1 导言
跟着互联网的飞速发展,网络流量不断增大、网络进犯类型层出不穷。侵略检测的高速度、低漏检率、低误报率等要求,使传统的以软件为中心的 IDS面临着越来越大的压力。仅靠形式匹配算法的改善对侵略检测速度的进步是有限的,不是处理问题的底子战略。
经过对侵略检测体系中检测速度瓶颈及形式匹配算法的剖析,提出了依据硬件完结侵略检测的战略。在体系顶用硬件替代传统侵略检测体系中的软件完结首要部件功用:如数据收集和过滤、多形式匹配及数据包调度等,硬件完结比软件完结的速度能明显进步。
2 体系规划
体系原型的规划依据SOPC技能,选用了多处理器并行处理结构、可扩大指令集和协处理器加快算法等规划思维。其间心内容是选用多级并行处理技能和专用功用部件替代杂乱费时算法,以取得极大的数据包处理功用。
1. 体系整体结构规划
原型体系的首要部件有数据收集模块、报文分配器、软核处理单元、形式匹配协处理器、自界说指令、主控通路接口及呼应输出等。体系的体系结构如图 1所示。
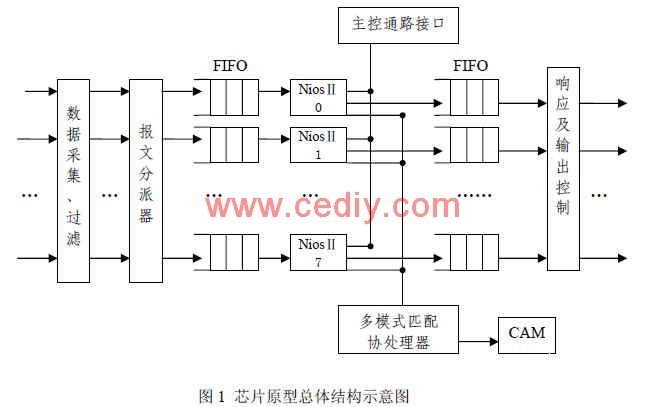
为了处理高速网络环境下侵略检测体系的检测速度瓶颈问题,在侵略检测进程的各个环节中,各处理器部件都有必要能线速处理数据包。本体系中选用硬件模块完结数据收集功用,对数据包的剖析检测模块选用并行处理的办法来提速;别的还选用协处理器来加快完结形式匹配进程。依据 FPGA协处理器能够加快多种不同的算法,其取得的功用是软件完结功用的几十倍。
2.数据收集部件
传统的网络数据截获用软件完结,经过函数复制 MAC缓冲区内的数据包来完结数据收集,运转速度低,丢包率高。本体系中的数据收集和过滤模块直接用硬件完结。当输入端口有数据进来时,过滤单元选择性的把需求的数据复制到 Buffer中,具有很高的收集速度,在千兆环境下丢包率很低。
报文分配器依照公正的轮询战略顺次从输入通路上读取 IP报文,然后依据输入缓冲中 FIFO的闲暇情况,将 IP报文分配到软核处理器的输入缓冲 FIFO中。
3.软核处理器单元
运用SOPC Builder界说网络处理器原型芯片中的并行处理单元 ——Altera NiosⅡ处理器软核。界说中需求设置各种硬件参数,包含作业频率、cache选项、加电引导办法、中止寄存器设置、内存巨细、Flash基地址以及各种的拜访形式和地址映射等。顺次对多个处理器软核进行描绘,并因而生成每个处理器软核的逻辑符号和软件编程接口,生成.elf文件。对芯片原型中的其他硬件逻辑规划选用硬件描绘言语,生成的硬件装备数据与处理器软核的.elf文件组成用于装备芯片原型 FPGA的.hex文件。
本体系芯片原型内的多个 PE选用并行结构,各个 PE有自己的数据和指令存储器,同享形式匹配协处理器模块。PE之间的通讯运用并行通讯接口 PIO来完结。其间 NiosⅡ是微处理器软核,RAM和 Cache寄存指令和数据, Load_Header和 Send_Header是报文头输入 /
输出逻辑,Lookup Controllor是多形式匹配协处理器接口逻辑, Cam_update Controllor是规矩表办理逻辑接口,PIO是并行通讯接口。
4. 协处理器规划
虽然有软件形式匹配算法的改善,形式匹配仍然是高速流量剖析的约束。咱们经过下载一切形式匹配使命到可重装备的 FPGA协处理器来消除这个瓶颈。 FPGA能对 Snort规矩中每种形式与包内容进行比较,整个规矩集装入在一个低端 FPGA设备上。
本体系中处理器软核 NiosⅡ同享匹配查表协处理器,选用总线裁定器同享机制。每个处理器软核有一个匹配查表协处理器的接口操控器 Lookup,它作为自界说指令逻辑包含在处理器软核内部。匹配查表协处理器与处理器软核并行作业,经过查询办法判别协处理器作业是否完毕。协处理器运用 CAM寄存规矩表。 3 体系要害技能及完结
1. 多处理器技能
PE(Processor Element)是网络处理器的中心部件,承当体系内首要核算使命,每个 PE实际上是一个微处理器核。网络处理器一般包含多个 PE,PE之间有两种首要衔接办法:并行衔接和串行衔接。
2. 多级并行处理技能
网络数据包处理存在本质上的并行性,为了昀大极限地进步报文处理速度,满意网络运用的需求,网络处理器完结不同层次并行处理:完结处理器级并行处理、经过硬件多线程完结线程级的并行处理、经过指令流水线完结指令级的并行处理。处理器间的并行还能够分为 PE之间的并行运转及 PE与协处理器之间的并行。
3. 硬件线程和 “0开支”切换技能
PE内部选用硬件多线程技能,每个 PE中有多个硬件线程,硬件线程是指享有独立的程序计数器、寄存器和存储空间的线程。 “0”推迟切换原理是:硬件线程在进行线程切换时,既不需求保存行将中止运转的线程的现场信息,也不需求康复行将运转的安排妥当进程的现场信息,因而不耗费 PE资源,能做到“0开支”切换。NP运用硬件线程掩盖了线程切换的推迟,进步了 PE的运转功率。一般地,经过合理规划调度战略,PE运转功率可接近 。
4. 分布式数据存储技能
存储器也是网络处理器的要害,其存取速度和带宽是影响网络处理器功用的重要因素。依照存储转发的思维,一切报文进入网络处理器后有必要缓存。要线速处理报文,报文的输出速度有必要与输入速度共同,既存储器带宽是端口速度的两倍以上,这对现在存储器是一个巨大的应战。
一方面,NP选用数据分布式存储结构。NP内设置多级存储器:片上快速存储器和片外慢速存储器。另一方能,网络处理器选用数据预取、块传送、高速数据通路等技能来处理高速核算和高速数据传送的问题。
5.体系完结
本体系是面向侵略检测的网络处理器原型,侵略检测的流程包含数据收集、数据包预处理、数据包检测、及呼应四个过程。原型体系将侵略检测的首要作业,如数据收集及过滤、多形式匹配、数据包在多处理单元上的分配等用硬件完结,而数据包的剖析检测也用多个处理单元进行并行处理。
该原型体系包含:一个主控模块、一个硬件数据收集模块、八个软核并行处理单元、一个多形式匹配协处理器。体系选用报文分配器完结 IP报文到核处理器的分配使命,软核微处理器对报文做侵略检测。每个软核微处理器都具有一个输入缓冲 FIFO和输出缓冲 FIFO,用于缓冲需求处理的报文。呼应和输出操控模块依据报文的查看成果,决议是否作为不合法包丢掉仍是作为正常包转发到相应的输出数据通路上。 4 体系测验及功用剖析
为了进行体系测验,开发了如图 2所示的验证渠道。体系原型验证渠道运用多片 FPGA完结各种功用接口,一起将网络处理器的中心功用在单个 FPGA芯片中完结,用于支撑网络处理器操控功用和体系办理功用的主控模块也选用一个独立的 FPGA完结。

体系功用测验在体系验证渠道下进行。经过JTAG接口将验证渠道与微机相连,运用IDE开发环境进行软件调试。报文生成器是 FPGA内的一个模块,运用它能发生变长的接连报文。网络处理器芯片的输入端接纳 33位数据( 32位数据和 1位标志位),经报文分配器分配给多个 PE进行处理。每个 PE对报文头进行解析,并查找规矩表,发生 11位转发操控信息用于输出操控。
在 FPGA上进行形式匹配的重要功用指标是吞吐率。咱们经过输入不同巨细的数据包进行试验,试验成果如表 1所示。

PE读取第一个报文头到读取第二个报文头的时刻为 246个时钟周期,报文处理推迟为 4920ns,试验丈量值与核算值根本契合。试验中体系每秒处理 330K个报文,体系的吞吐率与报文长度有关,总的吞吐率理论上可到达 14Gbps,但理论值只要在 PE与协处理器满负荷运转下才有或许取得。从表 1还可看出,在 FPGA内部跟着资源运用的添加,内部推迟会添加,吞吐率稍有下降。
5 小结
经过对侵略检测体系中检测速度瓶颈的剖析,规划了一个依据硬件的侵略检测体系原型。该原型选用依据网络处理器的硬件战略替代传统侵略检测的软件战略,试验证明该体系的功用与传统办法比较有明显的进步,很好地处理了侵略检测中的速度问题。体系都是在依据 FPGA上完结的,并能够依据实际需求添加硬件和自界说指令来进步体系功用。
本文作者立异点:规划了一个依据 SOPC网络处理器的侵略检测体系原型,将侵略检测的首要作业用硬件来完结,与传统的依据软件战略比较功用有明显的进步。
责任编辑:gt