ARM通用CPU及其开发渠道,是近年来较为盛行的开发渠道之一,而由ARM+DSP的双核体系结构,更有其一起的功用特色:由ARM完结整个体系的操控和流程操作,由DSP完结详细的算法和核算处理。这样,不光能够充沛地发挥ARM便利的操控优势,一起又能最大极限地发挥DSP的核算功用。这在业界已逐步成为一种趋势。
本文的FPGA的Demo验证,是在根据一款DSP内核处理器的研制基础上,对其功用进行验证的一个小方针辨认算法的完成。考虑到软件环境仿真的速度以及仿真模型的局限性,用FPGA进行硬件协同验证。这样,既能够确保仿真的真实性,又能够快速发现实践问题,削减不必要的流片次数,加速开发的进程,这关于一个大规模的SoC规划,现已成为不可或缺的手法之一,并且对节省本钱也有很大优点。
1 体系体系结构
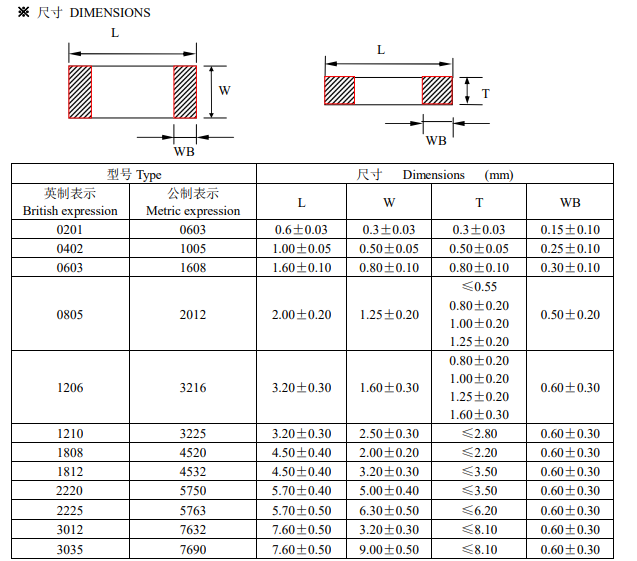
双核体系的体系结构如图1所示。
1.1 内嵌ARM内核的EPXA1芯片及其特色
图1中,包含ARM922T内核的开发渠道选用的是Altera公司的excalibar系列,本验证完成选用的类型是EPXA1。EPXA1是一款带有100万门可重装备PLD的ARM Core+PLD体系结构,能够经过quartus II软件东西来灵敏装备ARM Core同外部的端口衔接,最大时钟频率能够到达200MHz。EPXA1的高度集成化,不只大大加速了ARM与片内各种资源的通讯速度,并且减小了硬件电路的杂乱性、体积和功耗,真实完成了SOPC[1]。
1.2 FPGA硬件渠道及其特色
关于一个详细项目,FPGA芯片的选取要根据实践需求和特色来详细考虑。一般应从逻辑资源需求、易扩展才干、信号质量以及本钱等因从来考虑。如图1所示,本次规划选用的两片FPGA别离为Xilinx公司的FPGA X3S5000和X2V6000,其容量别离为500万门和600万门。选用这两块芯片正是根据逻辑资源需求的考虑。FPGA X2V6000面向高端运用,存储资源更多,功用更强壮,适用于功用要求较高的DSP内核,但其本钱相对也较高;而FPGA X3S5000本钱较低,适用于一般功用要求的模块。两片FPGA都具有三个扩展槽,可做接口扩展,一起也能作为调试测试点用。
1.3 双核体系结构规划特色
详细来讲,整个体系结构是指经过人为规划电路图,外部选用不同的FPGA器材来下载生成特定功用的外部硬件电路,在电路图上对应相应的端口标号;一起,ARM Core能够经过quartus II东西便利地衔接不同的端口标号,编译运转生成相应的装备文件;ARM的发动代码顶用以上的的装备文件信息来装备PLD,然后完成ARM同外部硬件电路即两片FPGA的衔接[3]。FPGA X3S5000中下载固化AHBC硬件电路以及外部SRAM Memory,而FPGA X2V6000中下载固化DSP Core以及支撑AMBA协议的Wrapper。
这种体系结构能够充沛运用硬件资源,合理的地图方位便利了ARM和DSP对外部SRAM的拜访,一起可便利地完成ARM的操控功用,并且预留的扩展槽能够较为便利地进行功用扩展和调试。DSP Core的Wrapper能够快速呼应ARM的操控恳求,调集DSP Core进入不同的作业状况。
2 体系作业流程及特色
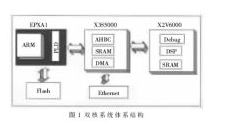
体系作业流程图如图2所示,介绍如下。
2.1 ARM担任预备阶段
ARM从Flash中运转发动代码,经过装备PLD来衔接FPGA X3S5000中的AHBC,意图在于ARM经过AHBC同FPGA X2V6000中的DSP Core进行交互。
代码唤醒外部DMA经过以太网口从PC机端转移榜首帧待处理的图画数据,放到双核共用的外部SRAM memory既定的地址段中。然后,ARM Core经过AHBC操控FPGA X2V6000中的DSP Core。
这儿需求阐明两点:
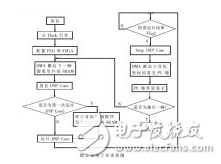
(1) FPGA开发板的的图画传输是经过专门装备的带有LXT972芯片的以太网口与PC机的以太网口进行交互, 如图3所示。图3左面的以太网子板即图1中的Ethernet模块。
(2) DSP Core顶层的wrapper是支撑AMBA协议的TOP Module,其间包含一个Debug Sub-Module。ARM便是经过读写Debug Sub-Module的操控存放器来操控DSP Core的发动、中止等作业状况的。所以说,Debug Sub-Module是整个FPGA工程最为要害的部件之一,它直接关系到ARM和DSP之间的交互。本项目中,运用Debug Sub-Module完成对DSP Core的复位、发动、暂停、断点设置、单步运转、读写内部SRAM、读DSP Core存放器等一系列功用,大大便利了调试作业,一起也十分快捷地完成了ARM和DSP的交互运转。
2.2 DSP运转阶段
ARM写操控存放器使DSP Core复位,并把小方针辨认的程序代码写入DSP内部的SRAM0中等候DSP发动运转,由ARM操控DSP Core运转起来。DSP Core运转完程序之后,会在外部SRAM的一个地址上回来一个标志数(0x00ff00ff),一起进入idle状况,彻底释放对AHBC的操作。每隔一段时刻,ARM查看一下相应地址上的这个标志数,假如没有,则表明程序还未运转完,ARM持续查看;假如有,则表明程序现已运转完毕,ARM将进入下一步操作。
选用这种流程有两个特色:(1)ARM彻底完成了操控和辅佐的效果,而运转部分则彻底由DSP担任,各自分工明晰。(2)ARM和DSP完成了很好的交互,谨慎地操控了流程的运转进程。
2.3 ARM操控中止回来
ARM经过写操控存放器把DSP Core停下来,从外部SRAM的既定地址段中取出DSP Core运转完所回来的小方针的坐标信息,并经过以太网口回来到PC机端,在显现界面的此帧图画上显现出小方针。图4为其间一帧图画的处理结果显现。

ARM擦除DSP Core运转完毕的标志数,一起判别当时处理完的图画是否为终究一帧,假如不是,则流程跳回DMA转移进程去履行下一帧图画,一起加上必要的操控,防止写程序的重复履行;假如是,则完毕整个程序运转。这样循环下去,直到一切图画序列处理完毕。
这个进程充沛显现了ARM在操控流程的判别跳转方面所起到的首要效果。由ARM的渠道来完成对整个视频序列的终究处理操控进程,显得十分明晰快捷。
3 体系架构的调试
3.1FPGA的选取
FPGA的选取一定要适宜(这儿首要针对容量而言)。以本开发进程为例, Xilinx的两片FPGA(X2V6000和X3S5000)的容量别离为600万门和500万门左右,而项意图硬件代码容量却略微超出了这个规模,所以不得不对一些模块作精简和放弃。即便如此,两片FPGA的运用率都已大于90%。
一般来说,FPGA的运用率到达70%或多一些是比较好的,太高的运用率反而简略形成板子的不安稳。本开发进程就有一些不安稳要素,例如,因一些数据线、地址线的单个位传输值不正确,需求花很多的精力才干清查出这些存在问题的线路,然后替换Bonding衔接,选用其他的通路。一起,所形成的不安稳要素也会影响下载代码的运转速度。现在经过Xilinx的软件东西ISE归纳出来的FPGA可下载代码受时序束缚,所能到达的速度上限为25MHz时钟频率。
容量大的FPGA的本钱相同也会比较高,所以在研制需求和本钱之间有必要找到一个比较好的平衡点,这在整个电路规划阶段就要预测得比较好,但这不太简略做到,需求经历的堆集。
3.2观测点的预留
开发板在规划电路图阶段,一定要预留出满足的观测点。这一点十分重要。因为:在后来的调试进程中,当呈现问题时需求清查线路,而现在的FPGA调试软件还不老练,并不像RTL代码前端仿真那样便利,能够把一切的信号都输出到屏幕上观看,并且FPGA调试时运用的逻辑剖析仪只能够丈量观测点的信号波形,假如观测点不行的话,当呈现逻辑过错时,底子没办法清查下去,找不到问题的地点,或许需求做适当繁琐的重复作业,才干把估量存在问题的线路节点信号连(Bonding)到仅有的观测点上。假如经排查,估量得不正确或许需求进一步拉出更多的其他信号时,又需求从头花时刻将节点新信号连到观测点。这样,会消耗十分多的时刻和精力。因为对每一次新的节点生成一版新的FPGA下载代码都很烦琐。
所以,从电路的规划之初,预留出满足的观测点,尽量将更多的节点信号连到观测点上。这样将会极大地便利调试作业,加速整个研制进程。
3.3FPGA调试的准则
FPGA的调试应该依照由简入繁的进程进行。这样能够便利研制人员快速地了解板子,并且简略定位问题的地点。
因为整个ARM+DSP体系结构是由ARM加上两块FPGA一起作业,相对比较杂乱,相互之间交互性比较多。所以,在调试整个程序之前,能够先经过别的的小程序和硬件结构别离调通ARM对两片FPGA的交互;然后,再用较为简略的功用模块调试好三块片子的简略交互功用;终究,把整个大程序运用在上面进行测验。这样一步步下来,呈现问题时,就比较简略发现问题地点,便利调试。
例如,能够先不考虑FPGA X2V6000,独自调试ARM经过FPGA X3S5000中的AHBC对外部SRAM读写的操控,成功之后,再将FPGA X2V6000考虑进去,但先不考虑Debug模块对DSP的操控,独自将Debug模块提取出来,下载到FPGA X2V6000傍边;然后再调试ARM经过FPGA X3S5000中的AHBC关于FPGA X2V6000傍边的Debug模块的操控存放器的读写状况等。
3.4软硬件协同验证
软硬件协同验证是较好的验证方法(或调试方法),二者都是为了确保体系功用和结构正确的有用手法。在整个FPGA体系完成进程中,十分有必要结合前端软件仿真波形来参照调试体系各个环节的功用运转状况,这样能够大大简化研制进程,有用地缩短调试周期。能够说,假如不结合前端软件仿真波形来协同验证的话,要想完成一个较为杂乱的体系结构是十分困难的。
一般来说,关于这样一个较为杂乱的体系结构需求先进行前端RTL代码的软件仿真,因为前端仿真关于纠正RTL级代码以及功用方面的过错是十分便利的,并且它所需求的验证周期和纠错难度比硬件的FPGA验证要有利得多。可是FPGA硬件验证,其真实性又是十分牢靠的。所以验证波形彻底调试经过之后,能够十分有用地辅导FPGA的完成。当FPGA在调试某项功用时呈现了问题,能够经过逻辑剖析仪将可疑端口节点出来的观测点波形导出来对照软件仿真波形来查找问题,这是一种十分有用的手法。
3.5Demo演示速度的调整
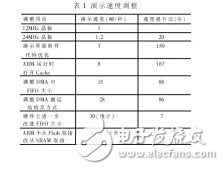
现在,开发板选用的晶振频率为24MHz,安稳的演示版别速度能够到达28帧/秒,为人眼所能承受的接连视频速度,效果现已适当好。这是经过了各种调试才到达的效果。首要原因在于考虑比较周全:DMA在传输图画序列的时分,所用到的FIFO在规划之初就考虑到了FPGA的容量和运用率,认识到其容量有限,在现有的FIFO容量下,要想调整到一个DMA与PC机两边网口传输速度的精确状况不太简略,假如运转速度太快,交互同步不精确,就会有丢包的现象产生;假如为了更便利的调试和到达更好的速度功用,能够选用更大容量的FPGA,规划更大容量的FIFO,这样每一次图画传输就能够传送更多的图画数据,削减DMA转移的次数,传输两边的交互进程较为简略操控。表1给出了从开端演示速度不睬想到较为抱负所做的调整进程。从表1中能够看出,独自调整晶振频率,速度提高并不显着。这阐明了速度瓶颈不在硬件代码功用上,要害在于演示界面的软件代码、ARM的Cache翻开与否以及图画转移的速度三方面。一起还能够看出Cache的翻开关于速度影响很大,阐明ARM的取指速度受到影响。现在ARM的运转指令是放在Flash中,假如改成从SRAM中取指,估量效果会愈加抱负。
从以上剖析可见,ARM在整个规划中所起的首要效果是操控图画的输入输出,以及循环操控DSP Core的运转中止等状况;DSP Core的首要效果是处理运算运用程序,核算小方针辨认程序。这样既分工又协作,能够充沛发挥ARM的操控功用以及DSP Core的数字运算处理功用。
与此一起,因为ARM在整个规划傍边首要起到一些辅佐的操控效果,ARM922T的一些扩展DSP运算功用没有用到,假如归纳考虑到本钱和性价比等要素,能够考虑选用ARM7硬核、NIOS 或其他方式的软核代替。