本文介绍稀少LSTM的硬件架构,一种是细粒度稀少化,权重参数散布随机,别的一种是bank-balance稀少化。
1. 文章结构
Long-short term memory,简称LSTM,被广泛的应用于语音辨认、机器翻译、手写辨认等。LSTM涉及到许多的矩阵乘法和向量乘法运算,会消耗许多的FPGA核算资源和带宽。为了完结硬件加快,提出了稀少LSTM。中心是通过剪枝算法去除影响较小的权重,不断迭代练习以到达方针函数收敛。参加实践运算的权重数量大大减缩,这能够有用下降FPGA核算资源和缓解带宽以及存储。本博文结构如下:
1) Fine-grained稀少紧缩的硬件架构。权重稀少化后,数据被大大紧缩,可是也添加了有用数据散布不规律性,这些添加了硬件完结复杂性。
2) Bank-balanced稀少化方法以及硬件架构。为了能够进步权重数据规律性,提出了bank-balanced稀少化方法。
2. fine-grained稀少化
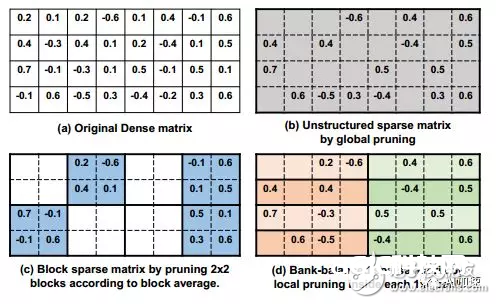
首先要讲的是细粒度紧缩架构。当对一个现已练习好的网络进行剪枝后,你会发现权重散布会变得十分随机。这不利于硬件加快的完结,因为FPGA更喜爱整齐划一的结构,这样便于并行化处理。比方关于下边左图,每一行有用权重数据个数不同,而咱们在硬件中依照行(这是最简单的并行化方法)并行运算的时分,每一行核算的时刻就不会持平,用时少的会等候用时长的,终究用时长的决议了核算的总时刻。这样就产生了核算间歇,下降了核算利用率。左图的核算功率就只有60%((5+2+4+1)/20=60%)。、
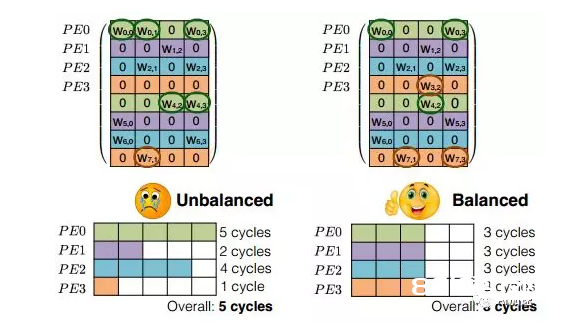
为了进步核算功率,下降等候时刻,最理想状况是每行的有用权重数据相同,这样就不需求进行等候了。如右图,只是每行核算都需求三个时钟周期。核算功率100%。在进行练习的时分,就需求添加约束条件使得每行具有相同的有用权重数。从成果看出,这样处理在能够加快硬件的一起,还能够坚持不变的精度。
模型数据练习是依据浮点数的,浮点运算十分消耗硬件资源,最好的方法便是进行量化,即将浮点转化为定点。量化根本观念便是将彼此挨近的数用一个数来表明,能够看做是一种聚类。假定参数集W,将其分红h类C。运用k-means聚类,便是最小化:
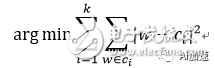
量化之后不只减小了权重数据量,这对FPGA上缓存需求以及带宽都能有用缓解,并且还会下降浮点运算带来的巨大逻辑资源消耗。
LSTM中包含了矩阵乘向量,矩阵点乘等操作。进行了剪枝和量化后的权重数据大大削减,为了只传递有用权重,需求对权重数据进行稀少编码。论文中选用这样的方法:一个有用数据外加两个指数,用于标识数据地点矩阵中的方位。一个指数是相对行号,相对行号表明下一个数据相关于前一个数据的行号间隔。别的一个是列号,表明数据地点列坐标。这样在FPGA中就能够依据这两个指数回复权重的方位,并且取出向量中对应的数据。能够在矩阵行的基础上进行并行化规划,比方规划N个并行乘法阵列,每个阵列有3个乘法器,乘法器之间能够进行累加。假定矩阵每行3个有用数据,这样每个阵列就能够进行3次并行乘法运算,并能前向累加。
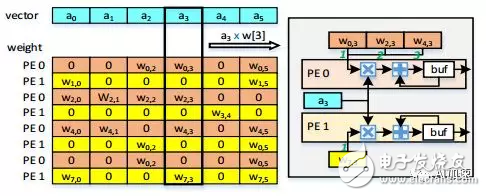
再来看全体架构,FPGA进行矩阵乘法,矩阵点乘,激活等加快操作,CPU进行指令、权重、输入数据调度。CPU通过PCIE和FPGA进行通讯,将权重、指令、输入等数据发送到FPGA端,并且接纳来自FPGA的处理成果。因为权重等数据很大,所以FPGA板卡上也装备了自己的DDR,用于存储这些数据。并且在FPGA芯片中也需求必定缓存用于存储权重数据(这部分数据很大,最好是片上能够放得下)、暂时数据、成果等。一般都是FPGA核算量很大,而FPGA和DDR的带宽受到限制,所以一个有较大片上存储资源的FPGA更有利于深度学习的加快。

FPGA上的结构首要有:和CPU通讯的PCIE操控,读写DDR的操控接口,输入输出缓存,加快计算单元,指令操控和调度。其间加快单元是中心模块,其间包含了稀少矩阵乘法,累加,激活函数等操作模块。
稀少矩阵乘法和点乘操作是最消耗核算资源和数据资源的,为了进步核算功率。论文中依据数据之间依靠联系建立了整个操控流程。规划的方针是尽量进步并行化,削减等候时刻,使得核算和加载数据时刻能够堆叠。比方 是彼此独立的,就能够一起核算。而有些尽管彼此独立,可是存储彼此抵触,就只能次序核算。比方
是彼此独立的,就能够一起核算。而有些尽管彼此独立,可是存储彼此抵触,就只能次序核算。比方
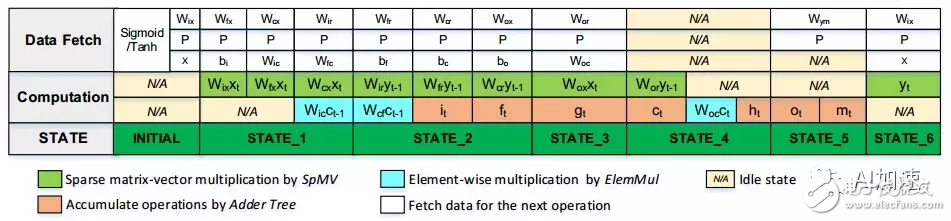
即便通过了剪枝和量化,权重参数也许多,片上有限的资源远远承受不了,所以这些数据都存放在DDR中。在需求的时分加载到片上,假如能够做好流水以及有较大带宽,是能够有较高核算功率的。
ActivaTIon vector queue:ActQueue包含许多FIFO,每个FIFO存储了向量数据,每个ActQueue被同一个通道的PE同享。每个FIFO对应一个PE。ActQueue用于提供给各个PE用的数据,这些数据在向量中并不是对齐的。假如某一行中有用权重数据少,那么其就需求等候其他PE完结。
3. bank-balance架构
提出bank-balanced结构是为了处理fine-grained结构中数据随机不对齐的问题。将权重矩阵每行分割成bank单元,让每个单元中的有用权重数据数量持平。比照fine-grained和coarse-grained稀少化,fine-grained能够将参数紧缩的很高,可是导致权重散布不均匀,而coarse-grained能够获得均匀的权重结构,可是精度下降很大。Bank-balanced结构既有散布均匀的权重,一起又能够坚持精度。
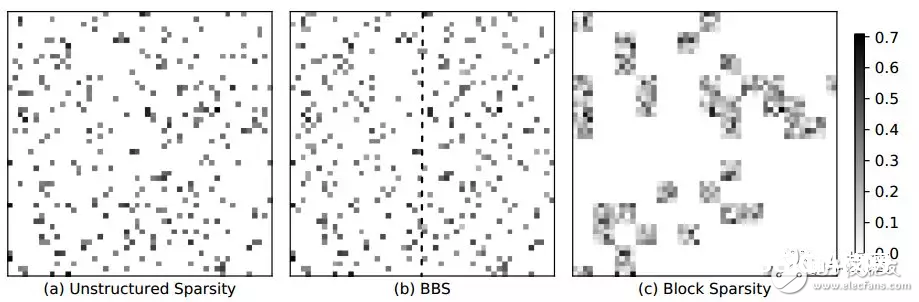
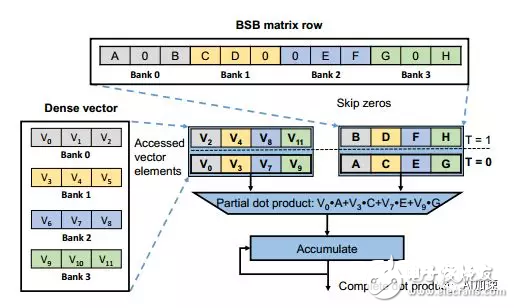
BBS结构有利于硬件加快,认为不只是能够添加行间并行度,还能够依照每行相同的bank数进行bank并行核算。并且每个bank数据量相同,那么核算的时分能够一起进行,没有等候时刻。比方咱们有一个矩阵按行分为4个bank,那么对应的向量也分红4个bank,bank间是并行核算的。Bank内会依次次取出有用的权重和对应的向量,进行乘法之后再累加。这种方法能够防止无规则的核算以及拜访存储。
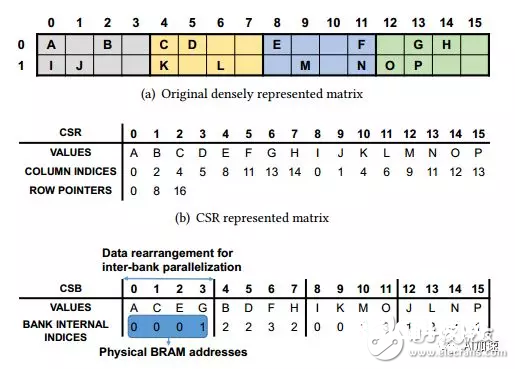
稀少化后的矩阵是需求通过编码的,这样才干确认其在矩阵中方位。编码方法比较盛行的有CSR,COO以及CSC等。可是他们一般都是用两个指数(比方行号和列号)来表明数据方位,这会额定添加数据负重。本论文中针对BBS结构规划了一种灵敏简练的编码:CBS。其由两行组成。榜首即将数据重新摆放,取出每个bank中榜首个非零数据一次摆放,然后再取出第二个bank中非零数据。第二行由数据地点的bank内方位决议。这个方位目标能够用于后边获得向量数据的bram地址。
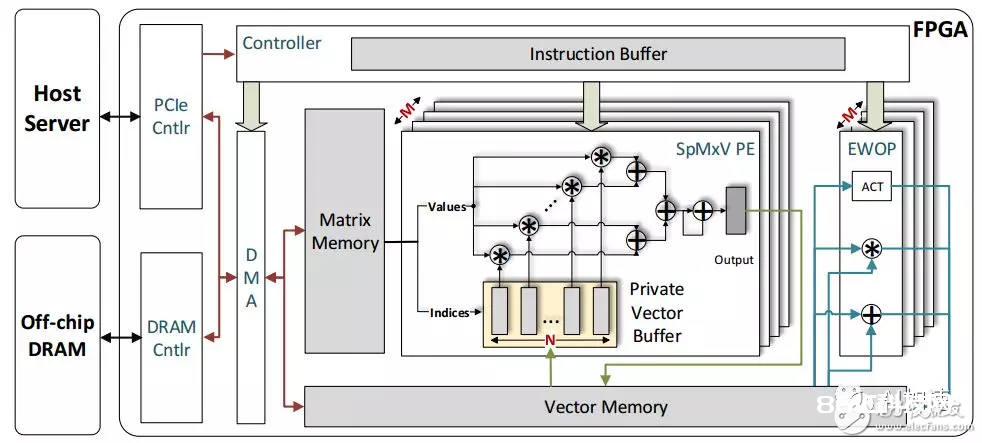
整个硬件架构如下图:首要包含PCIE操控,DDR操控接口,指令操控,PE阵列,矩阵存储,向量存储,之后的点乘和累加等。再介绍一下指令类型:
1) load/store: 这两个指令用于从DDR中加载数据到片上或许从片上存储数据到DDR中。
2) computaTIonal指令:依据LSTM的运算形式分红了两种,一个是spMx指令,用于核算矩阵乘法,别的一个是EWOP,这个用于点乘,累加,三种激活。
4. 总结
总结一下,这篇文章咱们首要介绍了针对LSTM完结硬件加快的方法:稀少化。稀少化会大大下降权重参数,下降核算量以及存储空间。一起比较了两种稀少化方法(fine-grained和bank-balanced)的不同。介绍了LSTM硬件完结的根本架构和指令集。