


摘要:为便利单片机对AT24C512中的数据进行体系化办理,在介绍AT24C512根本结构和作业原理的基础上,依照PC机文件办理的思维完成 AT24C512的文件体系,进步数据办理的功率。 关键词:AT24C512 单片机 文件体系 数据办理 在由单片机构成的数据收集体系及智能仪器仪表傍边,往往有很多数据要保存。跟着测控体系数字化的开展,人们对数据存储提出了更高的要求,因而用于存储数据的存储器容量也越来越大。可是,在增大数据存储量的一起,人们也希望能更快捷高效地操作其间的数据(包含阅读、增加和删去等),即像PC机上办理数据相同简略易行。但是,单片机以及用于保存数据的芯片自身并没有供给这种功用,为此,需求开发一种用于办理单片机数据的有用办法。本文在汲取PC机文件办理思维的基础上,以AT24C512为例,结构了一种类似于文件体系的用于办理单片机数据的办法,大大进步了数据操作的功率。 1 AT24C512介绍 AT24C512是Atmel公司出产的64KB串行电可擦的可编程存储器,内部有512页,每一页为128字节,任一单元的地址为16位,地址规模为 0000~0FFFFH。它选用8引脚封装,具有结构紧凑、存储容量大等特色,能够在2线总线上并接4片芯片,特别适用于具有大容量数据存储要求的数据收集体系,因而在测控体系中被很多选用。 AT24C512的封装如图1所示,各引脚的功用如下: ①A0、A1——地址挑选输入端。在串行总线结构中,如需衔接4个AT24C512芯片,则可用A0、A1来区别各芯片。A0、A1悬空时为0。 ②SDA——双向串行数据输入输出口。用于存储器与单片机之间的数据交换。 ③SCL——串行时钟输入。一般在其上升沿将SDA上的数据写入存储器,而在下降沿从存储器读出数据并送往SDA。 ④WP——写保护输入。此引脚与地相连时,答应写操作;与VCC相连时,一切的写存储器操作被制止。假如不连,该脚将在芯片内部下拉到地。 ⑤VCC——电源。
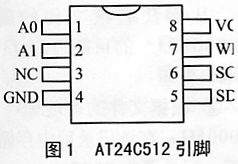
GND接地。NC悬空。 (1)与单片机接口 由于AT24C512沿用了AT24C系列的接口特性,因而与单片机的衔接也可沿用传统办法。一般A0、A1、WP接VCC或GND,SCL、SDA接地单片机的P1口,即可完成单片机对AT24C512的操作。 (2)设备选址 在对AT24C512开端操作前,需求先发一个8位的地址字来挑选芯片以进行读写。设备地址字格局如图2所示。其间“10100”为固定的5位二进制;A0、A1用于对多个AT24C512加以区别;R/W为读写操作位,为1时表明读操作,为0时表明写操作。 (3)写操作 AT24C512的写操作有写字节和写页两种办法。写字节时一般在向AT24C512发送设备地址字并接到应对信号后,还需求发送2个8位地址来挑选要写数据的地址。AT24C512接纳到这个地址后会应对一个零信号,然后接纳8位数据进来,并再回来一个零应对信号。 在写页办法时,AT24C512能够一次性写入一页128字节。其初始化进程与写字节的办法根本相同。不同的是:当写入一个数据字节后,单片机不发间断情况,而是在应对信号后接着输入127个字节;每一个字节接纳完毕后,AT24C512则照样输出一个零应对信号。 (4)读操作 读操作有当时地址读、随机读、读串三种办法。其初始化进程根本与写操作相同,只是在设备挑选字中的最低位要改成读罢了。在当时地址读操作办法时,内部数据的地址将保持在最终的读写操作地址加1上,直到读到最终字节后又回到最开端的方位。而随机读操作之前先要向AT24C512写入一个字节地址,然后才能读。读串操作既能够是当时地址读,也能够是随机地址读。当单片机接纳到一个数据字后,会回应一个应对信号。AT24C512在接纳到应对信号后会将地址加 1,接着输出下一个字节。当单片机接纳到数据但不送应对信号时,读进程完毕。 2 文件体系构成 为了有用地办理AT24C512中的数据,笔者效法PC机中的文件办理机制,为AT24C512结构了一个简略的文件体系。考虑到测控体系的实时性要求和硬件资源的有限性,选用了二级树形目录安排。 为了办理数据便利 ,把AT24C512的物理空间划分为1024个逻辑页,每页64字节。依照文件体系的需求,把AT24C512的悉数空间划分为三部分:数据区,占用最终的960页;页面分配区,占用中心的30页;目录区,占用前面的24页。 (1) 数据区 AT24C512最终面的960页作为数据区,其序号从0开端编号。该区作为文件数据的存储区域,在寄存文件数据时,从该区内分配若干页,每次存储一页。 (2)页面分配区 页面分配区记载了数据区每一页的分配情况。该区中每2字节组成一个记载项,共有960个记载项(30%26;#215;64/2)。记载项从0开端编号,每一个记载项对应着数据区相应页的运用情况。

在实践运用中,一个文件的数据往往大于64字节,这样一个文件的数据区中需占用多个页。但跟着文件的增删,数据区的闲暇空间呈现不接连的情况,因而数据区的分配并不能确保接连,而是依据当时数据区的运用情况来决议某一部分文件内容应该放在哪一页上。为了把这些涣散的数据有机衔接起来,把记载项依照链表的方式安排起来,每个文件对应着一个链表,链表中每个结点为一个记载项,记载项的内容为下一个记载项的编号,最终一个记载项的内容为0FFFFH,表明链表完毕。把这些记载项对应的页面衔接起来就构成了一个文件的完好数据。 别的,假如记载项的内容为0EEEEH,表明其对应的数据页未分配。 (3)目录区 目录区用来存储文件的首要信息。依据这些信息能够知道文件名、文件生成的日期以及文件的数据在数据区中的存储首地址。文件目录项的结构如下: ①文件名。文件名由4字节双BCD码构成,在生成该文件时由键盘输入数字(硬件上键盘只供给了数字键)作为文件名,并由程序主动把它们转化成双BCD码。在需求显现时,再把它们分解成8字节单BCD码供显现。 ②文件生成日期。占用4字节,依照双BCD码的格局存储,如20H、04H,03H、20H则表明2004年3月20日。日期可由键盘输入或经过时钟芯片获取。 ③文件首地址。指示在给该文件分配空间进,分配给它的第一个数据页的序号,即它对应的链表的第一个记载项的编号。 目录区共占用24页。由于每个文件信息只占用10字节,则在此文件体系中,最多可存储153(24%26;#215;64/10)个文件。目录区、页面分配区和数据区的逻辑关系如图3所示。 以图3为例,阐明该文件体系怎么获取文件数据: ①在目录区中依据文件名找到包含该文件名的目录项,然后获取该文件的特点及其首地址。如文件“00000103”的日期为2003年11月24日,其首地址为0005H。 ②依据文件的首地址,在页面分配区中找到该记载项0005H。在该记载项中存储的值为0007H,可知该文件的下一记载项为0007H。 ③同理,可得到文件的后续记载项为0008H、0009H、000BH,直到从000BH记载项中读到0FFFFH。此刻表明这是最终一项,不需再持续找后继项了。 ④至此,可知文件“00000103”的数据分为5部分存储在数据区中,别离存储在0005H、0007H、0008H、0009H、000BH页中。只需按序到数据中读取这些中的数据,并衔接起来,就构成了该文件的悉数数据。 ⑤同理,文件“00000001”在数据区中运用了0002H和0003H两页,文件“00015671”只运用了数据区第000AH页。 3 体系程序规划 依照上述的文件体系结构,体系可经过目录区和页面分配区对AT24C512的悉数数据实时文件化办理。在办理进程中,最首要的操作是增加文件和删去文件。 (1)增加文件 增加文件的首要作业是为新文件寻觅存储空间,其寻觅过程如下: ①在目录区中寻觅空方位。若目录区现已存满(最多存153个文件),则向用户陈述并间断程序;不然,记载该方位(记为MyFile)。 ②核算文件数据需占用的页面数,记为My Page。 ③在页面分配区中寻觅并计算标志为空的记载项,其内容为0EEEEH。若其数目小于MyPage,则向用户陈述,并间断程序。 ④在MyFileA方位填写文件名和日期,并把找到的第一个空记载项的序号填入,作为该文件的首地址。 ⑤顺次在找到的空记载项内填入下一空记载项的序号,最终一个空记载项填入0FFFFH。 ⑥从文件首地址开端,依照文件链表顺次把数据写入数据区相应的页。 (2)删去文件 删去文件的首要作业是收回该文件所占用的空间,以便将来分配给其它文件。 ①在目录区中寻觅到该文件,提取出其首地址,记载First。随后,把该文件所占用的目录区的首字节清为0FFH,表明该目录项闲暇。 ②在页面分配区中找到First记载项,撮出其内容,记为Next。随后,把First记载项的内容改写为0EEEEH。 ③First=Next,重复②,直至Next=0FFFFH。 图3 由增加文件能够看出,在查找空间时,只对目录区和页面分配区操作,因而,删去文件时,只需求开释目录和页面分配区即可,而不需求修正数据区。这大大进步了删去的功率。 (3)体系格局化 体系格局化的意图是把AT24C512依照前面所述的格局进行初始化,以正确反映现在的运用情况。格局化的首要作业包含: ①把目录区悉数写为0FFH,以清空目录区中一切数据; ②把页面分配区的一切记载项写为0EEEEH,标志它们悉数未运用。 注:文件体系程序源代码见网站:www.dpj.com.cn。 4 功能比较 在大多数体系中,AT24C512中的数据存储都是要用次序存储法:每次存储数据时都是依照先后次序顺次写入数据空间。本文所述办法与次序存储法比较,具有下列长处: ①存储时操作简略。在次序存储中,寻觅闲暇空间需求逐次读出现已存储的数据,直到找到闲暇空间停止,数据操作量大。本文所述办法只需求读取目录区和页面分配区即可,查找闲暇空间的功率高。 ②删去数据简略。在次序存储中,为了定位到需求删去的数据,有必要逐次读出存储的数据,直到找到需求删去物数据,再把该闲暇改写为未用情况。本文所述办法只需求修正目录区和页面分配区即可,不只定位数据快,并且修正的作业量很小。 ③完成了数据空间的收回。次序存储法中,在删去的某次数据后,该数据所占用的空间或许无法收回运用。由于收回的空间会构成碎片:该空间前后都存储有数据,但该空间的长度无法满意一个更大长度的数据。本文所述办法运用链表分配存储空间,答应一个文件的数据非接连在座,收回的空间能够自在运用。 ④经过读取目录区,用户能够大致知道该文件中存储的是什么数据,而次序存储法却无法供给这些信息。 5 定论 为了完成实时测控体系数据的高效办理,依照PC机文件体系的思维,对测控体系中的AT24C512规划了一个简略的文件体系,包含体系格局化、增加文件、删去文件等功用,在大数据量的测控体系中得到了成功运用。该文件体系稍加修正就可运用于不同容量的存储芯片,具有广泛的运用价值。






