


本规划在Altera Cyclone II EP2C35F672C6芯片上完结多软核体系,旨在运用FPGA芯片的并行处理结构以及两个Nios II软核处理器间的并行处理和协作,进步数字图画处理体系的功用。
1 CSC MegaCore IP核
Altera视频图画处理组合是Altera公司供给的一组用于开发视频和图画处理的MegaCore IP核。这些MegaCore IP在触及图画处理和显现的运用中有着广泛运用。这些IP核的功用包含:色彩空间转化、色度重采样、伽玛校对、二维FIR滤波器、二维中值滤波器等[1]。
色彩空间是在三维坐标系下准确表明各种色彩的三维线性空间。不同的色彩空间选用不同的基色:RGB色彩空间选用红、绿、蓝三种色彩;CMY色彩空间选用青、品红、黄三种色彩。不同的硬件设备运用不同的色彩空间,例如:核算机显现器运用RGB色彩空间,数字电视运用YCbCr(亮度色度)色彩空间。将图画数据在运用不同色彩空间的硬件设备间传输时,一般都需求进行色彩空间的转化[2]。色彩空间转化(CSC)MegaCore供给了灵敏且高效的方法将图画数据从一个色彩空间转化到另一个色彩空间。
在两个不同的色彩空间进行图画数据的转化时,需求供给一个特定的、具有12个系数的转化矩阵。该矩阵中的系数由进行转化的两个色彩空间决议。例如:din_0、din_1、din_2为被输入的像素在原色彩空间下的坐标,[x0,x1,x2,…,x11]为转化矩阵的系数,dout_0、dout_1、dout_2为输入像素经转化后在方针色彩空间下的坐标,则核算方法如下:
dout_0=x0×din_0+x1×din_1+x2×din_2+x3
dout_1=x4×din_0+x5×din_1+x6×din_2+x7
dout_2=x8×din_0+x9×din_1+x10×din_2+x11
2 CSC MegaCore IP核与Nios II体系的接口规划
本规划的CSC MegaCore IP具有两个Avalon端口:一个只写的Avalon从端口,用于接纳Nios II软核处理器通过Avalon总线传来的输入数据;另一个Avalon主端口,将通过CSC MegaCore IP处理后的数据通过Avalon总线写到存储器中。
完结上述两个Avalon接口的功用,需求CSC MegaCore IP对外供给如下几个必备的Avalon总线信号:reset、clock信号用于体系复位和时钟信号;write、writedata信号用于只写的Avalon从端口;write、writedata、address信号用于Avalon主端口(用于Avalon主端口和用于只写的Avalon从端口的write、writedata是不同的信号,仅仅称号相同)。
因为定制的CSC MegaCore IP没有供给Avalon主端口需求的address信号,所以在本规划中需求添加地址生成逻辑功用。添加该功用有两种方法:第一种方法是对由定制主动生成的CSC MegaCore IP的顶层规划进行更改,在CSC顶层规划文件对外供给的接口中添加address信号,并且在CSC顶层规划文件中参加生成address信号的VHDL代码。另一种方法是用VHDL言语完结一个接口,CSC MegaCore IP只向该接口供给与运用相关的信号,address信号由在该接口规划文件中的VHDL代码生成。
本规划对两种规划方案都进行了测验,终究选用了第二种方法。因为独自建立一个接口一方面能够处理address信号的生成问题,另一方面建立该接口文件能够使规划的层次愈加明晰且具有灵敏性和通用性。
建立这样一个接口后,能够将该接口封装为SoPC自界说组件参加Nios II体系中。这样,CSC MegaCore IP就成为了Nios II体系的外围组件,在规划中与Nios II体系处于同一个顶层。并且,因为Altera视频图画处理组合中其他的IP核都具有与CSC MegaCore IP相似的对外接口[1],这样一个接口的建立也处理了Altera视频图画处理组合中其他的IP核与Nios II体系的衔接问题。
3 多软核体系的规划
现在,跟着业界对核算机芯片的组织和体系结构研讨的不断深入,简略地通过进步体系时钟频率、添加Cache容量以及处理器指令的超支量化和流水化等方法完结体系功用进步的战略现已抵达了报答减小点。传统方法对体系功用的进步遇到了瓶颈,有学者现已指出,在单一处理器的条件下,体系功用的进步大致正比于复杂度进步的平方根[3]。
跟着SoPC技能的开展,规划者遍及选用了一种新办法来改进功用:在同一芯片上组织多个软核处理器并带有大的同享Cache。同一芯片上多个处理器的运用,亦称为多核(multiple cores)。在FPGA中选用多个软核处理器,依据时刻和功耗要求区分使命,能够更高效地运用器材的资源、进步器材的处理功率,然后进步体系全体功用。
硬件资源同享是多核体系的强壮功用之一,在多核体系中最遍及的同享资源是存储器。同享存储器的数据从端口需求与同享存储器的软核处理器的数据主端口衔接。假如某一处理器正在对同享存储器的特定区域进行写操作,而一起另一个处理器正在对同一区域进行读或写操作,则很或许呈现数据过错。因而,在同享存储器时需求通过运用Mutex核或Mailbox核告诉其他处理器何时正在运用同享资源,以便处理器之间不会彼此搅扰。
图1为本规划中两个Nios II软核处理器与同享存储器的衔接框图。其间:SDRAM为同享的程序存储器,用于寄存两个处理器的代码;Flash存储器为同享的发动存储器;On_chip_memory是运用片上资源完结的双口RAM,在体系中是同享的数据存储器,用于寄存图画数据。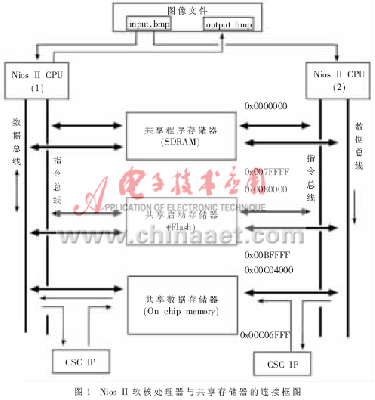
因为两个Nios II CPU运用同一个SDRAM作为程序存储器,因而需求用SoPC Builder供给的存储器分区功用来指定每个Nios II CPU运用的存储器区域。SoPC Builder的分区功用运用处理器的反常地址来界说不同处理器之间代码寄存的分界,每个处理器的反常地址用来决议处理器代码寄存的基地址,其末地址由下一个反常地址或存储器的末地址决议。每个Nios II CPU有5个首要的代码段需求被链接到存储器中,它们分别是: .text、.rodata、.rwdata、heap和stack段。在对程序存储器分区时,有必要为每个处理器的heap和stack段供给满足的地址空间,不然heap和stack段或许溢出,从而损坏处理器的代码运转。
本规划中的两个Nios II CPU还同享了一个Flash存储器,作为发动存储器。与程序存储器相似,在多Nios II软核处理器体系中,每个处理器有必要从自己独立的存储区域发动,多个处理器不能从同一非易失存储器的同一地址发动。SoPC Builder对发动存储器供给了与程序存储器相似的分区功用,用处理器的复位地址来界说不同处理器之间发动代码的分界。
在本规划中,多软核体系的一切硬件资源通过SoPC Builder衔接矩阵的互联状况如图2所示。Mutex核用于两个Nios II CPU对On_chip_memory的互斥拜访。两个Nios II CPU通过SoPC Builder中的衔接矩阵与这些资源相衔接,完结了资源同享。此外,本规划中每个Nios II CPU都有独立的cpu_timer(计时器)、custom_comp(自界说CSC MegaCore IP接口)外设。

图2 多软核体系中硬件资源通过衔接矩阵的互联状况
Nios II IDE具有在片上对多处理器一起进行调试的才能。Nios II IDE multiprocessor collection支撑在FPGA片上对多软核体系的软件进行调试。Nios II IDE下载软件代码到每一个处理器,然后运转软件。在multiprocessor collection中不同处理器的发动并不是在同一个时钟周期开端的,只需一个处理器对应的代码下载结束,该处理器就开端履行代码。
运转在两个Nios II处理器上的软件通过硬件Mutex核和谐对同享片上数据存储器的拜访。运转在两个Nios II CPU上的程序各担任一半的图画数据处理使命,并将处理后的图画数据写入同享数据存储器中。最后由一个Nios II CPU将成果数据从同享缓存中读出,并输出到成果文件中。
此外,软核处理器上运转的代码通过Altera公司供给的Altera Host Based File System文件体系对存储在核算机上的文件进行读写操作。Altera Host Based File System文件体系与Altera Zip Read-Only File System只读文件体系比较,能够对文件进行写操作,愈加契合本规划的需求。参加Altera Host Based File System后即可在代码中运用ANSI C对存储在核算机上的文件进行拜访,代码如下:
FILE*fp_bin=NULL;
fp_bin=fopen(″/mnt/host/hostfs_read_binary.bin″,″r″);
fread(buffer,1,BUF_SIZE,fp_bin);
for(i=0;i P>
{
printf(″%X″,buffer[i]);
}
规划中进行读/写的文件是BMP位图文件。BMP位图文件由四个部分组成:位图文件头、位图信息头、调色板数据和图画数据区。为了对规划进行简化,假定处理的BMP位图文件为非紧缩且没有调色板的位图文件。在这类文件中图画数据区开端于0036h,运用ANSI C中的fseek( )函数即可读到图画数据实体。
4 多核体系与单核体系的功用比照
因为本规划为多软核体系,为了与单Nios II软核体系进行比较,在软件规划中参加了监测软件履行时刻的代码。对不同像素数的图画进行处理时,单核体系与多核体系的程序履行时刻如表1所示。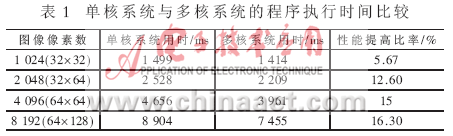
对表1中的数据进行剖析可知,因为在多核体系中,CPU之间进行通讯需求必定的时刻开支,在待处理数据量不大时,如1 024像素,单Nios II软核体系(单Nios II 软核CPU带一个CSC MegaCore IP)与双Nios II软核体系(双Nios II软核CPU带双CSC MegaCore IP)在处理耗时上的不同并不显着。当处理的图画数据量增大时,双Nios II软核体系对功用的进步逐步显现,如图3所示。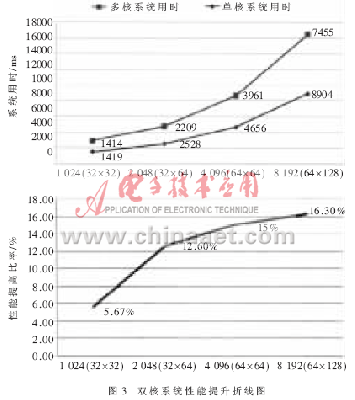
以一幅64×64的BMP位图的处理时刻为例,双核体系的处理时刻为3 961 ms,与之装备相同的单核体系的处理时刻为4 656 ms,多软核体系的功用进步约为15%。
通过对Quartus II软件归纳陈述进行剖析,单核体系对FPGA片上的逻辑单元(LE)占用为17%,多核体系对FPGA片上的逻辑单元(LE)占用为27%,多占用了10%的逻辑资源。因而,能够说在规划顶用器材的逻辑资源换取了程序履行时刻,并且体系功用的进步量是逻辑资源消耗量的1.5倍,达到了规划的预期方针。
本规划根据FPGA完结了图画色彩空间转化的多核体系。运用SoPC Builder软件完结硬件体系的建立,成功地将硬件体系下载到DE2开发版,并且在软件规划中完结了对同享数据存储器的拜访操控以及程序履行时刻的监测。为CSC MegaCore IP核与Nios II体系间规划的接口使得本规划具有必定的灵敏性,CSC MegaCore IP核能够用Altera视频图画处理组合中的任一个IP核替换。
本规划运用多个软核(包含两个Nios II软核处理器和两个CSC MegaCore IP)并行对图画进行色彩空间的转化。与单核体系比较较,多软核体系功用有较大进步且没有过多地占用逻辑资源。






