轿车工程师选用多种智能技能帮忙人们安全驾驭轿车。轿车体系中的首要技能包含雷达、超声和摄像/视觉感测。这些技能总称驾驭员辅佐 (DA) 体系,用于在恶劣条件和风险路况下帮忙安全驾驭。
榜首代摄像 DA 体系现在可见于各种出产用车型。这类体系大多为驾驭员供给车辆周边环境的视频图画。最常见的是泊车/倒车辅佐体系,这种体系用后视摄像头拍照本车后边的景象,而且在无线电/导航体系的屏幕上或许在仪表板中的小型显现器上显现图画。
第二代摄像体系正处于开发测验阶段,现在运用有限。第二代体系并非仅为驾驭员供给图画,而是运用图画处理与解析从视频流中提取信息,而且对车辆环境进行表征和评价。必要时驾驭员会收到相应警示。
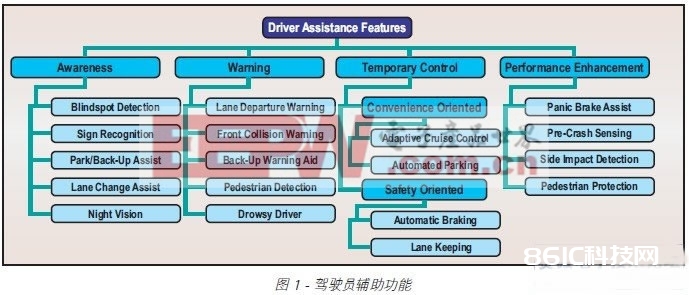
跟着工程师们获取车辆环境表征方面的实践经历,未来的 DA 技能会更杂乱,将为顾客供给更强壮的实用东西而且增强其他轿车子体系的功用。图 1 归纳了现在和未来的多种 DA 功用。
高档处理要求
DA 体系的处理要求或许超越现在轿车级串行 DSP 处理器的才能。别的,为了进步消费价值,在一套视觉传感器上绑缚多种 DA 功用的需求日益高涨。
例如,前瞻视觉模块或许需求一起支撑车道违背警示、智能大灯操控和标志辨认功用,而所有这些都需求不同的处理算法。因而,关于用 FPGA 经过原始图画数据处理、装备灵活性和器材可缩放性来供给体系价值,DA 商场供给了实实在在的时机。
视觉 DA 体系的图画处理与解析功用能够包含空间/时刻滤波、镜头失真校对、图画明晰化、对比度增强、边缘检测、图画匹配、物体辨认和物体盯梢,在某些情况下还包含图形叠加。特别值得重视的是一种支撑运动估量或立体视差核算的图画匹配功用。
为了阐明 FPGA 处理的功用价值,咱们来考虑这样一个视觉体系:以 30 Hz 帧速率 (fps) 生成视频的宽幅 VGA 分辨率成像器材(752×480 像素),而且需求估量帧间物体运动(或活动)。有一种算法(也适用于立体视差核算)是将图画划分为若干个块(如巨细为 4×4 像素),然后判别榜首帧中各图画块对第二帧中指定查找区(如 20×20 像素)内某方位的匹配条件。
一种常用的匹配条件是用算子 SAD(肯定差和)求出榜首帧图画中的 4×4 块与第二帧图画上查找区内的像素之间的像素灰度最小肯定差错 (MAE)。
咱们的 4×4 块匹配示例需求 250 MMAE/s(每秒百万次 MAE 核算)以上的功用,因为 (752 像素)×(480 行)×(20 ×20 像素查找区)×(30 fps)/(4×4 像素块巨细) = 270,720,000 MAE/s。MAE 表明 4×4 像素块的终究匹配差错,而 SAD 是指依据四个独立元素对进行核算得到的肯定差和。所以,每 MAE 需求四次 SAD 运算。
处理选项
由轿车规划工程师决议的处理选项包含超长指令字 (VLIW) DSP-CPU 和 FPGA。FPGA 的处理才能远远高于任何现有的 VLIW DSP-CPU。这是因为 FPGA 的架构:很多并行功用单元(包含可编程 MAC)使 FPGA 的功用比任何 DSP 都高出 10-30 倍(详细功用取决于所完结的运用),即便 FPGA 的时钟频率比 DSP-CPU 的时钟频率低得多。咱们运用块匹配运算示例,是要证明 Xilinx® FPGA 的功用比任何 VLIW DSP-CPU 处理器都高。
VLIW DSP-CPU 处理器中的 SAD 和 MAE 核算
在一个 32 位架构的单指令多数据 (SIMD) DSP-CPU 中可完结四个 8 位像素视频数据单元的 SAD 运算,因而,仅在一个周期内即可有用履行适当于 11 条底子指令的运算,如图2 所示。
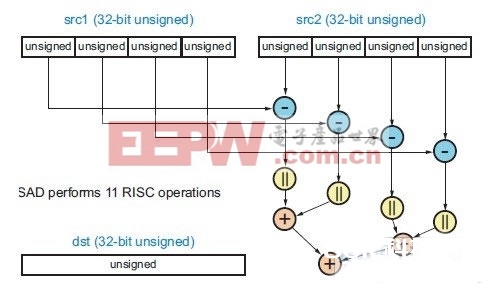
图2
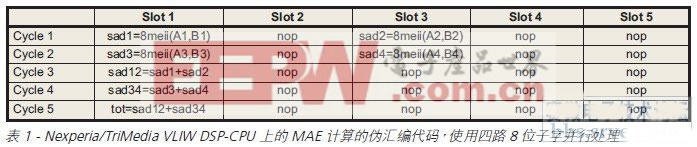
例如,Nexperia PNX1500 媒体处理器配有 32 位 TriMedia VLIW-CPU,关于具有二周期推迟的 8 位像素,能够在一个时钟周期内履行两条四路 SAD 指令。算上超长指令字,便是每时钟周期最多五条底子 RISC/SIMD 指令,其间只要两条能够是 SAD 指令(在 TriMedia 数据手册中称为“8meii”)。
所以,对 4×4 巨细的块进行 MAE 核算需求五个时钟周期,如表 1 所示:两个周期用于两条四路 SAD 指令的流水线处理(周期 1 用于 sad1/sad2,周期 2 用于 sad3/sad4);三个周期用于部分成果的累加(周期3、4 和 5)。因而,假如只处理一个块,则一个 300 MHz 的 Nexperia PNX1500 处理器的处理才能最高可达 60 MMAE/s。
假如每次处理一个以上 4×4 块,最高功用可略有进步。例如,能够在七个周期内核算两个并行 4×4 块的 MAE,这时功用可达 85.71 MMAE/s;而处理三个块需求九个周期,即功用为 100 MMAE/s。
可并行处理的最大块数别离受限于恣意长指令字中答应的 SIMD SAD 运算次数、VLIW-CPU 的通用寄存器数和优化编译器的调度算法。假如持续添加块数,全体功用会趋于饱满,因而咱们考虑并行处理的 MAE 不超越三个。
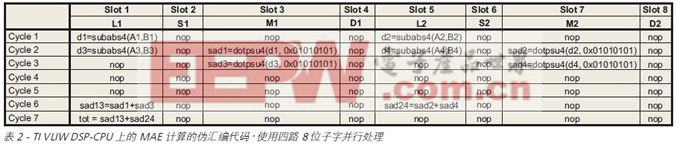
德州仪器 (TI) 的 TMSD320DM6437 数字媒体处理器每周期有一条由八次底子 RISC 运算组成的长指令,别离经过两条数据通路,各通路每周期有四个时隙。其 VLIW-CPU 每周期最多可履行两条 SAD 指令(在 TI DM6437 数据手册中称为“subabs4”),各指令有一个周期的推迟。可是,要累加部分成果,就有必要运用常数 0x01010101 履行具有三周期推迟的 SIMD MAC 运算(称为“dotpsu4”)。
所以,600 MHz 的 TI DM6437 DSP-CPU 能够用七个周期核算一个 MAE(如表 2 所示),因而关于 4 x 4 像素块的最高功用为 85.71 MMAE/s。假如并行处理两个块,就需求九个周期,功用为 133.33 MMAE/s;而三个块需求 11 个周期,功用为 163.64 MMAE/s,这依然低于咱们的 250 MSAD/s 要求。
VLIW DSP-CPU 功用缺乏
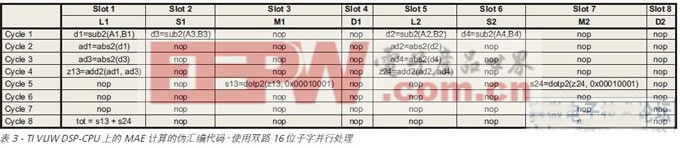
至此,咱们一向假定每像素 8 位,这很合适 32 位架构的 DSP-CPU 处理器。但是,新式 CMOS 图画传感器的分辨率规模较高,即每像素 12 到 14 位。关于这些数据类型,32 位架构的传统四路 8 位子字 SIMD 不行有用,有必要换用双路 16 位半字 SIMD,其间的子字并行度仅为二。因而,因为核算一个 MAE 需求较多时钟周期,最高功用大幅度下降。
表3 所示为在 TI VLIW DSP-CPU 上运用 16 位子字指令核算 SAD 时或许的伪汇编代码,假定推迟正确且函数发射时隙答应履行这种指令。因而,一个 4×4 的块需求八个周期,而并行处理两个和三个块别离需求 10 个和 12 个周期。这时,相应的最高功用别离为 75 MMAE/s、120 MMAE/s 和 150 MMAE/s。这些数字都比运用 8 位子字指令得到的数字小。
Spartan-3A DSP FPGA 的 SAD 和 MAE 功用
为了添补 Spartan™-3 和 Virtex™-4 器材之间的处理功用空白,Xilinx 推出了 Spartan 3A-DSP 1800A 和 3400A FPGA。这些器材采用了 Virtex-4 器材中的 DSP48 Slice 的修改版。别的,3A-DSP 器材包含很多片上存储器(Block RAM)。这两方面增强加上针对很多运用制定的价位使 3A-DSP 器材十分合适轿车视觉 DA 体系。
图 3 所示为 Spartan-3A DSP 1800 (XC3SD1800A-4FG676) 器材上的四路 12 位像素的 SAD 核算计划。此完结是运用 System Generator for DSP 规划流程(Xilinx 供给的 Simulink 东西中的数位和周期都准确的可归纳库)完结的。所需资源数量是 121 个 Slice(236 个 LUT 和 140 个触发器)。将此结构仿制四次而且加上部分成果,即得到整个 4×4 块的核算计划,该计划需求 508 个 Slice(990 个触发器和 606 个 LUT),具有一个周期吞吐量(这意味着可从恣意时钟周期开端核算新的 MAE)和七个周期推迟。
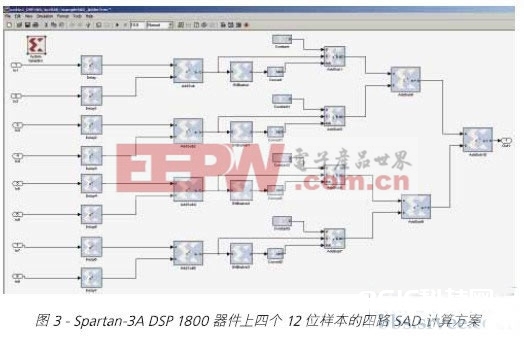
假如运用 150 MHz 时钟频率(该器材最高时钟频率为 250 MHz),只需求两个并行结构(约占器材面积的 6%)即可到达 300 MMAE/s 的功用,然后满意示例运用的 250 MMAE/s 功用要求。这样能够节约很多资源用来完结其他图画处理功用、数据路由管道、存储器接口操控器以及一个用于串行处理和外部通讯的 32 位 MicroBlaze™ 嵌入式处理器。
作为参阅,依然用 150 MHz 频率,Spartan 3A-DSP 1800A 器材仅运用整个 FPGA 器材的 70% 即可并行处理多达 23 个块(70%×16,640 Slice/508 Slice/块 = 23 块)。与此对应的最高功用是 3,529 MMAE/s,这至少要比 600 MHz 的 TI DSP-CPU 的最高功用高 25 倍。
定论
咱们以轿车视觉运用为例阐明了怎么运用中型低成本 Xilinx FPGA 的可编程并行处理才能供给超越 VLIW DSP-CPU 的处理功用。表 4 列出了咱们的剖析成果。
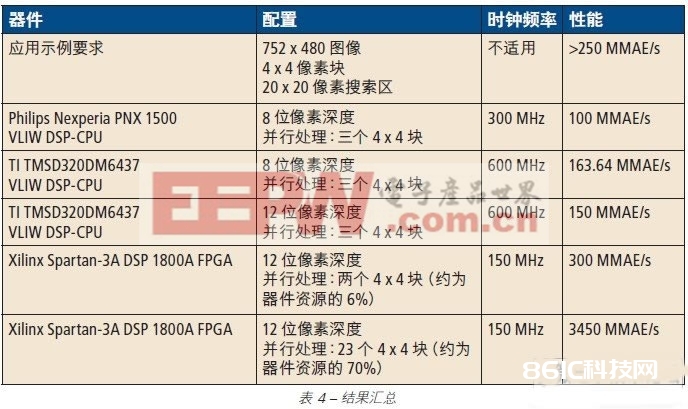
请注意,关于 12 位像素数据的 4 x 4 块的 MAE 核算,Spartan-3A DSP 的功用仅以四分之一时钟速度即可到达 TI TMS320DM6437 的两倍。别的,FPGA 的资源占用率仅为 6%,因而能够在同一器材上完结其他图画处理功用(必要时可采用并行处理)。
另一方面,VLIW DSP-CPU 在 SAD 核算期间被彻底占用,耗费串行处理器长指令的可用时隙,因而很少有时机一起履行其他功用。
咱们关于 FPGA 的预算时钟频率适当保存(以 150 MHz 对 250 MHz),关于运动预算的查找区也是如此(查找区越大,需求核算的 MAE 的数量就越多)。例如,30×30 的查找区需求 609 MMAE/s 的功用(远远超越 VLIW DSP-CPU 的才能),但是却仅占用 1800A 器材上 Slice 的 12%。
最终,咱们在完结 MAE 时底子未运用 DSP48 MAC 单元:据咱们估量,假如用四个 DSP48 单元替代由 100 个 Slice 组成的加法器树,则一个 12 位输入数据 MAE 的 4×4 块会占用 400 个 Slice(782 个触发器和 400 个 LUT)和四个 DSP48。
因而,Spartan-3A DSP 1800A 器材十分合适需求极高处理功用、灵活性和可缩放性的视觉运用,如未来型轿车驾驭员辅佐体系中的视觉运用。