导言
协方差矩阵的核算是信号处理范畴的典型运算,是完结多级嵌套维纳滤波器、空间谱估量、相干源个数估量以及仿射不变量模式识别的要害部分,广泛使用于雷达、声呐、数字图像处理等范畴。选用FPGA(Field Programmable Gate Array)能够进步该类数字信号处理运算的实时性,是算法工程化的重要环节。可是FPGA不适宜对浮点数的处理,对杂乱的不规矩核算开发起来也比较困难。故现在国内外协方差运算的FPGA完结都是选用定点运算方法。
在充沛使用FPGA并行处理才能的一起,为了扩展数据处理的动态规模,削减数据溢出机率,防止数据切断所发生的差错,进步协方差矩阵的运算精度以及扩展该运算的通用性。
本文以空间谱估量作为研讨布景,研讨了复数据运算和浮点运算的特色,提出了一种适用于任何阵列流型、恣意阵元的根据复数浮点运算的协方差矩阵的FPGA完结计划。
1 求解复数浮点协方差矩阵
以11阵元的均匀圆阵为例,其协方差矩阵的求解计划原理框图如图1所示。
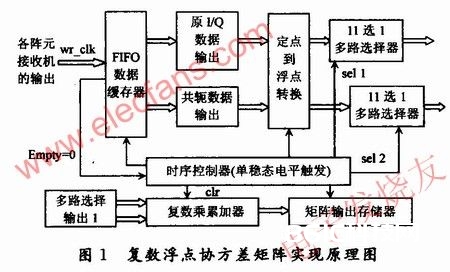
1.1 FIF0数据缓存器
在该规划计划中挑选FIFO作为数据存储器,这是由于一旦多路接收机有数据输出,就会发动FIFO进行存储,从而FIFO的不空信号有用(empty=O),触发后续的矩阵运算;不然,运算中止,全部状况清零,FPGA康复idle(闲暇)状况,等候新的快拍采样数据的到来。
这样能够很便利地操控运算的开端和完毕。矩阵运算所需求的同步时钟需求规划一个类似于单稳态触发器的模块。当检测到empty=‘0’时,就触发一个含有121个clk(关于串行计划而言)时钟信号周期长度的高电平。该高电平与主时钟相与便能够得到运算的同步时钟。
1.2 数据共轭转化
由于测向阵列的输出矢量X(t)是一个复矢量,对其求协方差矩阵需用阵列输出列矢量X(t)与其共轭转置矢量XH(n)对应相乘。如式(1)所示:
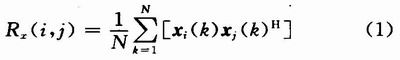
1.3 定点数到浮点数的转化
定点核算在硬件上完结简略,核算速度比浮点核算要快,可是表明操作数的动态规模受到限制,浮点数核算硬件完结比较困难;一次核算花费的时刻也远大于定点核算的花费,可是其表明的操作数动态规模大,精度高。在本规划中,考虑到体系的数据动态规模和运算精度,挑选浮点核算。由于运算数据是直接从接收机I,Q两路通道的A/D变换器的输出取得,为定点数,因而有必要要有一个将A/D采样的定点数据转化为浮点数的进程。规划中将16位定点数转化为IEEE 754规范的单精度格局。32位单精度格局如图2所示,最高位为符号位,这今后8位为指数e(用移码表明,基数f=2,偏移量为127),余下的23位为尾数m。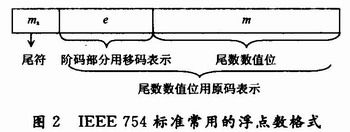
1.4 浮点复数乘累加器
1.4.1 复数乘法器
假设有两个复数别离为a+jb和c+jd,这两个数的乘积为:
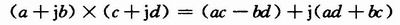
复数乘法器的作业原理如图3所示,其间所用到的加法、减法和乘法器都是根据浮点的运算。值得一提的是,在完结浮点加减法的时分,能够将尾数连同符号位转化为变形补码方式后再进行加减运算。这样做的意图是便利判别数据是否溢出(变形补码判别溢出的规矩是:当两位符号位不一起表明溢出,不然无溢出。不管数据是否溢出,第一位符号位永久代表真实的符号),若溢出,则将尾数右归,指数部分加1,若没有溢出,则将尾数左归(规格化)。浮点乘法相对较简略,对应阶码相加,尾数相乘能够选用定点小数的任何一种乘法运算来完结,只是在限制只取一倍字长时,乘积的若干低位将会丢掉,引进差错。
1.4.2 浮点复数乘累加器
以11个阵元的圆阵为例,完结串行处理计划的浮点复数乘累加器的原理如图4所示,实部和虚部(双通道)的乘累加器模块作业原理相同。
121阶数据缓存器实践上便是121个数据锁存器级联构成的一个移位寄存器,初始状况为零。当浮点复数乘法器有输出的时分,发动数据缓存器与之进行加法操作,121个时钟周期今后能够完结一次快拍采样的矩阵累加。累加清零信号由时序操控器给出,当一切的快拍采样点运算都完毕之后,数据缓存器输出累加成果(即协方差矩阵的运算成果),一起操控器送出一个清零信号,清零121阶数据缓存器。
2 仿真成果
可编程逻辑规划有许多内涵规矩可循,其间一项便是面积和速度的平衡与交换准则。面积和速度是一对对立统一的对立体,要求一个规划一起具有规划面积最小,运转频率最高,这是不现实的。所以根据面积优先准则和速度优先准则,本文别离规划了协方差矩阵的串行处理计划和并行处理计划,并用Altera\stratix\EP1S20F780C7进行板上调试。其调试成果表明,串行处理计划占用的资源是并行处理计划的1/4,但其运算速度却是后者的11倍。
2.1 串行处理计划仿真成果
如图5所示,clk为运算的总操控时钟;reset为复位操控信号,高电平有用;rd为读使能信号,低电平有用;wr为写使能信号,低电平有用;wr_clk为写时钟信号,上升沿触发;q_clk为读时钟信号,上升沿触发;ab_re(31:O)和ab_im(31:O)为乘法器输出的实部和虚部。q_t2为矩阵乘累加模块的同步时钟信号;clkll,state(3:O),clkl和state(3:0)是状况机的操控信号,操控矩阵运算规矩。
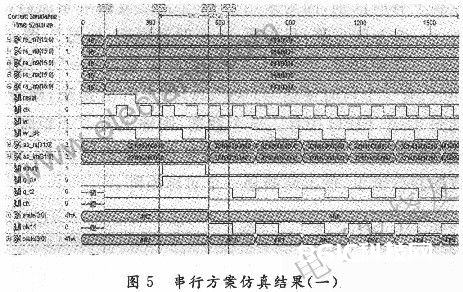
如图5所示,在100 ns时reset信号有用(即reset=‘1’),一切状况清零。从335~635 ns间,写使能信号有用(wr=‘O’)且有两个写时钟信号的上升沿到来,即向恣意一个通道的FIFO中存入两个快拍采样数据,终究输出成果应该有两个矩阵,如图6所示。当FIFO为空时,运算中止,一切状况清零。等候新采样数据的到来。
图5中,在350 ns时,读使能有用(rd=‘0’)且有一个读时钟信号的上升沿到来,所以empty信号存在时刻短的不空(empty=‘O’)状况,捕获到这个信息,便触发单稳态触发器模块,发生具有121个clk时钟周期长度,占空比为120:1的q_clk信号,进行FIFO的读操作。
在350~535 ns时刻段,由于写时钟信号没有到来,所以FIFO为空(empty=‘1’)。从550 ns~24.75 μs时刻段读时钟信号没有上升沿到来,整个规划处于第一个矩阵的运算进程中,即运算一个矩阵所需求的时刻为24.2 μs。与此一起,第二个数据写入FIFO,empty一向处于不空状况(empty=‘O’)。
在第一个矩阵运算完毕之后,即24.6μs时,体系检测到empty=‘0’,开端读数据并触发第二个矩阵运算的时钟操控信号。如图6所示,在24.6μs时,empty=‘1’。FIFO中的第二个数据被读出,处于空状况。从24.85~49.05μs进入第二个矩阵的运算周期。
在仿真时,输人数据为16位的定点数(1+j1;O+jO;2+j2;3+j3;4+j4;5+j5,6+j6;7+j7;8+j8;9+j9;A+jA),输出成果为32位的单精度浮点数。挑选的主时钟周期为200 ns。在实践调试进程中,整个体系能够在50 MHz主时钟频率下正常作业。
2.2 并行处理计划仿真成果
并行计划运算原理与串行计划的相同,只是在时钟操控上有所区别,由于选用了11个浮点复数乘累加器,进行一次矩阵运算,只需求11个时钟周期,如图7,图8所示。在仿真时,设置在写使能信号有用(wr=‘O’)的一起,有3个写时钟信号(wr_clk)的上升沿到来,即别离向22个FIF0中存入3个数据,则输出有3个矩阵。从图7中还能够清楚地看出,运算成果是矩阵的11行数据并行输出,输出成果是一个对称矩阵。
3 结语
在剖析了现在使用于空间谱估量的协方差矩阵运算在硬件完结上的缺乏,如定点核算的数据动态规模小,运算精度不高,且只适用于特定阵列模型和的阵元数,不具有通用性。在此基础上提出了根据浮点运算的通用型协方差矩阵的完结计划。仿真成果表明,本文所提出的完结计划选用的是复数乘法运算,终究成果得到的是复共轭对称矩阵,合适使用恣意的阵列模型和阵元数得到与之相对应的协方差矩阵。这就拓宽了协方差矩阵运算的使用规模,且整个运算进程选用的是浮点运算,进步了整个运算的精度。