在剖析TDM模型的优劣势之前,我想最好先罗列一下一些数据文件格局的技能要求。
NI软件平台上针关于测验丈量的数据,有许多不同的文件格局,其中有几种是支撑TDM模型的。并不是说这些文件都能满意以下技能要求,我仅仅先罗列出来:
1)写文件速度有必要要快。许多情况下需求一边收集数据一边就把数据写到文件中,收集卡的速度现已适当快了,这时分瓶颈常常是在写文件这个过程上。相反,读文件或许并没有如此高的要求。
2)向文件追加(append)数据的时分,速度要快,这个时分不能读取文件中的信息。这其实也是常用的一个use case,收集数据写入文件的动作或许常常要进行(比方在一个循环中),往往又是往相同的文件中写入信息。
3)写文件的速度不能与文件巨细成正比。咱们期望不论文件有多大,写文件的速度总是坚持相对稳定,不能文件越大就写得越慢。
4)支撑随机的读取。比方我想读文件中某个方位的某些内容,不能要求把这个方位之前的一切数据都先读出来(即读到内存中)。
5)支撑别离读写描述性信息和原始数据。这是上一条的延伸,读描述性信息(meta data)的时分不要求把原始数据(raw data)读进来,相同,读原始数据的时分也不要求把描述性信息读进来,不然,必然影响读文件的速度。
6)对读文件的速度也有必定的要求。这个要求首要来自于查找数据。许多众多的数据,怎样才能快速的找到用户需求的数据,这一直是一个难题。
7)文件不能太大。存储相同的数据量,文件天然越小越好。
技能要求暂时就写这么多,其实总结起来,无非两点:1)快;2)便利。咱们对照TDM的数据模型,关于“快速”,暂时看得不明显(今后能够谈谈为什么TDMS文件能够到达“快速的要求”),可是说它“便利”,仍是能够了解的。
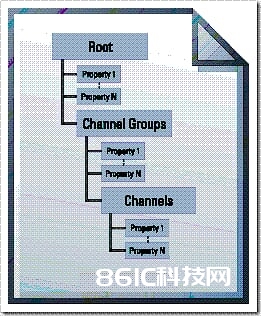
这个模型的规划完全是按照用户的使用实例。首要,它是分层次的。比方说咱们需求测验轿车发动机的各个目标。咱们用8个通道的收集卡收集发动机振荡的数据,8个通道别离收集8个部位的振荡,存到文件中,作为一个组(group),组的名字就叫做“发动机振荡”。咱们还需求收集发动机的进气管、排气管压力,又作为一个组。还要收集发动机的温度,或许也用8个通道的收集卡收集8个部位的温度,每个部位的温度数据作为一个通道(channel)存到文件中,8个通道作为一个组,叫做“发动机温度”等等。咱们或许会收集屡次,其他参数都不变,仅仅数据每次都附加在文件的后边。咱们有许多的测验工程师,每个工程师做的测验别离存成一个TDM模型的数据文件。能够发现,这样的三层结构仍是很明晰的。这就比方用LabVIEW些程序,VI大了,就不知道怎样管理了,那就多用几层SubVI嘛。
其次,它具有描述性信息。比方或许需求把测验的日期、测验者的名字、测验的环境装备等信息写下来。有些描述性信息是针对“文件”这个层次的,比方测验者的名字。有些信息或许针对“组”这个层次,比方收集的是“温度”,单位是“摄氏度”。有些信息则或许针对“通道”,比方收集的是发动机哪个部位的温度等等。描述性信息比较利于他人阅览文件,而且,在查找文件数据的时分,能够派上大用场,能够先使用这些描述性信息进行定位。当然,这些信息最好能和“原始数据”(raw data)放在一同,要是放在两个文件中,一是难以对应起来,而是不利于保护。这也比方是写LabVIEW程序,你写的程序,他人也要能看到,没太多的好办法,就多写点注释吧。
这样的TDM模型也有其缺陷。至少看起来有点杂乱,一起有原始数据和描述性数据,还要完成那么多的技能要求,着实有点困难啊。其次,这个模型写下来就固定了,总共就3个层次,说到底在某个文件中也就2个层次,不能扩展,不像XML那样便利。我有时分就想要把数据写到一个“通道”中,我还非得先造一个“组”出来(其实能够不写,默许会造一个出来,可是逻辑结构上不能短少)。还有其他约束条件,比方原始数据有必要写在“通道”这个层次,不能写在“组”这个层次等等。
整体来讲,TDM数据模型利大于弊,比较合适测验丈量范畴的数据的存储,是一套不错的解决方案。
声明:本文内容来自网络转载或用户投稿,文章版权归原作者和原出处所有。文中观点,不代表本站立场。若有侵权请联系本站删除(kf@86ic.com)https://www.86ic.net/ceping/213627.html