


跟着信息技能的开展,网络通信、信息安全和信息家电产品的遍及,嵌入式MCU正是所有这些信息产品中必不可少的部件。目前国内一些科研院校和半导体公司都在致力于研制自主规划的嵌入式,这对我国的半导体工业、电子产品工业的开展具有重要意义。
这儿描绘了一款自主研制的16位嵌入式微操控器的规划与完结,根据RTL级规划办法运用VerilogHDL进行规划描绘,在规划中,选用硬布线操控办法,削减了面积和功耗,一起MCU兼容了MSC-96指令集,方针是能够使用于实践嵌入式体系项目中。
1 整体规划
1.1 MSC-96体系结构
图1所示为MSC-96体系结构。Intel 8096微操控器是由通用寄存器阵列、算术逻辑单元(RALU)和微程序操控器等模块组成。其选用的是微程序操控办法,需求运用一个片内ROM存储器,因而会形成面积和功耗都会较大。
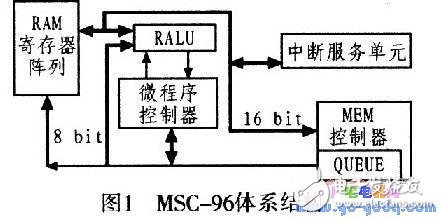
MCU内部的寄存器阵列通过一个操控器和2条总线与RALU相连。这两条总线是8位的A-BUS和16位的D-BUS。DBUS只用于RALU与寄存器之间的数据传输,而A-BUS用作上述传输进程中的地址总线。当MCU通过寄存器操控器拜访片表里寄存器时,A-BUS可作为多路转化的地址/数据总线。
1.2 A8096整体结构
为了削减面积和功耗,A8096选用硬布线逻辑操控办法替代上述的微程序操控器。根据MSC-96的体系结构,A8096首要功用模块包含:IPU(InSTructiON Pre-fetch Unit。指令预取单元)、CU(Control Unit,操控单元)、ALU(ArithmeTIC Logical Unit,算术逻辑单元)、MEM_C-TRL(MEM操控器)、RF_CTRL(寄存器堆操控器)、ISR(Interrupt Service RouTIne unit,中止服务单元)、GPIO(General Purpose Input Out-put,通用输入输出单元)等首要功用部件。其结构如图2所示。

1.3 体系总线
A8096选用3条总线:一条是MEM总线,用于IPU和MEM CTRL对程序空间和数据空间的读写操控;16 bit的数据线,16 bit的地址线,读写信号memrd/memwr;一条是内部寄存器阵列(Register File)总线,用于RF_CTRL对内部寄存器阵列的读写拜访,地址线是8 bit的,数据线为16 bit,读写信号为rf_rd/rf_wr;一条是SFR总线,用于拜访数据空间地址在00H~19H的特别界说的寄存器空间。8 bit的地址总线,16bit的数据总线,读写信号sfrrd/sfrwr。别的IPU和MEMCTR的数据交互是通过8 bit的数据线instr_bus完结的,其作用是从预取指令行列中将指令传给CU单元等。
2 MCU规划与完结
2.1 MCU作业原理
A8096通过IPU(指令预取单元)指令预取,并存放在预取指令行列中,CU(操控单元)从IPU指令行列中取指并进行译码,发生操控时序等信号。ALU单元、RAM操控器、MEM操控器等部件中均有译码模块,根据当时指令和当时指令周期主动作业。如:RAM操控器在加法指令的相应周期取操作数送往ALU单元,ALU在相应周期接纳数据,然后进行运算并将成果输出。
2.2 MCU发动进程
在上电复位时,MCU处于复位态(rst信号有用)。复位时,IPU单元中的指令行列清空(empty信号有用),总线处于闲暇态,IPU马上进行指令预取动作,程序空间的首地址(2080H)指令即被取人指令行列,随后行列空信号(empty)无效,一起指令被发送出去(instr_bus)。在复位一起,操控单元(CU)的取指信号(codefetche)即一向有用,在指令行列空信号empty无效后(在empty无效之前CU一向等候),指令即通过instr_ bus进入了CU,指令操作码被存入了指令寄存器,如图3中instr寄存器更新为加法指令的操作码74。至此,MCU完结了复位、主动取指操作,并开端往下履行该指令,IPU单元也会继续进行指令预取操作。

2.3 指令履行进程
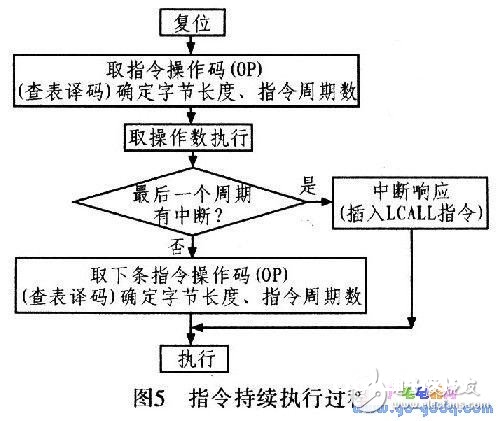
在A8096中,有两级指令预取概念:一级是指令预单元IPU运用总线闲暇从程序空间不断预取指令存入指令行列中;一级则是指令履行进程中的指令预取,当一条指令履行到终究一个时钟周期时,CU单元就会发送取指信号,进行指令履行级的预取指动作,下一条指令的操作码即被预取出来(指令行列为空时需等候),并马上进行译码确认指令的字节长度和指令履行周期数。
如图4所示,在加法指令的终究一个周期(cycle=05),CU单元取指信号codefetche有用,则下一条指令的操作码(6C,乘法操作码)被预取出来,一起进行查表译码确认其指令字节长度和指令周期数,随后操作码被存入指令寄存器instr中(此刻,指令周期计数器cycle又从01开端计数)。后边乘法指令的操作数也会不断被取进来履行,直到乘法指令终究一个周期时,又将下一条指令的操作码预取进来。

需求阐明:codefetche为取操作码信号,datafetche为取操作数信号。在指令终究一个周期时若有中止请求,则刺进LCALL指令进行中止处理,读取下一条指令。其流程如图5所示。
2.4 指令译码进程
在MCU规划进程中,首要完结对各条指令的指令剖析作业,确认每个周期该做的动作,然后各部件根据指令剖析表进行相关的指令译码(RAM操控器只译RAM要做的动作,ALU只译ALU要做的动作)。进程描绘如下:在预取操作码时,CU单元对操作码进行译码确认指令的字节长度(nr_bytes)和指令周期数(nr_cycles)。然后CU根据指令字节长度(nr_bytes)取操作数,其他部件根据指令和当时指令周期(curcycle)履行相应的指令操作。表1为加法指令剖析表,下面以加法指令的译码进程来阐明整个译码流程:

1)加法指令 ADD OPl OP2(将OPl+0P2成果写入OPl中);其方针码格局为:ADD OP2 OPl,其间OPl和OP2均为操作数地址。
2)0周期 实践指上一条指令的终究一个时钟周期,此周期codefetche取指信号有用,IPU单元将指令送入CU单元确认了指令周期和指令长度。
3)l周期 取操作数信号datafetche有用,op2(地址)进来,被送入RAM地址线,发读信号(从RAM寄存器阵列取操作数2)。
4)2周期 操作数2被取入,并存入ALU中的a寄存器;此周期取操作数信号datafetche有用,opl(地址)进来,被送入RAM地址线,发读信号。
5)3周期 操作数l被取入,并存入ALU中的b寄存器;加法器马上进行a+b运算。
*周期 将加法成果放到RAM数据线上,地址线=opl,发写信号。将加法成果写回到opl中,并根据成果对PSW进行处理。
7)5周期 无动作,用于写回操作的进程。
3 验证成果
3.1 仿真验证
芯片的功用与结构规划,仅仅规划流程的一部分,为确保终究规划成功,有必要对其全面仿真与功用验证。对MCU的测验办法如下:1)功用模块的单元测验,验证模块的功用正确性,包含接口时序等。2)体系集成测验,首要编写简略的机器码测验向量进行开始调试:然后运用编译器写汇编程序,编译成二进制机器码进行程序功用测验。在集成测验中,编写汇编测验程序,用编译器编译成机器码,在Cadenee NC下运转这些测验程序进行仿真测验。对每条指令均测验了其各种寻址办法,且测验程序主意向DEBUG寄存器写测验成果,以便利调试。通过杂乱的测验和不断批改,验证成果显现MCU指令履行的正确性。
3.2 FPGA验证
运用的FPGA器材是StraTIxⅡ型号为EP1S40F780C7。归纳成果显现:A8096运用3 565个LE(LogIC Element)。时序剖析成果:A8096能够运转在49.93 MHz的时钟频率下。A8096占用FPGA资源散布状况如图6所示。

4 定论
本规划中,选用RISC技能中的硬布线操控逻辑,有利于削减MCU面积、下降功耗以及进步MCU履行功率,FPGA完结标明其只占用了3 565个LE单元,作业时钟可达50 MHz。一起该MCU具有很强的扩展性与实用性,使用领域广泛,可便利与定时器、串行通讯接口(I2C)、串行外围接口(SPI)、模数(A/D)转化器等外围功用单元组成各种嵌入式体系,彻底具有实践使用价值。






