1 导言
转码运用触及视频服务器、通用多媒体拜访设备、监控体系、机顶盒、DVD等多媒体设备和体系。其根本原则是在环境和处理才干受限的情况下,在码流转化的质量和杂乱性之间获得最佳折衷。完结的关键是对紧缩视频码流中的紧缩数据进行复用,防止从头编码中的杂乱运算。研讨中的转码技能首要包括:码率转化、分辨率转化、帧率转化、语法转化等。
MediaCoder是现在比较优异的一款转码软件,它将很多来自开源社区优异的音视频软件整合于一个友爱的图形界面。它能够直接、批量地在很多音频视频紧缩格局和容器格局之间转化,支撑的格局包括H.264,Xvid,MPEG-1/2/4等,可是没有将AVS视频编码规范交融进来。本文介绍的软件解码器完结了H.264到AVS两个视频编码规范的转码。针对这两个规范的硬件转码器还在研制之中,上海龙晶微电子有限公司依据AVS规范提出了国内第一款具有彻底自主知识产权的高清电视解码芯片DS10000。双核技能的广泛运用可用并行处理办法加快速度。视频转码可分为同类视频转码技能和不同类视频转码技能。
2 像素域和改换域转码结构
图1是空域转码器结构框图,将H.264码流进行熵解码和反量化,然后逆DCT改换,得到像素域的像素值;依据解码的运动矢量和频域残差数据进行运动估量(Motion Estimation,ME),依据得到的运动矢量进行运动补偿(Motion Compensation,MC);再将得到的残差数据进行改换和量化、熵编码构成AVS码流。
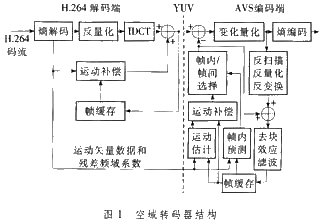
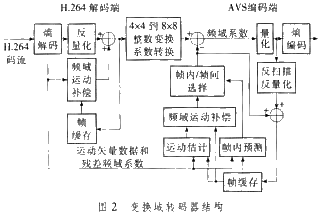
图2是改换域转码器结构框图,转码中不需求解得像素域的像素值,H.264码流通过熵解码和反量化,在频域中进行补偿,得到频域中重构的HT系数值,然后由H.264中的4×4HT系数改换成AVS中的8×8HT系数,依据H.264中解码得到的运动矢量和HT系数值来进行运动估量ME,由得到的8×8HT系数值在频域进行差错补偿;进行量化和熵编码构成AVS码流。
3 多线程转码器规划
运用程序加载到内存中,给出一个履行点称为线程。线程是体系需求分配CPU时间的根本履行单元。单个进程在任何时间可包括多个线程,它们可一起履行进程地址空间内的代码。
1) 子线程的创立与中止
VC++运用程序的主线程在创立运用程序时生成,创立子线程可通过调用CreateThread函数创立,其格局:
HANDLE = CreateThread (LPSECURITY ATTRIBUTES Ipsa,DWORD cbstack,LPTHREAD START ROUTINE lpStartAd2dr,LPVOIDlpvThreadParm,DWORD fdwCreate,LPDWORD lpIDThread);
在本转码器中,子线程创立办法如下:
slot=0; hThrds[slot]=CreateThread(NULL,0,ThreadFunc,(LPVOID)slot,0,&threadID).
2) 转码器的多线程完结结构
由图1和图2能够看出,转码器的解码和编码部分是相对独立的。虽然在编码端要用到解码得到的运动矢量、分块形式还有频域中的系数等信息,假如是单线程程序的话,在编码到这一帧时,解码程序就要中止,只有当编码这一帧的程序履行完后,才干开端履行下一帧的解码程序。所以,在解码时编码程序中止,在编码时解码程序中止,这将花费很多的时间来等候。
假如是在双核或许多核核算机上,可采用并行处理的办法,可发动两个或多个线程,一个解码线程和一个编码线程,在编码第n帧时,一起解码第n+1帧,到达解码和编码一起履行的作用。考虑到对体系内存的要求,这儿设置缓存区的巨细为2,多线程转码器完结结构如图3所示。
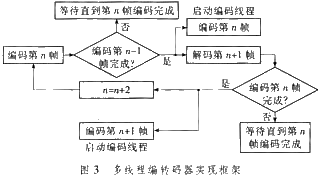
多线程转码器履行次序如下:当解码第n帧完结,判别第n-1帧是否现已编码完结,假如没有完结,则等候编码第n-1帧直到它完结,假如第n-1帧已完结,则开端解码第n+1帧,并一起开端编码第n帧;当第n+1帧解码完结时,再判别第n帧编码是否完结,若没完结,则等候它完结,若完结,则开端编码第n+1帧,然后令n=n+2,进行循环。所以,完结了编码和解码并行处理,解码当时帧和编码前一帧是一起进行的。
3) 多线程转码器的详细完结办法
缓存区巨细设置为2,奇数帧共用一组变量,偶数帧共用一组变量。H.264中解码的当时帧序号用img->number表明,AVS编码端编码的当时帧序号用img_avs->number表明。在解码第n+2帧时,decode_slice()解码一帧的函数前面加上判别是否编码完第n帧:
if (img->number=(img_aVs->number+2))WaitForSingleObject(hThrds[0],INFINITE);
解码第n+2帧完结时,等候编码线程完毕,Wait-ForSingleObjeet(hThrds[0],INFINITE),然后开端一个新的进程:
slot=0;hThrds[0]=CreateThread(NULL,0,ThreadFunc,(LPVOID)slot,0,&threadID)
在整个程序履行完之前,等候线程履行完今后,再完毕整个转码程序。
4 仿真成果
测验序列:foreman,格局为CIF(352×288),编码成IPPPPIPPP…,264量化系数为28,AVS端编码的量化系数为36,编码帧数为100帧。
核算机装备:Intel飞跃1.6 GHz,内存1 Gbyte,Win-dows XP sp2操作体系。
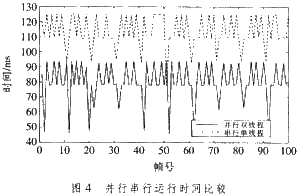
关于串行单线程的方法,均匀转码一帧的时间为113.57 ms;并行多线程的方法,均匀转码一帧的时间为80.19 ms。所以运用多线程编码的方法,由于编码和解码一起履行,时间可节省41.63%,转码速度是单线程编码方法的1.42倍。这是由于进程调度也要花费必定时间,所以双线程编码的速度没有到达单线程编码的2倍。本文中,考虑到对存储的要求,缓存区仅设置为2,运用的是一种乒乓式的拜访战略,解码端和编码端在每一时间都分别只拜访一组存储空间,不会一起拜访一组存储空间。假如把缓存区设置得更大一点,速度将还会有大幅度的进步。