初度接触到ARM的时分,我直接被许多的处理器版别、系列搞晕了,查了许多材料才理清。现在在这里总结一下,希望能帮到他人。
1.整体状况
先从ARM的wiki上抄个表过来:
| Architecture | Family |
| ARMv1 | ARM1 |
| ARMv2 | ARM2,ARM3 |
| ARMv3 | ARM6,ARM7 |
| ARMv4 | StrongARM,ARM7TDMI,ARM9TDMI |
| ARMv5 | ARM7EJ,ARM9E,ARM10E,XScale |
| ARMv6 | ARM11, Cortex-M |
| ARMv7 | Cortex-A,Cortex-M,Cortex-R |
| ARMv8 | – |
左边的一列能够视作是ARM处理器的各个“代”,而右侧则是同一代的各个“宗族”(或者说“系列”)。现在根本已是ARMv7的年代,ARMv6及更早的Architecture只在一些低端的设备上能见到了。而ARMv8则是ARM渠道的未来时,被规划为64位的架构,明显不是首要面向移动设备的。不过到现在为止ARMv8也仅仅有一些材料,离真实问世还有一段时刻。
现在把要点放在ARMv7,更切当的,是ARMv7中的Cortex-A系列中心上来。Cortex-M系列处理面向嵌入式运用,而Cortex-R系列则面向实时运用,Cortex-A,则面向广阔的手机用户。
2.Cortex-A系列的许多中心们
| 中心 | Cortex-A5 | Cortex-A7 | Cortex-A8 | Cortex-A9 | Cortex-A15 |
| 发布年份 | 2009年 | 2011年 |
2006年 |
2007年 | 2011年 |
| 中心 | 1-4核 | 1-4核 |
单核 |
1-4核 | 最多4核每cluster,每物理核最多2个cluster |
| 流水线 |
8级(in-order) |
8-10级 |
13级(整点 in-order) |
8级(out-of-order) |
12级in-order加3-12级out-of-order |
| 硬件虚拟化 | 否 | 是 | 否 | 否 |
是 |
| L1 Cache | 4-64K/4-64K | 8-64K/8-64K | 16-32K/16-32K | 16-64K/16-64K | 32K/32K |
| 大物理地址扩展 | 否 | 是 | 否 | 否 | 是 |
| 浮点部件 | VFPv4 | VFPv4 | VFPv3 | VFPv3 | VFPv4 |
*发布年份是ARM发布中心的时刻(或许不太精确)。
*A15的流水线前12级是in-order的,后边则是out-of-order的多种流水线,级数从3到12不等。A7类似,NEON部件的流水线是10级,整点则是8级。
现在来剖析一下各个中心的参数。首先是Cortex-A后边的编号,大体上,这个编号代表该中心的功用,或者说在ARM产品线中的方位。比方A5面向低端运用,编号最小;A15是现在ARMv7功用中功用最高的中心;A7虽然发布晚于A8,并且规范挨近,但因为约束了双发带宽,其功用预期是低于A8的。总的来看,A5的定位最低端,替代ARMv7之前的产品;A15最高端,A7功用低于A8,但愈加节能,本钱也更低;A8/A9则或许被替代,不过现在仍然是干流;A15则是现在为止ARM处理器中规范最高的了。
再看一下较新的中心中几个重要的特性。A7和A15支撑硬件虚拟化,以A7的定位来说硬件虚拟化的支撑好像没有太多用武之地,不过关于A15来说则标明A15或许用于传说中的ARM服务器(不过算算时刻好像也没有太多A15发挥的地步,究竟64位的ARMv8更适合用于服务器)。大物理地址扩展(LPAE)和x86上的PAE类似,答应32位的ARM处理器最大寻址2^40bit的内存(1TB)。这又是一个标明A15可用于服务器的痕迹,究竟4G的寻址空间对现在的服务器来说彻底不够用啊。
3.浮点和高档SIMD部件
ARMv7开端运用VFPv3版别的浮点部件,而ARMv7中更新的中心则运用了VFPv4( 见前面表格)。VFPv2则用于ARMv7之前的中心,现在还有一部分低端手机运用这种处理器;而运用VFPv1浮点部件的中心现已根本筛选掉了。ARM的高档SIMD部件称为NEON,从ARMv7开端呈现
ARM浮点部件的一个问题是对许多中心来说是可选的,一些处理器并没有浮点部件。不仅如此,虽然ARMv7的处理器根本都完成了浮点部件,但浮点部件也有多个可选完成,再加上NEON部件也是可选的,最终导致市面上的ARM处理器对浮点/SIMD的支撑并不共同。下表列出了首要的VFPv3完成的版别(VPFv4的材料需求弥补):
| 版别 | 寄存器 | 其他特性 |
| VFPv3(-D32) | 32个64位寄存器,32个32位寄存器 | |
| VFPv3-FP16 | 同上 | 半精度扩展(FP16的意义) |
| VFPv4(-D32) | 同上 | VFPv4总是完成半精度扩展和Fused Multiply-Add 扩展 |
| VFPv3-D16 | 16个64位寄存器,32个32位寄存器 | |
| VFPv3-D16-FP16 | 同上 | 半精度扩展 |
| VFPv4-D16 | 同上 | 同VFPv4 |
上表中所说的32位寄存器和64位寄存器并不是独立的,前16个64位寄存器每个能够视为2个32位寄存器,一起,两个64位寄存器能够视为一个128位寄存器。下图来自ARM官方文档,展现了32位寄存器和64位寄存器的联系:
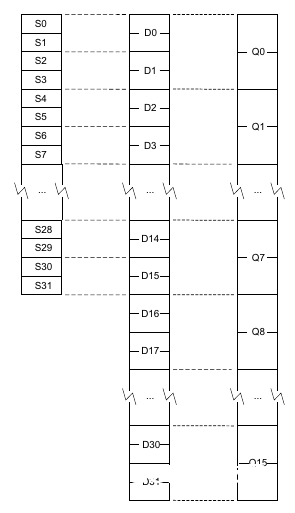
关于VFPv3-D16、VFPv3-D16-FP16和VFPv4-D16来说,上图中的D16~D31是不存在的。除了上表中的版别,VFPv3还有单精度版别,只完成了单精度浮点数的运算指令,gcc中称这种版别的VFPv为“vfpv3xd”,相应的,还有vfpv3xd-fp16。不过这种完成的ARM处理比较罕见。
NEON部件和浮点部件联系密切,在两者一起存在时,运用的是同一套寄存器。不过,NEON的寄存器数目是固定的,和VFPv3/VFPv-FP16/VFPv4相同。这意味着,NEON不能和VFPv3-D16/VFPv3-D16-FP16这种寄存器阉割版共存。当没有浮点部件时,NEON部件只能进行整点运算。下表是NEON和VFP部件或许的组合:
| NEON部件 | VFP部件 | 阐明 |
| 仅整型 | 未完成 | |
| 整型和单精度浮点 | 单精度浮点 | |
| 整型和单精度浮点 | 单精度和双精度浮点 | |
| 未完成 | 单精度浮点 | |
| 未完成 | 单精度和双精度浮点 |
从上面这个表能够看出,即便VFP部件完成了双精度运算的功用,NEON部件也只能进行单精度运算。不止如此,gcc的手册之处,NEON的浮点运算不彻底契合IEEE 754规范,在某些状况下会丢失精度,因而即便运用了主动向量化的选项,浮点运算的向量化默许也是封闭的。
依据半精度和Fused Multiply-Ad扩展的完成状况,NEON部件能够分为3种版别:
高档SIMDv1:两者均未完成
高档SIMDv1带半精度扩展:完成了半精度扩展
高档SIMDv2:一起完成了半精度和Fused Multiply-Ad扩展
而NEON半精度和Fused Multiply-Ad扩展的完成状况与VFP部件是相关的。
总结一下VFP和NEON的特色:
1.VFPv3/VFPv4分为依据寄存器状况分为D16和D32两个版别,D16的双精度(64位)寄存器只要16个。
2.D16版别的VFP不能和NEON部件共存。
3.NEON部件独自存在时只能进行整点运算
4.完成了半精度扩展的VFPv3称为FP16版别,假如连Fused Multiply-Ad扩展也完成了,便是VFPv4了。
除了上面所说的,ARMv7处理器还有许多特性。因为我了解的不多,就不多说了