ARM的NEON协处理器技能是一个64/128-bit的混合SIMD架构,用于加快包括视频编码解码、音频解码编码、3D图画、语音和图画等多媒体和信号处理运用。本文首要介绍怎样运用NEON的汇编程序来写SIMD的代码,包括怎样开端NEON的开发,怎样高效的运用NEON。首要会重视内存操作,即怎样改动指令来灵敏有用的加载和存储数据。接下来是由于SIMD指令的运用而导致剩下的若干个单元的处理,然后是用一个矩阵乘法的比方来阐明用NEON来进行SIMD优化,最终重视怎样用NEON来优化各式各样的移位操作,左移或许右移以及双向移位等。本节首要介绍当输入的数据巨细不是一个向量巨细的整数倍时,怎样处理剩下的几个元素,如把元素补齐到向量巨细的整数倍的修正处理、堆叠处理办法和单个元素处理办法。
关键字: ARM NEON Cortex-A8 cache 对齐
剩下的元素Leftovers
一般NEON会向量处理从4个到16个元素长度的数据,假如你发现你的数组不是这个这个长度的整数倍,你就需求独自处理那些剩下来的几个元素。如你每次能够运用NEON来加载处理并存储8个元素的数据,可是你的数组有21个元素,你就需求先迭代两次,然后第三次,你只剩下5个元素,此刻应该怎样处理呢?
Fixing Up修正处理办法
有三种处理办法来处理剩下来的元素,这些办法的需求、功能和代码巨细不同,下面次序介绍,从速度最快的办法开端。
Larger Arrays更大的数组
假如改动你要处理的数组巨细,比方添加数组巨细到向量巨细的整数倍,这样就能在最终一次数据处理时也依照向量巨细处理而不会把接近的数据损坏。如上面的比方里,把数组巨细添加到24个元素,这样就能用NEON用3次迭代完结一切的数据处理而不会损坏周边数据。
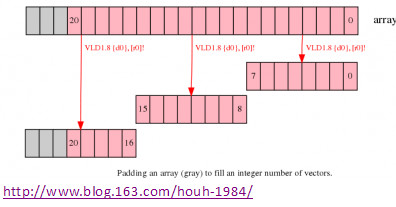
图1. 添补数组到向量的整数个巨细
注意事项Notes
- 分配更大的数组需求更多的存储空间,这会添加相当大的空间假如包括十分多的短数组;
- 在数组后边添补的数据元素需求初始化为一个不会影响到成果的值,例如你要做加法,那这个新元素需求初始化为0以影响核算成果。
- 一些状况下,或许无法初始化填充的数据,不管填充什么都会影响核算的成果;
Code Fragment代码片段实例
@ r0 是输入的数组指针;
@ r1 是输出数组指针;
@ r2 是数组数据的长度;
假定数组长度大于0,是向量巨细的整数倍,而且大于或许等于数组的长度;
add r2, r2, #7 @ 数据长度加上向量长度-1
lsr r2, r2, #3 @ 把数组长度变成向量个数,即除以向量巨细8
loop:
subs r2, r2, #1 @ 削减循环计数器个数
vld1.8 {d0}, [r0]! @ 从数组加载8个元素,从地址r0到寄存器d0,然后更新地址寄存器r0到下一个向量地址;
…
… @ 处理在d0寄存器的数据
…
vst1.8 {d0}, [r1]! @ 把8个成果元素保存到输出数组,更新地址r1到下一个向量
bne loop @ 假如r2不等于0,持续循环
Overlapping堆叠核算
假如进行数据处理的操作适宜的话,能够考虑把剩下部分的元素经过堆叠核算的办法处理,这就会把某些堆叠部分的元素核算两次。如下面的比方里,第一次迭代核算元素0到7,第一次核算5到12,第三次核算13到20。然后第一次核算和第2次核算堆叠的元素5到7就被核算了两次。
arm.com/index.php?app=core&module=attach§ion=attach&attach_rel_module=blogentry&attach_id=419″ rel=”nofollow” >
图2. 堆叠向量,在橙色区域的数据核算两次
Notes需求事项
- 堆叠处理只适用于需求处理的数组长度不会跟着每次迭代而改动的状况,但不适用于每次迭代成果改动的状况,如累加核算,这样堆叠部分的数据会被核算两次;
- 数组内元素的个数至少大于一次完好迭代的向量巨细;
Code Fragment代码片段实例
@ r0 是输入的数组指针;
@ r1 是输出数组指针;
@ r2 是数组数据的长度;
假定数据操作幂等,而且数组长度大于等于一个向量巨细长度。
ands r3, r2, #7 @ 核算每次处理完好个向量后剩下元素个数,运用与操作
beq loopsetup @ 假如剩下元素个数为0,则数组长度是整数个向量巨细,不必堆叠核算,独自处理第一个元素部分
vld1.8 {d0}, [r0], r3 @ 加载数组第一个向量,然后更新数组巨细为剩下元素个数r3内坚持
…
… @ 处理d0寄存器内的输入数据
…
vst1.8 {d0}, [r1], r3 @ 坚持8个元素到输出数组,更新指针,然后开端处理循环
loopsetup:
lsr r2, r2, #3 @ 把数组长度除以8,核算循环迭代次数,若干元素跟第一次迭代的堆叠
loop:
subs r2, r2, #1 @ 削减循环计数器个数
vld1.8 {d0}, [r0]! @ 从数组加载8个元素,从地址r0到寄存器d0,然后更新地址寄存器r0到下一个向量地址;
…
… @ 处理在d0寄存器的数据
…
vst1.8 {d0}, [r1]! @ 把8个成果元素保存到输出数组,更新地址r1到下一个向量
bne loop @ 假如r2不等于0,持续循环
单个元素的核算进程Single Elements
NEON供给了能处理向量里的单一元素的加载和存储指令,用这些指令,你能加载包括一个元素的部分向量,处理它然后把成果保存到内存。如下面的比方,前两次的迭代处理跟前面相似,处理元素0到7以及8到15,剩下的5个元素能够在第三次迭代处理,加载处理并存储单一的元素。
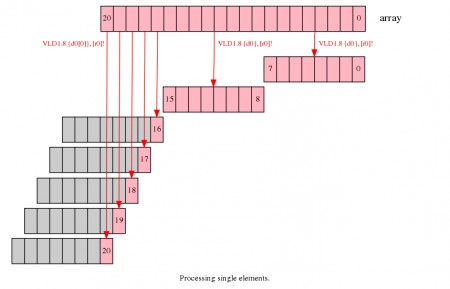
图3. 处理单一的元素实例
注意事项
- 这种办法比前面的两种办法速度要慢,每个元素的处理都需求独自进行;
- 这种的剩下元素处理办法需求两个迭代循环,第一个处理向量的循环,还有处理剩下元素的循环,这会添加代码巨细;
- NEON的单一元素加载只改动方针元素的值,而保存其他的元素不变,假如你向量核算的指令会在一个向量间重复核算,如VPADD,这些寄存器需求在第一个元素加载时初始化。
代码片段
@ r0 是输入的数组指针;
@ r1 是输出数组指针;
@ r2 是数组数据的长度;
lsrs r3, r2, #3 @ 核算向量循环迭代的次数
beq singlesetup @ 假如没有完好的一次迭代向量核算,则跳转到单一元素处理循环
@ 处理向量循环
vectors:
subs r3, r3, #1 @削减循环计数器个数
vld1.8 {d0}, [r0]! @ 从数组加载8个元素,从地址r0到寄存器d0,然后更新地址寄存器r0到下一个向量地址;
…
… @ 处理在d0寄存器的数据
…
vst1.8 {d0}, [r1]! @ 把8个成果元素保存到输出数组,更新地址r1到下一个向量
bne vectors @假如r3不等于0,持续循环
singlesetup:
ands r3, r2, #7 @ 核算单一元素迭代的次数
beq exit @ 假如单一元素核算次数为0,则跳转退出
@ 处理单一元素的循环
singles:
subs r3, r3, #1 @削减循环计数器个数
vld1.8 {d0[0]}, [r0]! @从数组加载单一元素,从地址r0到寄存器d0,然后更新地址寄存器r0到下一个地址
…
… @ 处理在d0[0]内的输入数据
…
vst1.8 {d0[0]}, [r1]! @ 保存单一元素成果到输出数组,更新指针地址
bne singles @假如r3不等于0,持续循环
exit:
其他的考虑
在开端处仍是完毕处
用堆叠核算的办法以及用单一元素处理都能在数组开端处或许完毕处处理,因此代码就要考虑两种完结办法哪种功率高些,哪个更适合你的体系运用。
数据对齐
加载或许存储指令的地址应该对齐到cache line,这样内存的拜访功率更高。这样就需求在Cortex-A8的处理器上至少16字对齐,假如你不能把输入和输出数组的开端地址对齐到16字,你就必须处理开端和完毕数据处理的那若干个元素以使得后续的数据拜访是对齐到cache行的。为了运用内存对齐的办法拜访内存以进步速度,你在运用NEON指令时需求运用比如64或许128或许256等地址限定符来拟定加载和存储指令。你能够比较宣布一个对齐的拜访和非对齐拜访的功能,以下是一直周期的页面Cortex-A8 TRM.
运用ARM来做修正
在运用单个元素处理的状况下,你能够运用ARM指令来进行单个元素的操作,可是一起运用ARM和NEON来拜访同一块区域的内存会下降体系功能,由于从ARM的流水线宣布的写操作会在NEON的流水线完结之后才干进行。因此你要尽量的防止在ARM和NEON的代码里一起拜访同一块内存区域(当然,这同一块内存区域也对应于同一个cache line)