


怎样制造一个简略的16位CPU,首要咱们要清晰CPU是做什么的,想必各位都比我清楚,百度的材料也很全。。。。。
假如想要制造一个CPU,首要得了解下核算机的组成结构(或许核算机的替代品,由于并不是只需核算机有CPU,现在的电子产品都很先进,许多设备例如手机、洗衣机乃至电视和你家的轿车上面都得装一个CPU),数字电路根底,还最好有点编程的根底(当然,没有也不要紧,这些常识都很简略取得,各种书上面都会提到,而且在接下来的进程中我会提到这些常识)
咱们要完结的是一个RISC指令集的CPU,而且咱们最终要自己为这个CPU规划指令而且编码。
首要咱们来听个故事,关于CPU的诞生的故事:
日本客户期望英特尔协助他们规划和出产八种专用集成电路芯片,用于完结桌面核算器。英特尔的工程师发现这样做有两个很大的问题。榜首,英特尔现已在全力开发三种内存芯片了,没有人力再规划八种新的芯片。第二,用八种芯片完结核算器,将大大超出预算本钱。英特尔的一个名叫特德?霍夫(Ted Hoff)的工程师仔细剖析了日本同行的规划,他发现了一个现象。这八块芯片各完结一种特定的功用。当用户运用核算器时,这些功用并不是一起都需求的。比方,假如用户需求核算100个数的和,他会重复地输入一个数,再做一次加法,总共做100次,最终再打印出来。担任输入、加法和打印的电路并不一起作业。这样,当一块芯片在作业时,其他芯片或许是闲暇的。
霍夫有了一个主意:为什么不能用一块通用的芯片加上程序来完结几块芯片的功用呢?当需求某种功用时,只需求把完结该功用的一段程序代码(称为子程序)加载到通用芯片上,其功用与专用芯片会彻底相同。
经过几天的思考后,霍夫画出了核算器的新的体系结构图,其间包括4块芯片:一块通用处理器芯片,完结一切的核算和操控功用;一块可读写内存(RAM)芯片,用来寄存数据;一块只读内存(ROM)芯片,用来寄存程序;一块输入输出芯片,完结键入数据和操作指令、打印成果等等功用。
看完这个故过后,能够总结:CPU是一种用来替代专用集成电路的器材(这仅仅我的了解,不同人有不同了解,这个就智者见智了,我在接下来的比如中也会阐明我的主意)。
然后考虑如下这个比如:
例1-1:
mov eax,0
repeat:inc eax
jmp repeat
例1-2:
int main()
{
unsigned int i = 0;
while(1)
i++;
}
例1-3:
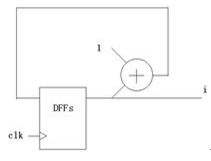
能够看到,以上三个比如都发生了一个从0不断添加的序列,而且前两个比如会一向加到溢出又从0开端(这个取决于核算机的字长也便是多少位的CPU,eax是32位寄存器所以必定是加到4294967295然后回0,而后边那个c程序则看不同编译器和不同渠道不相同),后边那个比如则看你用的是什么样的加法器和多少个D触发器
那问题就来了,我假定要一个递减的序列怎样办呢?前两个比如很好解说,我直接改代码不就得了:
例2-1:
mov eax,0
repeat:dec eax
jmp repeat
例2-2:
int main()
{
unsigned int i = 0;
while(1)
i–;
}
你只需求悄悄敲击键盘,修正了代码之后,它就会如你所愿的履行。
可是后边那个比如怎样办呢?或许你现已想到办法了:如例2-3所示。
例2-3:
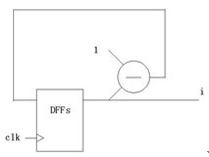
问题就来了,你在键盘上敲两下可不能改动实践电路!上面(例1-3)中是个加法器,可是跑到这儿却变成了减法器(例2-3)!
这样的话,你就得再做一个电路,一个用来算加法,一个用来算减法,可是两个电路代表你得用更多的电路和芯片,你花的钱就得更多,要是你不能一起运用这两个电路你就花了两份钱却只干了一件事!
这个问题能被处理吗?答案是能!
请看例3:
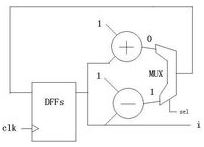
这个比如中运用了一个加法器一个减法器,没比上面的电路省(显着。。。。莫非你想用减法器做加法器的功用?不或许吧!当然,加上一个负数的补码的确便是减去一个数,可是这儿先不考虑这种问题),多了一组多路器,少了一组D触发器。总的来说,优势仍是显着的(两块电路板和一块电路板的不同)。
而sel信号便是用来挑选的(0是递加,1是递减)。
假如咱们把sel信号看做“程序”的话,这个电路就像一个“CPU”能依据“程序”履行不同的“操作”,这样的话,经过“程序”(sel信号),这个电路就能够完结复用。
依据上面的定论,我以为(仅仅是个人以为啊~):程序便是硬件电路的延伸!
而CPU的根本思想,我以为便是这样的。
接下来咱们就剖析CPU的结构和各个部件,然后完结这个CPU。
什么是单周期CPU,什么是多周期CPU,什么是RISC,什么是CISC
首要咱们得有时钟的概念:这个问题欠好解说啊。。。。。。能够了解为家里边的机械钟,上上电池之后就会滴答滴答走,而它“滴答滴答”的速度便是频率,滴答一下用的时刻便是周期,而人的作业,下班,吃饭和学习文娱都是依照时钟的指示来进行的(熬夜的网瘾少年不算),一般来说,时钟信号都是由晶体振荡器发生的,0101替换的信号(低电平和高电平)。
数字电路都需求一个“时钟”来驱动,就像演奏交响乐的时分需求一个指挥家在前面指挥相同,一切的人都会跟着指挥的拍子来演奏,就像数字电路中一切的部件都会跟着时钟节拍作业相同。
如下是一个抱负的时钟信号:(留意是抱负的)。
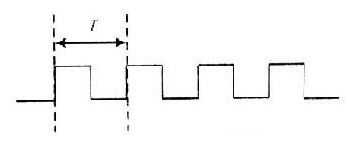
当然,实践的时钟信号或许远没有这么抱负,或许上升沿是斜的,而且占空比也或许不是50%,有颤动,有偏移(相对于两个器材),或许由于导线的寄生电容效应变得走形。
上面那段假如没听懂也不要紧~~~横竖便是告知你,实践的时钟信号测出来必定没这么规范。
而cpu的作业频率,是外频与倍频的积(cpu终究怎样算频率,其实这个我也不太清楚呵呵),由于cpu是经过外部的晶振发生一个时钟信号,然后再经过内部的电路(锁相环),倍频至需求的频率。当然,有人问,为什么要这么费事呢?直接在电路外边做个时钟晶振能发生那么高的时钟信号就能够了嘛,这个是能够的,在某些简略的体系上(例如51单片姬)便是这样的,可是核算姬的cpu比较杂乱,由于一些原因所以有必要要做到cpu内。
下面简略说一下CPU的两种指令集:CISC和RISC。
说下我的观点(个人观点,如有过错还请高手纠正):
RISC是Reduced Instruction Set Computer,精简指令集核算机,典型比如是MIPS处理器。
CISC是Complex Instruction Set Compute,杂乱指令集核算机,典型比如是x86系列处理器(当然现在的x86指令仍是最初cisc的指令,可是实践处理器的结构都现已变成了risc结构了,risc的结构完结流水线等特性比较简略,在核算机前的你假如用的是intel某系列的处理器,则它运用的指令集看上去仍是像cisc的指令,可是实践上你的cpu的结构现已是risc的了)。
一般CISC的处理器需求用微指令合作运转,而RISC全部是经过硬连线完结的,也便是说,当cisc的处理器在履行你的程序前,还得先从别的一个rom里边读出一些数据来“辅导”处理器怎样处理你的指令,所以cisc功率比较低,而risc是彻底经过部件和部件之间的衔接完结某种功用,极大的提高了作业功率,而且为流水线结构的呈现供给了根底。cisc的寄存器数量较少,指令能够完结一些比较特别的功用,例如8086的一些寄存器:
ax,bx,cx,dx,si,di等;段寄存器有:cs,ds,es,ss等。相对的指令功用比较特别,例如xlat将bx中的值作为基地址,al中的值作为偏移,在内存中寻址到的数据送到al傍边(以ds为段寄存器)
而risc的处理器则通用寄存器比较多,而指令的功用能够稍弱小一点,例如:
以nios嵌入式处理器来阐明,nios处理器有32个通用寄存器(r0~r31),而指令功用相对x86的弱一些,而且x86进行内存拜访是直接运用mov指令,nios处理器读内存用的是load,写内存用的是store,
二者呼应中止的办法也不相同,举一个典型的比如,x86的处理器将中止向量表放在了内存的最低地址(0-1023,每个中止向量占四个字节),能包容256个中止(以实形式的8086举例)呼应中止时,将中止号对应的地址上的cs和ip的值装入到cs和ip寄存器而将本来的地址保存,而且保存状况寄存器然后进入中止处理,而risc则具有一个一起的中止呼应函数,这个函数会依据中止号找到程序向体系注册的函数的地址,而且调用这个函数。一般来说而是用的cisc指令的长度是不定的,例如x86的xor ax,bx对应机器码是0x31d8、而push ax是0x50、pop cx是0x59。而risc的指令确是定长的,例如32位。
假如还有不清楚的。。。。。自行百度,要了解这些概念需求一点时刻
一个CPU的根本结构以及必要组件
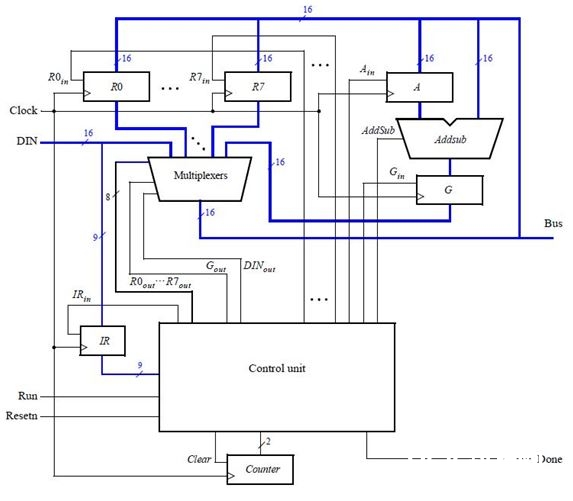
这个比如引证自DE2开发板套件带的光盘上的Lab Exercise 9,咱们从图中能够看到,一个CPU包括了通用寄存器组R0~R7,一个ALU(算术逻辑单元),指令寄存器IR,操控器(一般这部分是一个有限状况机或许是用微指令完结),还有便是数据通路(图中的连线)。当然真实的CPU不或许只包括这么一点点组件,这是一个模型CPU,也便是说仅仅阐明CPU的原理,真实杂乱的CPU要涉及到许多杂乱的结构和时序,例如虚拟形式需求运用一些特别的寄存器、为了支撑分页需求运用页表寄存器等,为了加快内存的拜访需求运用TLB,加快数据和指令的拜访而运用data cache和instruction cache等等。。。。。当然,那都是后边该考虑的,所以咱们先从这个简略的部分开端讲起。
比如中能完结如下指令:

mv指令将Ry的数据搬运到Rx中,mvi将当即数D搬运到Rx傍边,add将Rx和Ry的和放到Rx中,sub同上,不过履行的是减法。
首要来阐明mv指令是怎样履行的:mv指令将Ry的值移入Rx寄存器傍边,这两个寄存器都是由一组D触发器构成,而D触发器的个数取决于寄存器的宽度,就像32位机、64位机这样,那他们的寄存器运用的D触发器的个数便是不相同的。当履行mv rx,ry时,中心的多路器(图中最大的那个multiplexer)选通Ry,让Ry寄存器驱动总线,这个时分Bus上的信号便是Ry的值;然后再看到R0~R7上别离有R0in~R7in信号,这个信号是使能信号,当这个信号有用时,在上升沿此触发器会将din的数据输入,所以提到这儿咱们必定想到了,这个时分Rx触发器上的Din信号就会变为有用,这样过了一个时钟周期后Ry的值就被送到了Rx傍边。
与mv指令相似,mvi指令也将一个数据送入Rx傍边,只不过这次的数据存在指令傍边,是当即数,所以Rx的Din信号会变为有用,而多路器会挑选IR中的数据,由于mvi指令的当即数存在指令傍边。而且进行必定处理,例如扩展等。
add指令会让多路器先挑选Rx,然后Ain信号有用,这样一个时钟周期后,Rx数据被送入Alu的A寄存器傍边,这时多路器挑选Ry,addsub信号为add以指示ALU进行加法操作,Gin有用让G寄存器寄存运算成果,然后再过一个时钟周期G傍边的数据便是Rx与Ry的和,这时多路器再挑选Gin,Rx的Din有用,过了一个时钟周期后数据就被寄存到Rx傍边了。
sub的进程与add差不多,不过addsub信号是sub指示ALU进行减法。
我做的CPU模型
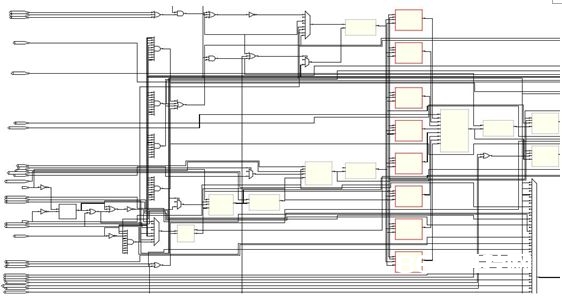
下面我就将我做的CPU模型的RTL网表发出来,代码我会上传的,可是这个还只能进行仿真,由于规划的时分理念有问题,呈现了异步规划,而且呈现了将状况机的输出作为另一个器材的时钟端的过错,所以这个模型只能用于仿真。我用的synplify pro归纳出的RTL,而状况搬运图是用的Quartus的FSM Viewer截下来的。
首要是整个体系的概览:
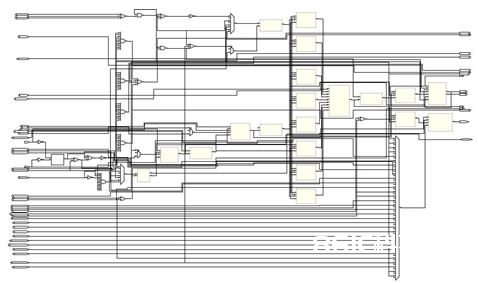
这个比上面的那个简略模型杂乱多了吧!可是别忧虑,其实这个仅仅上面的那个CPU变得略微杂乱了一点,这个和上面那个不同的当地还有:这个CPU是一个多周期CPU而上面的Lab Exercise是一个单周期的CPU
下图是程序计数器(PC),也便是常见x86处理器里边的ip(instruction poiniter):
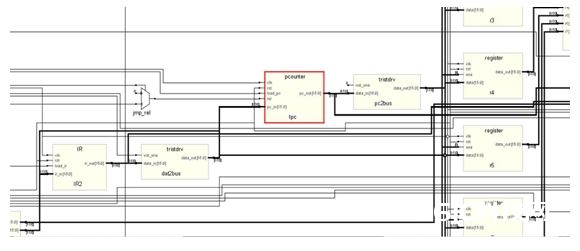
赤色部分便是pc了,后边是一个三态桥,衔接到了总线上面,这儿的数据有时分是要送到地址总线,用于寻内存中的数据,以便完结Instruction Fetch进程。有时分又要送到通用寄存器的数据端,用于将pc的值送到其他寄存器。
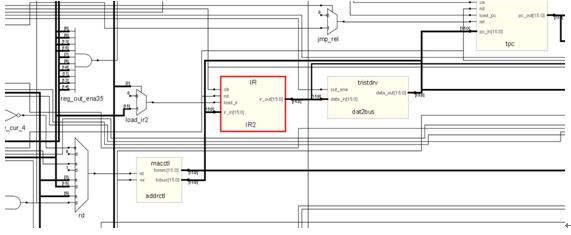
下面这个是IR(Instruction Register),这个是多周期处理器的典型特征,由于处理器在榜首个周期里边将机器码从内存取出,然后寄存到这个寄存器里边,后边的几个状况都是经过这个寄存器里边的数据作为指示履行操作的。
下面介绍一下ALU,ALU是Arithmetic Logic Unit,即算术逻辑单元,这个设备的效果是进行算术操作和逻辑操作。典型的算术操作例如:1+1=2,11×23=253,而典型的逻辑操作例如:1 and 1=1,0 or 0 = 0,13=8这种归于逻辑操作。

而从图中咱们也看得到,ALU的输出用一根很长的线衔接到了后边,参阅整个CPU的图的话,会发现这些线连到了通用寄存器上面,这是为了让运算的成果寄存回去,例如你用add eax,1的时分,eax的值被加上1然后放回eax,所以ALU的运算成果要用反应送回到通用寄存器,而ALU的输入也应该有通用寄存器的输出。
下面再介绍ADDRMUX:

这个部件是用来挑选地址的,右边的输出是CPU的地址总线,而CPU的地址总线就现已送出CPU了(也便是你能够在芯片的外表上看到引脚了),CPU的地址总线是送到存储器的地址端的,而现代的核算机体系实践上是适当杂乱的,所以其实你家的核算机上CPU是经过北桥芯片拜访内存的(当然也有将内存操控器做到CPU里边的)左面是地址的来历,地址的来历即有通用寄存器,也有程序计数器,还有一个是直接从IR里边送出,这是由于有的当即数里边也包括内存地址信息。
最终介绍通用寄存器:
通用寄存器的效果便是用来保存中心值或许用于运算,例如
add eax,2
适当于eax+2然后送回eax。
最终介绍一下状况机,这个部分便是CPU的“魂灵”,假如说有了上面那些部件CPU有了一副“躯体”的话,这一部分便是CPU的“魂灵”了:
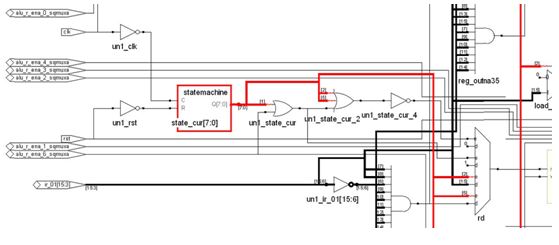
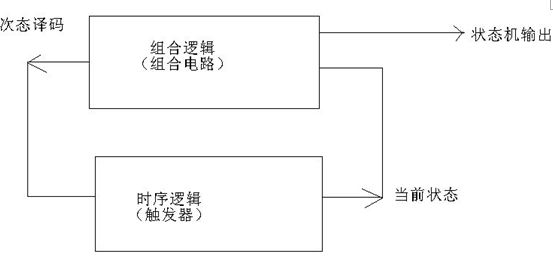
状况机根本上与体系一切的组件都衔接到一起了,由于上面所说的一切动作的履行,都需求状况机的操控,状况机其实便是由一部分触发器构成的记忆电路和别的一部分组合逻辑构成的次态译码电路构成,还有依据当时状况和输入进行译码的部分用于操控各个部件,下面是教科书上的典型FSM结构:
而咱们用的状况机状况搬运图如下:
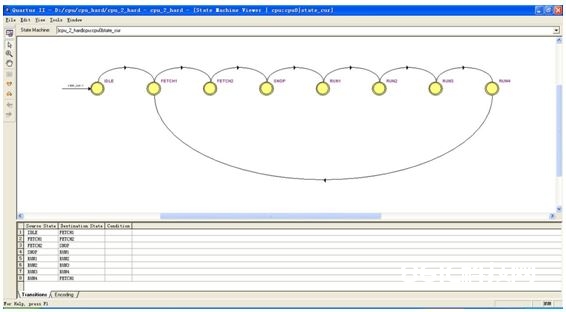
由于这个处理器规划的很简略,所以没有呈现许多状况,当处理器阅历完以上的状况之后,处理器就履行完了一条指令。
有的CISC的处理器用微指令进行操控,效果和状况机附近,这种结构呈现在一些比较陈旧的处理器上,由于那个时分的规划东西和办法没有现在的先进,所以往往改动硬件是困难的和高本钱的,所以用微指令的话,做好了硬件的结构,要是需求改动只需修正微指令就好了,而现在的电子技术很兴旺,规划东西也很齐备,所以就有许多直接经过硬连线完结的处理器。
好马配好鞍,有了处理器,咱们就得给它配上一个好的程序,下面咱们就用自己规划的处理器进行求和,从1加到100,由于咱们没有规划编译器,也没有规划汇编器,所以程序只能用机器码写出,示例程序如下:
咱们无妨先写出程序的汇编代码:
mov [ADDR],r0;r0 = 0
mov r1,100
lop:add r2,r1
sub r1,1
cmp r1,0
jz ext
mov r4,4
jmp r4(lop)
ext:mov [ADDR],r2
jmp $
先将内存中寄存数据的地址清零,这样才干寄存等下送来的成果,然后将r1寄存器存入循环次数(也便是求和的上限)。然后再将r1的值加到r2中来,r2其实便是放求和的寄存器,最终咱们会将r2中的值送到内存中的某个地址寄存的。
然后将r1减去1,看看是否为0?假如为0则阐明求和完毕了,假如不是0则阐明还要持续,完毕后程序就跳到ext部分将成果寄存到内存中某个地址(比如中给的是49152也便是二进制的1100000000000000b),最终jmp $是为了让程序停在这一行,避免程序跑飞(跑飞的程序损害很大!有或许吧数据当代码或许把代码当数据!)
转换成VerilogHDL言语如下:
module memory
(
input [15:0] addr,
inout [15:0] data,
input rw
);
reg [15:0] data_ram[0:16’b1111_1111_1111_1111];
integer i;
initial begin
for (i = 0; i = 16’b1111_1111_1111_1111; i = i + 1)
data_ram = $random();
data_ram[0] = 16’b1000000100000000; //mov [ADDR],r0;r0 = 0
data_ram[1] = 16’b1100000000000000; //ADDR
data_ram[2] = 16’b1000000010001000; //mov r1,100
data_ram[3] = 100; //100
//data_ram[2] = 16’b1110011001000000;
data_ram[4] = 16’b0010000100010001; //lop:add r2,r1
data_ram[5] = 16’b1110000011001000; //sub r1,1
data_ram[6] = 16’b0000000000000001; //1
data_ram[7] = 16’b1110000000001000; //cmp r1,0
data_ram[8] = 16’b0000000000000000; //0
data_ram[9] = 16’b1110011010000000; //jz ext
data_ram[10] = 16’b0000000000000011; //+3 offset(ext)
data_ram[11] = 16’b1000000010100000;//mov r4,4
data_ram[12] = 16’b0000000000000100;
data_ram[13] = 16’b0110011001100000;//jmp r4(lop)
data_ram[14] = 16’b1000000100000010;//ext:mov [ADDR],r2
data_ram[15] = 16’b1100000000000000;//ADDR
data_ram[16] = 16’b1110011001000000;//jmp $
data_ram[17] = 16’b1111111111111110;//-2 offset($)
/*data_ram[0] = 16’b1000000010000000; //mov r0,imm
data_ram[1] = 16’b0011111111111111; //imm
data_ram[2] = 16’b0000000001111000; //mov r7,r0
data_ram[3] = 16’b1000000010011000; //mov r3,0
data_ram[4] = 16’b0000000000000000;
data_ram[5] = 16’b1000000010100000; //mov r4,code of jmp r5
data_ram[6] = 16’b0110011001101000; //jmp r5
data_ram[7] = 16’b0000000101011100; //mov [r3],r4
data_ram[8] = 16’b1000000011110000; //mov r6,[0]
data_ram[9] = 16’b0000000000000000; //[0]
data_ram[10]= 16’b1000000100000110; //mov [255],r6
data_ram[11]= 16’b0000000011111111;
data_ram[12]= 16’b0110011001011000; //jmp r3
*/
end
always @ (addr or rw or data)
if (rw)
data_ram[addr] = data;
assign data = rw ? 16’hzzzz : data_ram[addr];
endmodule
规划中CPU外围还需求一个内存设备(Memory),我用HDL对其建模,初始化的时分每个内存地址上对应的数据都初始化为随机的,然后只需从0开端的一系列地址被初始化为我写的代码,机器码对应的汇编指令在注释中现已给出。
然后是成果,成果应该是r2从0改动到5050(1+2+3+……+100=5050)
而r1则从100改动到0,改动到0后程序将进入死循环,中止在jmp $那一条。这是仿真开端的时分:
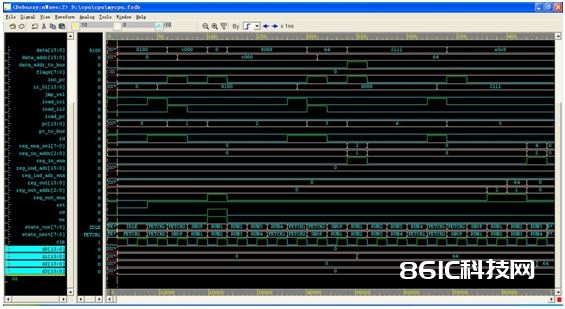
咱们能够看到初始化后,d0~d7都变成了0,这是r0~r7寄存器的Q端,而state_current和state_next则是状况机的现态和状况机的次态,cpu的各个部件都经过这个状况机遭到操控。状况名呈现的次序和上面的FSM Viewer的连线次序是相同的。
而且咱们能够看到,d2从0改动到了0x64也便是十进制100,阐明现已履行了榜首次加法了。
再来看看仿真完毕:

这时分d1改动到了0而d2改动到了0x13ba(十进制的5050),阐明程序现已在咱们规划的处理器里边运转而且成功的得出了成果!
最终给出一些我用到的指令(跟x86的很像):
add dst,src 将src和dst相加而且送到dst寄存器中
mov [addr],src 将src的值送到以addr位地址的内存单元
sub dst,src 将dst减去src而且送到dst中去
cmp dst,src 将dst减去src 然后不送到dst中 只改动标志位
jz dst 当zf=1时(即前次的算术操作成果为0)则跳转到dst中去
最终再提一下:
我是用synplify归纳的电路,然后用debussy+modelsim仿真的,
相关材料请参阅:
CPU逻辑规划,朱子玉,李亚民著
Lab Exercise 9出自DE2的开发光盘






