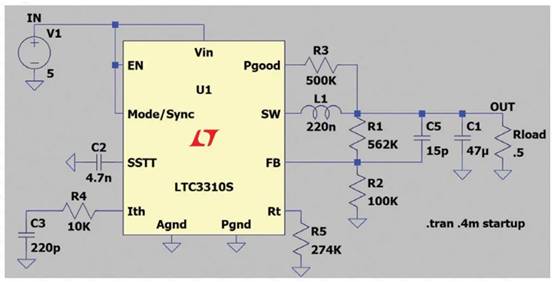
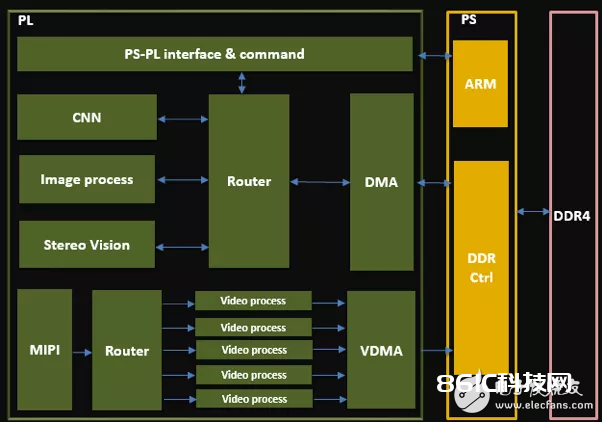
在前不久的 Baidu Create 2019 百度 AI 开发者大会上,Apollo 发布了业界创始的 AVP 专用车载核算渠道——百度 AVP 专用量产核算单元 ACU-Advanced。

本篇文章,咱们将从与自动驾驭的联系、加快中遇到的应战、量化核算、节省资源和带宽五个方面,介绍 ACU-Advanced 的中心高性能芯片 FPGA 的相关技能。
这是一篇“硬核”的技能文章。正是这些后台的“硬核”技能,成果了令人夺目的自动驾驭。本文中介绍的相关技能现已落真实 Valet Parking 产品中的量产 ACU 硬件上。
自动驾驭与 FPGA
人工智能技能是自动驾驭的根底,算法、算力和数据是其三大要素。本文讨论的便是其间的“算力”。算力的凹凸,不只直接影响了行进速度的凹凸,还决议了有多大的信息冗余用来确保驾驭的安全。
算力最直观地表现在硬件上,而轿车对自动驾驭的控制器有特别的要求。

除了对一般硬件的本钱、体积分量、功耗的要求外,还要求:
供给满意的算力,确保行进速度和信息冗余。
满意苛刻的车规规范,比方超宽的温度规模,-40℃ – 85℃。
归纳来看 FPGA 是合适自动驾驭高速核算的技能,它具有以下的杰出长处:
技能牢靠。FPGA 在轿车职业早已被广泛运用,也经受了军工、航天、通讯、医疗等需求高牢靠性职业的检测。比较而言,GPU 不具有这个特色,而为自动驾驭新开发的 ASIC 需求时刻查验。
灵敏,有利于算法迭代。FPGA 具有可编程的特色,特别合适自动驾驭这种新式的、功用需求并不彻底确认的职业。假如运用 ASIC,则算法的自在度就被捆绑,不利于算法的演进。ASIC 开发周期需求几年,假如选用 ASIC 加快,算法理念被锁定在几年前。比方,假如 ASIC 被规划为只能为 CNN 加快,那根据规矩的立体视觉技能将无法完结。即使 ASIC 规划中考虑了双目立体视觉的加快,那根据运动的立体视觉技能(Structure From Motion, SFM)就无法完结。这些繁复的、改动的需求是新式产业的标志,但也使 ASIC 很难彻底承受。
有制品可用。现已有老练的 FPGA 产品,供给不同的算力,能够直接挑选。新的 ASIC 开发延期,乃至失利,并不是小概率事件。笔者曾经在通讯设备职业作业10年,见证了移动通讯技能 2G、3G、4G、5G 的变迁。即使通讯职业规范明晰且超前,为扫除技能不确认性,每次技能变迁时,总是先推出根据 FPGA 的量产产品,确保能够占领市场先机。
虽然 FPGA 有牢靠、灵敏、有老练制品的长处,但 FPGA 的开发有很强的专业性,终究完结的效果与详细的规划很相关。
FPGA 加快遇到的应战
实践中遇到的应战是,多种多样的加快需求和有限的硬件资源的对立。
需求的来历既包含深度学习前向估测、也包含根据规矩的算法。

硬件资源受限包含了:FPGA 资源受限和内存带宽受限。
FPGA 资源的有限性表现:
峰值算力受限:有限的 FPGA 资源约束了核算并行度的进步,这约束了峰值算力。
支撑的算子品种受限:有限的 FPGA 资源只能包容有限个算子。
内存带宽受限表现在:
内存数据传输在核算总时刻中占有了不行疏忽的时刻。
极点状况下,对某些算子进步并行度后,核算时刻不减。
为应对这些应战,咱们在实践中提取了一些有利的经历,总结出来与咱们同享。
量化核算
算法工程师选用浮点数 float32 对模型进行练习,产出的模型参数也是浮点型的。然而在咱们运用的 FPGA 中,没有专用的浮点核算单元,要完结浮点数核算,价值很大,不行行。运用 int8 核算来迫临浮点数核算,也即完结量化核算,这是需求处理的第一个问题。
量化核算原理
以矩阵 C = A*B 为例,假定 A、B 元素为 float32 类型,选用爱因斯坦符号法:

符号表明四舍五入,两个把矩阵A和B的元素线性映射到区间[-127, 127],在此区间完结乘法和加法。终究一个乘法把整型成果还原成 float32。
假定 i = j = k =100:
在量化前,需求完结1000000次 float32 的乘法。
量化成 int8 后,需求完结1000000次 int8 的乘法,和30000次量化、反量化乘法。
因为量化和反量化占的比重很低,量化的收益就等于 int8 替代 float32 乘法的收益,这是十分显着的。
不知道量化标准:动态量化
假如上面式子中,量化标准 max|A|, max|B|,在核算前是不知道的,每次核算矩阵乘法前,就需求逐一查找 A 和 B 的元素,找出量化标准。
这种办法的优点是,每次核算既能充分运用 int8 数据的表征才能(127总能被运用到),不存在数据饱满的状况(一切元素都被线性映射),确保单次核算的精度最高。能够直接承受浮点练习的模型,坚持准召率。Resnet50 测50000张图片,Top1 和 Top5 准确率下降1%。在 Valet Parking 产品用到的多个网络中,没有调查到准召率下降。
缺陷是,FPGA 核算有截断差错,经过屡次累计,数值核算差错最大均匀能够到达10%。关于一些练习不彻底成功的模型(只在有限评测集上效果比较好),准召率下降显着,成果不行控。
已知量化标准:静态量化
假如上面的式子变成
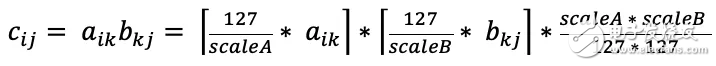
经过线下核算,量化标准被固化为 scaleA 和 scaleB, 表明四舍五入,而且约束在[-127, 127]之内。
这种办法的优点是
节省了 FPGA 资源。
能够很方便地选用跟量化估测共同的练习办法,估测和练习核算数值差错很小,准召率可控。
缺陷是,要求模型练习选用共同的量化办法。不然,核算差错很大,不行承受。
节省 FPGA 资源
同享 DMA 模块
FPGA 片上存储十分受限,关于绝大多数的算子,不行能将输入或许输出完好缓存到片上内存中。而是从内存中一旦读取满意的数据,就开端核算。一旦核算到满意多,就立即把成果写到内存。和内存数据的流式交互是个公共的需求,咱们开发了能统筹一切算子的 DMA 的接口。
只要关于单次核算耗时很长、或调用十分频频的独立使命算子,咱们才为其定制独自 DMA 的模块,获得的收益是,这个算子能够经过多线程调度和其它 FPGA 算子并行核算。这是归纳收益和价值后,做出的以资源换时刻的折衷。
选用 SuperTIle 结构
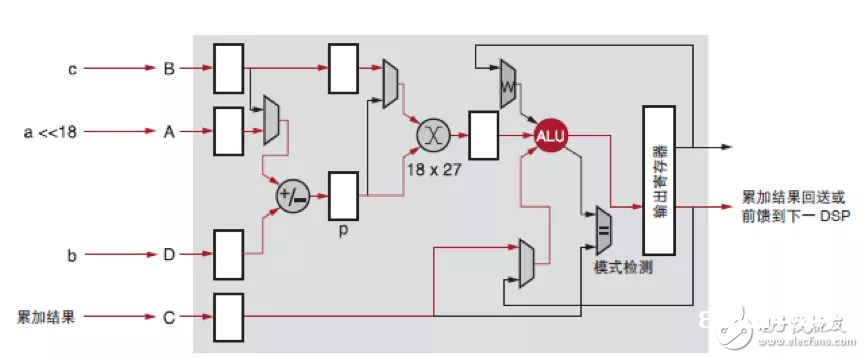
Int8 的核算,能够运用 DSP 或其它逻辑资源来完结。逻辑资源有更多的用处,所以咱们占用 DSP 来完结 int8 的乘累加核算。FPGA 内部的 DSP48E2 能够承受 27bit 的乘数。能够把两个 int8 的乘数摆放在高 8bit 和低 8bit,进行一次乘法后,再两个乘积完好的分离出来。这样,就完结了单个 DSP 一个时钟周期完结了两个乘法,到达了算力倍增的效果。
算子资源复用
经过调查和笼统,将 CNN 首要的算子笼统成3类:
指数类算子
单通道算子
多通道算子
完结了每一类同享核算资源,大大节省了 FPGA 资源的占用,为进步峰值算力、和支撑更多的算子供给了有利条件。

经过调查
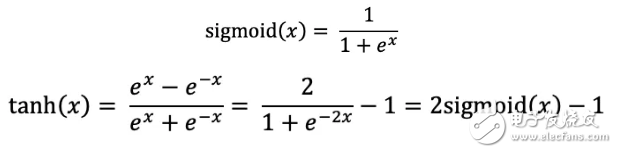
而关于两通道的 softmax,它把两个数 a, b 映射成两个概率,且 Pa + Pb = 1,核算法则是:
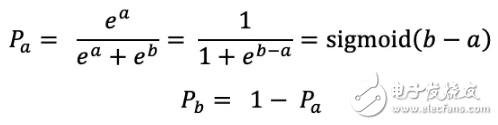
指数核算在 FPGA 中是比较耗费资源的,经过把 tanh 和 softmax 化成 sigmoid 的方法,咱们就完结了一份指数运算资源,支撑3种算子。
Average pooling 能够视为固定卷积核的 depthwise conv。
能够结构额定的卷积核,在上层 SDK 把 average pooling 封装成 depthwise conv 直接核算,这样 FPGA 无需做任何兼容规划,节省 FPGA 资源。
也能够在 RTL 代码中完结转化,这样不需求传递卷积核参数,节省内存带宽。
Elementwise add 的核算方法是两个输入、一个输出,而 depthwise conv 的核算方法是一个输入、一个输出。二者核算资源的复用并不显着。咱们操作两个输入向 FPGA 加载的次序,加载数据的一起完结了两个输入特征图的按行交错,将两个输入交错成一个输入。然后在 RTL 中结构一个[1, 1] T 的卷积核,stride 设置为[1, 2],变成 depthwise conv 的核算方法,运用 depthwise 的核算资源完结核算。
咱们在规划 elementwise add 的时分,笼统度比较高,超出了原始界说的 A + B,扩展成 mA + nB。 其间 m、n 是 SDK 能够自在装备的参数,当m = n = 1,回归到传统的 elementwise add。而取 m = 1,n = -1 时,完结的是 elementwise sub。在 FPGA 无感的状况下,完结了 elementwise add 和 elementwise sub 核算资源的复用。
综上, depthwise convoluTIon, average pooling, elementwise add , elementwise sub 这四种单通道的算子核算资源是复用的。
多通道算子资源的复用,只介绍最要害的乘累加部分。
conv 完结的是3维输入图画(H x W x C)和4维卷积核(N x K1 x K2 x C)的乘加操作。full connecTIon 完结的1维输入数组(长度是C)和2维权重(N x C)的乘加操作。将 full connecTIon 输入数据扩维,输入数组扩展成 H x W x C, 输出扩展成 N x K1 x K2 x C, 其间 H = W = K1 = K2 = 1。 这样 full connection 就被 SDK 封装成了 conv,FPGA 核算时无感。
Deconv 和 conv 是网络中核算量最大的两个算子,核算资源复用收益很大。但它们核算方法上不同很大,直接复用核算资源很困难。咱们在理论进步行打破,完结了通用的资源复用的办法。简言之,SDK 要对 conv 的核算参数进行扩大以兼容 deconv,在核算 deconv 时,需求对卷积核进行分拆、重排,伪装成 conv。FPGA 核算结束后,添加少数逻辑对成果进行润饰。
总结一下,咱们对 CNN 常用的十种算子笼统,只花费三个算子的资源。
异构核算
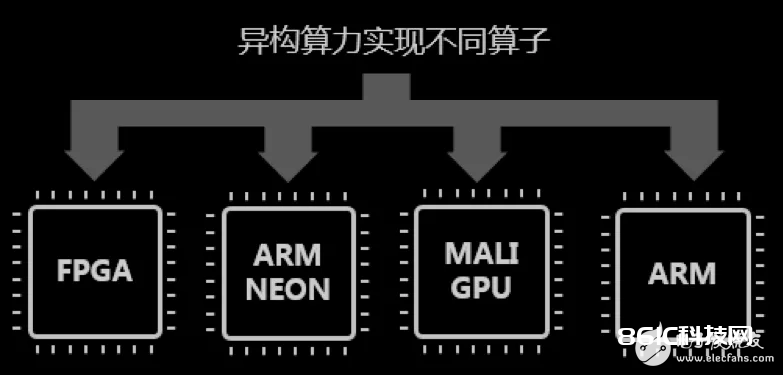
ARM 核算:有些算子,比方多通道的 softmax、concat、split 等,呈现频率很低,数据量不大,对全体帧率影响很小,还有些算子比方 PSRoiPooling、核算区域不确认、数据不能确保对齐,十分不合适 FPGA 加快。把这两类算子放在 ARM 上完结。在 ARM 上对核算影响最大的单个要素是缓存命中率。经过数据重排、改动遍历次序等,进步缓存命中率,能够把表观 ARM 算力进步几十倍。
NEON 加快:选用 NEON 指令能够对多通道的 Softmax 算子有用加快,加快比虽然不及 FPGA,但相关于直接选用未优化的 C++ 的代码在 ARM 上履行,效果能够进步数倍。其它对齐的核算,大多能够经过 NEON 处理器加快数倍。
MaliGPU:咱们现在运用 Xilinx ZU 系列的 FPGA,自带 MaliGPU 400,本来被规划用来显现时烘托,并不支撑 CUDA、OpenCL 等常用库。经过特别的驱动方法,咱们做到能够运用它完结一些受限的逐像素算子。
咱们实践核算运用的硬件资源包含了 FPGA、MaliGPU、ARM 主处理器、ARM Neon 协处理器4种。经过 ARM(主处理其和协处理器)和 MaliGPU 完结对部分算子进行承受,有用缓解了 FPGA 的资源压力。
选用静态量化
而选用动态量化,查找量化标准和进行量化,需求涣散在相邻的两个算子中完结。为了确保精度,中心成果需求以半浮点(float16)方法表明。这带来两个问题:
CPU 并不能直接对 FP16 的数据进行转化或核算,所以需求 FPGA 供给额定的算子,供给快速的 float32 / int8 和 float16 转化。这些额定的算子,是 CNN 自身不需求的,这构成了糟蹋。
Float16 需求的缓存比 int8 大了一倍。糟蹋了 FPGA 的存储资源。
而静态量化,离线供给了固定的量化参数,中心核算成果以量化后的 int8 方法来表明。以上的糟蹋都得以防止。虽然静态量化对模型练习做额定的要求,咱们终究决议切换到静态量化。
节省内存带宽
多算子交融
经过 SDK 将各种参数进行改换和兼并,单个 conv 算子能够完结最多支撑4个算子的组合 conv + batchnorm + scale + relu。
咱们还能够将指数型算子(sigmoid / tanh /两通道 softmax)交融到上面4个算子之后,构成交融5个根本算子的单一交融算子。这依赖于自主开发的 SDK,和 FPGA 规划的算子逻辑。
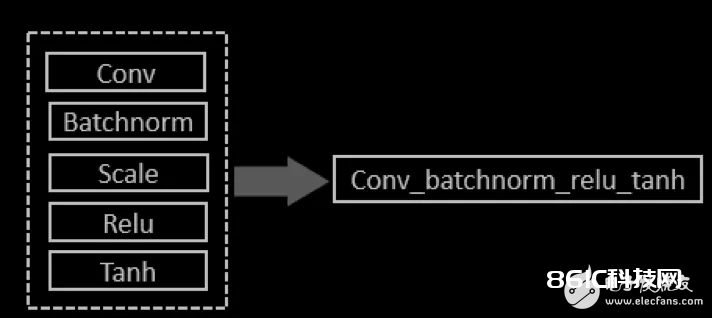
相关于每核算一个算子就把成果回吐给 DDR,这种算子交融大大减少了对内存的读写。有用进步了处理帧率。
静态量化
动态量化中心成果以 float16 表明,而静态量化能够以 int8 方法表明。静态量化相关于动态量化,内存的吞吐量下降,帧率有显着的进步。下图是坚持算力不变,仅仅把中心成果从 float16 变成 int8 后,处理帧率的进步起伏。

静态量化下降了内存吞吐,这也是咱们抛弃动态量化易用性的一个原因。
使命的帧率是峰值算力、各算子算力、支撑的算子品种三个要素复合效果的成果。以上技能现已用到了 ACU 硬件中,把百度 Valet Parking 产品的帧率在数量级进步行了进步。
接下来,咱们会连续发布更多这样的“硬核”技能文章,让更多开发者们愈加详尽地了解 Apollo 自动驾驭背面的技能。