


导言
H.264编码算法杂乱,其硬件完结包含很多模块。H.264编码器往往选用软硬件协同规划:在宏块级及以下,运算量巨大,用软件往往无法完结实时编码,适用于用硬件完结;而在宏块级以上,是一些图画信息打包的作业,运算量小,且随视频序列的不同而不同,为了确保编码器的通用性和灵活性往往用软件完结。软硬件协同规划技能是SoC的首要技能之一,但一起它也使SoC芯片的规划和SoC规划的杂乱度大大提高。在这种情况下,仿真和验证就成为了影响项目进展的瓶颈,往往占整个芯片开发周期50%~80%的时刻。为了缩短SoC验证时刻,依据FPGA的原型验证(包含硬件原型和软件原型)现已成为SoC规划流程前期阶段的常用手法。
OR1200以及其他许多的与之配套的IP核由Opencores安排担任开发和保护,功用强大,软硬件开发工具彻底,选用免费和开源的授权战略,能够自由地获取源代码,并且大多都通过了ASIC验证,现已遭到学术界和工业界越来越多的重视。
为了建立适用于H.264视频编码器的SoC验证渠道,本文首要做了以下几项作业:
① 选用OR1200微处理器作为SoC体系的操控中心,通过Wishbone总线互联规范将Opencores安排发布保护的相关IP核集成在方针SoC体系上,构成了开始的SoC验证渠道。
② 选用台湾友晶科技公司发布的500万像素图画视频收集模块,为H.264视频编码体系供给原始视频数据,并依据H.264规范的要求,在视频收集模块中加入了RGB到YUV色彩空间转化模块,以及逐行输入/恣意宏块次序输出的多端口SDRAM操控器(简称为“多端口SDRAM操控器”)模块。
③ 在所构建的SoC验证渠道上移植了μC/OSII体系以及μC/TCPIP协议栈,使H.264视频编码体系生成的数据流输出到通用处理器终端,作进一步的验证。
1 相关技能简介
1.1 OR1200微处理器以及Wishbone总线
OR1200是一种32位、标量、哈佛结构、5级整数流水线的RISC处理器,支撑Cache、MMU和根本的DSP功用。在300 MHz时,能够供给300 DMIPS和300M次32位×32位的DSP乘加操作的才能。OR1200定坐落嵌入式、移动和网络使用环境。
Wishbone总线规范是一种片上体系IP核互连体系结构。它界说了一种IP核之间公共的逻辑接口,减轻了体系组件集成的难度,提高了体系组件的可重用性、可靠性和可移植性。
Opencores安排通过ASIC或FPGA验证的开源IP核大多都支撑Wishbone总线协议。
1.2 H.264/AVC视频编码规范
H.264/AVC规范是迄今最新的一套视频编码规范,它与以往的MPEG2规范比较,码流节省了50%以上。H.264规范中所用的编码技能首要有:帧内猜测、运动估量、整形改换和环路滤波等。
H.264规范以宏块(16×16巨细的像素块)为单位进行编码。所以它的数据输入是以宏块为单位的像素块,输出是通过了猜测编码、改换编码以及量化和熵编码之后的比特流数据。
1.3 TRDBD5M图画收集模块
TRDBD5M图画收集模块中的选用Micron公司出产的CMOS传感器MT9P031。它具有以下特性:低功耗,逐行扫描图画传感器;最高支撑到2 592×1944@12fps;12位A/D转化器;支撑摄像形式(viewfinder)和快照形式(snapshot);曝光时刻可调;双线串行接口(I2C总线接口)等。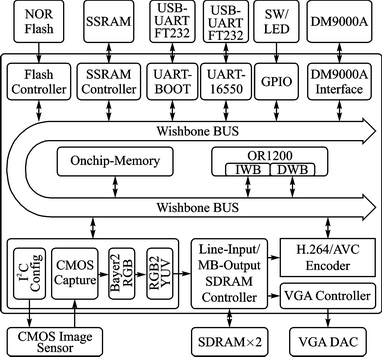
图1 SoC验证渠道全体结构
2 SoC验证渠道的全体结构
如图1所示,SoC验证渠道首要包含OR1200处理器、片上RAM操控器、SSRAM操控器、Flash操控器、UARTBOOT模块(用于发动)、UART16550模块(用于显现信息)、GPIO模块、DM9000A操控器、图画收集模块、双端口SDRAM操控器和VGA操控器。
OR1200微处理器是整个验证渠道的操控中心,依据体系的需求和节省的准则,裁去了OR1200中的指令缓存器(%&&&&&%)、数据缓存器(DC)和存储器办理单元(IMMU和DMMU)。SoC渠道中另一个重要的模块便是片上存储器(OnchipMemory)。片上存储器数据拜访才能强,功耗低,可是容量有限,只能完结代码量比较小的特定功用(如硬件初始化、CPU发动引导等)。当完结这些操作后处理器就会跳转到主存储器SSRAM的地址空间履行代码。
在其他的外设模块中,UARTBOOT模块只带有一个Wishbone主端口,用于操控CPU的发动和程序下载,它不需求分配地址。其他模块的地址空间分配情况如表1所列。
表1 SoC体系的地址空间分配
在图1所示的IP核中,除了以下几个模块外均可从Opencores网站上免费取得: UARTBOOT模块是为了在验证进程中愈加方便地更新下载软件代码和对SoC渠道进行操控,需求自主规划;图画收集模块可参阅友晶科技公司的参阅规划,可是其收集到的数据为RGB格局,需求转化为H.264编码器所需求的YUV格局;此外,因为图画收集模块内部的MT9P031图画传感器是逐行扫描的,而H.264编码器是以宏块次序进行编码的,因而SDRAM的操控器需求从头进行规划,以满意逐行写入和按宏块读出的要求。
之前有很多人对构建依据嵌入式软核的SoC体系作了研讨,本文要点介绍与H.264编码器验证相关的自主规划的模块上。
3 多端口SDRAM操控器
逐行输入/恣意宏块次序输出的多端口SDRAM操控器的全体结构如图2所示。
图2 逐行输入/恣意宏块次序输出的多端口SDRAM操控器结构
3.1 读写端口和读写裁定器
图2中有一个读端口和一个写端口,别离用于H.264编码器读出数据和图画收集模块写入数据。其实还有一个用于VGA显现的读端口,其时序与图画收集模块的写时序相同,都是逐行扫描,在此处略去了。
在读写裁定器(ReadWrite Arbiter)中处理来自读端口的读恳求和来自写端口的写恳求。写恳求的优先级高于读恳求的优先级。写端口由写缓存器(WE_FIFO)和写地址生成器(WE_Addr Generator)组成。WE_FIFO的深度为512字(每个字32位,存一个像素),当图画收集模块在WE_FIFO中写够256个字之后,就会建议一次写恳求。写地址生成器每完结一次写恳求之后便会添加256,地址添加的次序与CMOS图画传感器的扫描次序相同。
读端口由读缓存器(RD_FIFO)、读地址生成器(RD_Addr Generator)、读状况机(RD_FSM)和行计数器(Line_Cnt)组成。RD_FIFO的深度为256字,载入宏块地址(addr_load)的指令宣布后,RD_FSM就进入了作业状况(read_stat信号为1)。一起,读地址生成器现已依据宏块的水平方位(mb_num_h)和笔直方位(mb_num_v)核算出了宏块地点SDRAM中的基地址。当RD_FSM处于作业状况时,读恳求一向有用,假如此刻写恳求无效,就会建议一次长度为16的突发读传输,从SDRAM中读取16个像素数据到RD_FIFO。当完结一次读传输之后,读地址生成器会主动加一行的长度(可装备,此处为800),也便是指向当时宏块下一行的基地址处。与此一起,ReadWrite Arbiter模块会检测写恳求是否有用,假如有用则优先建议长度为256的突发写传输,等写传输完结后再完结下一次长度为16的突发读传输。如此,当完结16次突发读传输后,所读宏块的数据也就彻底写入到RD_FIFO中了,此刻,RD_FSM由作业状况转为搁置状况,等候下一次的宏块读恳求。
当RD_FIFO中的数据数量(rd_usedw)不为零时,H264编码器即可从RD_FIFO中读取数据。当读完256个数据,即一个宏块的数据后,rd_usedw的值变为零,一个宏块数据也便读完了。
3.2 SDRAM指令生成器和指令裁定器
SDRAM指令生成器(Command Generator)首要效果是依据SDRAM的操控时序生成SDRAM接口处的操控指令,这些指令是有或许发生冲突的。指令裁定器(Command Arbiter)的效果便是对指令生成器发生的指令进行裁定。
SDRAM的初始化进程可分红初始化推迟、预充电、改写、设置形式寄存器4个阶段,这4个阶段由一个初始化计数器(initial timer)操控。SDRAM指令生成器依据初始化计数器的值会发生初始化推迟(initial)指令、预充电(precharge)指令、改写(refresh)指令和设置形式寄存器(load_mode)指令。其间,改写(refresh)指令也能够在SDRAM的作业进程中依据改写计数器(refresh timer)的值发生。这是因为SDRAM的特性要求每64 ms就要对SDRAM的一切行改写一遍。因为此规划中SDRAM作业在主动预充电形式,所以说预充电指令也只会在初始化进程中呈现。
指令生成器还会依据ReadWrite Arbiter传过来的读写恳求发生读写(read/write)指令。读写(read/write)指令的优先级是最低的,当SDRAM操控器处于初始化进程,或许正在履行改写指令时,指令裁定器就会让读写恳求一向等候更高优先级的指令履行结束。此外,因为SDRAM是作业在fullpage形式,需求依据写或读的突发长度发生突发停止指令。突发停止指令依据读计数器(write timer)和写计数器(read timer)的值发生,它的优先级低于改写(refresh)指令,却高于读写(read/write)指令。
4 SoC渠道的软件支撑
参照参阅文献[1],规划了DM9000A的操控端口,并在所规划的SoC渠道上移植了μC/OSII实时操作体系和μC/TCPIP协议栈。这是为了方便把H.264编码器所生成的比特流数据传送到PC机端作进一步验证。
5 试验成果
规划了一个H.264编码器模型,它首要完结的功用便是模仿H.264编码器与SDRAM操控器接口处的读时序,从SDRAM中读取数据。一起,它也带有一个Wishbone从接口,能够把读取的数据传送给OR1200微处理器,OR1200微处理器再通过网口把图画数据传送到PC机,以验证所读取的数据是否正确。使用Wishbone总线功用模型(BFM)在ModelSim SE 6.5f环境下对所规划的模块进行了RTL级的仿真,验证计划结构图如图3所示。
图3 多端口SDRAM操控器验证计划
此外,对整个SoC体系选用Altera公司的Cyclone II系列FPGA EP2C70F896C6进行了归纳,并在台湾友晶科技公司的DE270开发板上完结。整个渠道的所占用资源为:逻辑单元10 662个,寄存器4 689个,存储器418 104位。
将图画收集模块的时钟设为25 MHz,SDRAM操控器的时钟设置为100 MHz,其他各个模块均运行在50 MHz。前述办法把从SDRAM操控器中以宏块为次序收集到的YUV图画数据通过网口传输到PC机,在PC机端YUV图画数据转化成正常的图画次序,把Y重量以灰度位图的格局显现,并与VGA显现器中所显现的图画(RGB通道都输入改换后的Y重量)进行比照。
结语
本文依据OR1200微处理器规划了一种面向H.264视频编码器的SoC验证渠道,在集成了常用的各类IP核的基础上,要点对与H.264编码器特性相关的多端口SDRAM操控器进行了规划。通过RTL级以及FPGA验证,所规划的渠道能够满意H.264编码器软硬件协同验证的各种要求,可大大缩短H.264编码器的开发时刻。






