


现代SoC软件一般包含多种运用,从轿车发动机操控等硬件实时运用,到HD视频流等大吞吐量运用。跟着现代SoC向大吞吐量体系的快速开展,处理器内核数量不断添加,宽带互联也越来越多,导致混合体系规划成为应战。在这类体系中完结硬件实时—μs量级呼应,颤动不到1μs,需求细心的归纳考虑剖析和体系区分。跟着SoC的杂乱度越来越高,将来的验证战略也有必要归入考虑规模。
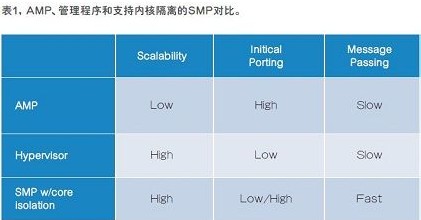
这类体系规划首要有三种办法—非对称多处理(AMP)、办理程序,以及支撑内核阻隔的对称多处理(SMP)(首要的比照见表1),体系规划人员可以从中挑选一种办法来优化混合SoC体系。
非对称多处理
AMP实践是根据物理上不同的处理器内核的多操作体系(OS)端口。一个比如是,在第一个内核上运转专门用于处理实时使命的裸金属OS,在其他内核上运转嵌入式Linux等完好的OS。许多时分,开端将OS导入到内核中十分简略,可是,在发动代码和资源办理上很简单犯错,例如,存储器、高速缓存和外设等。当多个OS拜访相同的外设时,行为会是不确定的,调试起来或许十分耗时。一般要求细心的维护ARM TrustZone等体系结构不受影响。
更杂乱的是,在OS之间传递音讯要求存储器同享,一同选用其他维护手法进行办理。不同的OS之间一般不会同享高速缓存。要通过非高速缓存区来传递音讯,关于整体功能而言,添加了延时和颤动。从可扩展视点看,跟着内核数量的添加,需求进行屡次从头导入,使软件体系结构较差。
监控程序
办理程序是直接在硬件上运转的底层软件,在其上可办理多个独立的OS。开端的导入与AMP类似,而其优势在于办理程序躲藏了资源办理和音讯传递中不重要的细节。缺陷是因为吞吐量和实时功能要求,添加了额定的软件层,导致呈现功能开支。
对称多处理
支撑内核阻隔的SMP在多个内核上运转一个OS,支撑在内部区分内核。一个比如是让SMP OS在第一个内核上分配实时运用程序,在其他的内核上运转非实时运用程序。跟着内核数量的添加,SMP OS可以规划无缝导入,因而,这一办法的可扩展性比较好。一切内核都是由一个OS办理的,因而,内核之间可以在L1数据高速缓存级上传递音讯,通讯速度更快,颤动 更低。
通过内核阻隔,可以保存一个内核用于硬件实时运用,以屏蔽其他大吞吐量内核的影响,坚持了低颤动和实时数据呼应。这样,规划人员可以考虑运用哪一个OS,而不必从头规划简单犯错的底层软件来办理多个OS。因而,这一般是很好的软件体系结构决议。假如从多个OS开端,开端的导入会需求一些支付。可是,从一个SMP体系结构开端会省许多事。
通过SMP优化大吞吐量、实时SoC
根据对各种办法的剖析,支撑内核阻隔的SMP是最好的体系结构,优化了大吞吐量、实时SoC体系。咱们考虑的体系结构与图3的体系类似,其间,I/O数据输入到SoC中,处理器对其进行核算,送回至I/O,满意低颤动和低延时实时呼应要求。此外,SoC包含了多个内核,可一起运转其他吞吐量较大的运用程序。
首要,需求了解一个实时呼应(循环时刻)由哪些组成:
1.从一个I/O,将新数据传送至体系存储器(DMA)。
2.处理器勘探体系存储器中的新数据 (内核阻隔)。
3.将数据仿制到私有存储器(memcpy)。
4.对数据进行核算。
5.将成果仿制回体系存储器(memcpy)。
6.将成果传送回I/O(DMA)。
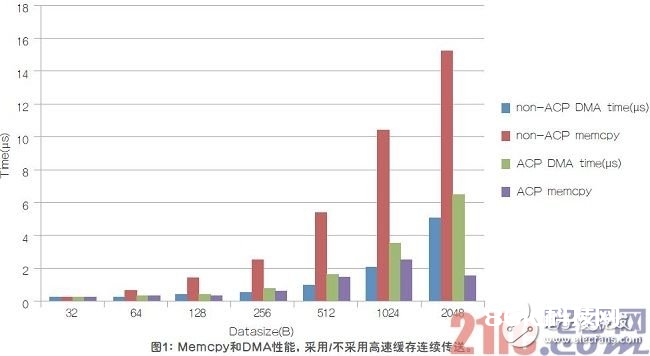
颤动和延时是6个过程的累积,因而,需求优化每一个过程。选用支撑内核阻隔的VxWorks等RTOS,可以在纳秒规模内完结轮询/中止呼应(过程2)。数据核算也是专用的,具有很好的可猜测性(过程4)。因而,咱们的重点是归纳考虑直接存储器拜访(DMA)和memcpy(过程1/3/5/6)。首要有两种办法来传送数据:高速缓存接连传送,以及不支撑高速缓冲接连的传送。这两种办法在DMA和memcpy上的呼应有很大的不同。如图1所示,尽管高速缓存接连传送(运用ARM高速缓存接连端口(ACP))导致DMA需求较长的通路,但处理器只需求拜访L1高速缓存就可以取得所传送的数据。因而,运用高速缓存接连传送的memcpy时刻要少许多,可是DMA功能会有些劣化。关于规划人员而言,因为是直接高速缓存拜访,因而,高速缓存接连传送的延时更短,颤动 更小。
事例研讨:SoC规划最佳实践
可以运用Cyclone V SoC FPGA开发套件,通过参阅规划来演示一个完好的体系。器材在一个芯片中包含了一个双核32ARM Cortex-A9内核子体系(HPS)和一个28nm FPGA。下面总结了硬件和软件体系结构,如图2所示。
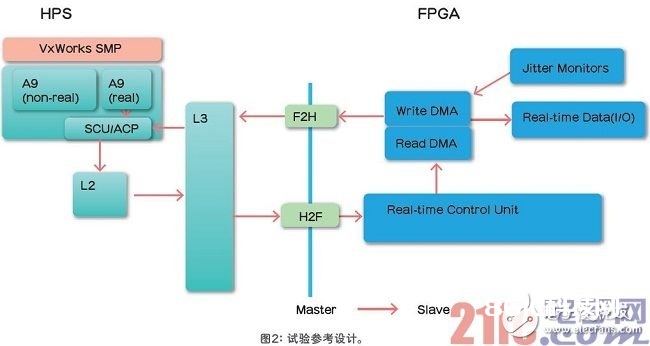
硬件体系结构
·两个DMA,将数据从FPGA I/O传送至ARM处理器,反之亦然。
·两个DMA都衔接至ACP,完结数据在ARM处理器高速缓存的直接传送。
·实时操控单元IP,以尽或许快的办法发动ARM处理器和DMA引擎之间的音讯传递。
·颤动监视器直接勘探DMA信号,收集实时功能和颤动,精度在±6.7ns以内。
软件体系结构
·在双核ARM处理器上的VxWorks实时OS运转在SMP形式下。
·内核阻隔,用于在第一个内核上分配实时运用程序,在第二个内核上分配其他的非 实时运用程序。
·实时运用程序接连从I/O读取数据,核算,然后将成果发送回I/O。
·当接连运转FTP传输并对数据加密时,非实时运用程序加剧了对ARM内核和其它 I/O功能的要求。
成果
在长度不同的数据上运转试验,长度从32 字节直至2,048字节。为了收集循环时刻的直方图,来剖析颤动(最大和最小循环时刻之间的不同),每一长度都要运转数百万次。如图3所示,即使是在第二个内核上运转数据流负载很大的FTP,通过数百万次的测验,延时也在微秒级,而颤动不到300ps。长度不同,会有些颤动摇摆,可是可操控在200ps内,并不显着。
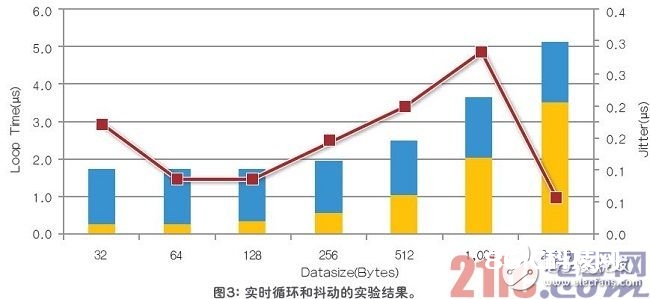
相同的FTP运用程序也运转在VxWorks SMP上,运用了两个内核,速度提高了近2倍。因而,这一办法并没有劣化吞吐量,是吞吐量和硬件实时运用程序的折中挑选。可是,因为对内核进行了硬件区分,不可以灵敏的添加内核数,因而,AMP解决方案也相同有一些劣化。
定论
规划一个支撑大吞吐量和实时运用程序的均衡SoC体系需求进行许多归纳考虑,例如:
·DMA数据传送。
·接连高速缓存。
·处理器内核与DMA之间的音讯传递。
·OS区分。
·软件可以跟着处理器内核数量的添加而进行扩展。
在此次试验中,咱们展现了一个“最佳实践”体系规划,它运用了支撑内核阻隔和高速缓存接连传送的SMP,完结了低延时、低颤动实时功能,一起软件可以扩展运用到未来几代的SoC产品中。






