡问题的一种广泛运用的办法是对数据集进行重采样。抽样办法触及经过调整少量集体和大都集体的先验散布来预处理和平衡练习数据集。 SMOTE 是一种过抽样的办法,其间经过创立“组成”示例而不是经过对替换进过行采样来对少量类别进行过采样。
现已有人提出说经过替换进行的少量类过采样不能明显改善成果,不如说它趋于过拟合少量类的分类。相反, SMOTE 算法在“特征空间”而不是“数据空间”中运转。它经过对少量类别进行过度抽样来创立组成样本,然后更好地推行。
这个主意的创意来自于经过对实在数据进行操作来创立额定的练习数据,以便有更大都据有助于推行猜测。
在此算法中第一个最近邻( neighbours )是为了少量类核算的。然后,就能够以下列办法核算少量类的组成特征:挑选最附近的一个随机数字,然后运用这一数字与原始少量类数据点的间隔。
该间隔乘以 0 和 1 之间的随机数,并将成果作为附加样本添加到原始少量类数据的特征向量,然后创立组成的少量类样本。
神经网络中本钱灵敏的学习
本钱灵敏性学习好像是处理分类问题的类不均衡问题的一种十分有用的办法。接下来咱们描绘特定于神经网络的三种本钱灵敏的办法。
在测验未见过的示例时,将该类的先验概率合并到神经网络的输出层中:
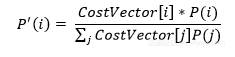
依据本钱调整学习率。应将更高的学习率分配给具有高误分类本钱的样本,然后对这些比如的权重改变发生更大的影响:
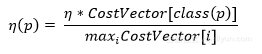
修正均方差错函数。成果是,反向传达进行的学习将最小化误分类本钱。新的差错函数是:

其本钱因子是 K[i , j] 。
这个新的差错函数发生一个新的增量规矩,用于更新网络的权重:

其间第一个方程标明输出神经元的差错函数,第二个方程标明隐层神经元的差错函数。