摘要:介绍了一种新式解码器,能够在数据包中解码出希望KPI的值。在机站测验等过程中,需求检查一些KPI值,而一切KPI是服务器端以数据包的方法发送到客户端的。解码器首先把各个方针KPI按位与,得到总的方针值m,然后m与树状结构中的非叶子结点以及叶子结点按位与,假如成果值不等于非叶子结点,则越过其子结点,持续和其兄弟结点按位与,直到找到希望KPI。这种办法不必解码出数据包中的悉数数据,即可得到希望的KPI值,简洁而又高效,大大提高了工作功率。
关键词:解码器;数据包;树状结构;C++;JAVA
0 导言
计算机网络数据通常是以数据包进行传输的,数据包由报头、负载、报尾等部分组成。在机站测验等过程中需求常常得到很多KPI(Key parameterindicator)的值,而这些KPI是由服务器以数据包的方法发送到客户端的,那么如安在以二进制表明的数据包里边快速而精确地得到希望的KPI的值呢?在此规划了一个高效而有用的解码器,用以快速得到某一字段的KPI值。
1 解码器简介
解码器源代码是一些C++代码,用来解码出数据包对应的KPI的值。在基站、网络等测验过程中常常需求计算各种KPI的值,而相关KPI的值有时多达几十乃至几百个,假如想要在这巨大的数据里边,快速有效地得到一个或许几个KPI的值,一般的办法是把这段码流进行解码得到悉数对应的值之后再查找希望的值。这种办法不只费时吃力并且简单犯错,在此使用一种树状结构的数据结构规划出了解码特定值的解码器,用以获取希望KPI的值。这种解码器不只能够协助工作人员快速得到希望的KPI值,并且削减犯错的几率,提高了工作功率。
下面介绍一些名词的意义,音讯是指由根本数据类型表明各种KPI及其组成方法的调集。音讯界说文件是指用来界说比如XSD、C头文件、文本文件等音讯格局的文件格局。逻辑表是XML格局文件,用来界说一些无法用C头文件描绘的逻辑条件。XSD即XML Schema Deftnition,用以标准和验证XML格局的文档。
每条信息对应一个解码函数,用以解码数据包里边对应的二进制流数据,各种解码函数构成了解码器。它不是解码整条音讯,而是有挑选地解码部分比特流以得到希望的KPI的值,因而它是十分高效的。
端方法(Endian)是指在计算机体系结构中存储信息的不同次序,分为大端(Big-endian)和小端(Little-endian)。大端指数据的高位存储在内存的低地址中,而数据的低位存储在内存的高地址中,小端则相反。
因为需求解码不同的音讯,而不同的音讯具有不同的格局,因而和音讯对应的解码函数也是不同的,那么就需求依据不同的音讯格局生成相应的解码函数。在此每条音讯用相应C头文件表明,然后依据C头文件装备对应的逻辑表。以C头文件和逻辑表作为输入,编写Java代码使用Eclipse生成相应的解码函数(解码器)。
软件终究产品为解码器,其为具有解码功用的C++源代码,能够有挑选地解码出想要检查的KPI的值。解码器的输入为装备参数、C头文件、逻辑表。装备参数指出了音讯的格局、C头文件的途径、逻辑表的途径、生成的解码器的输出途径以及是大端或小端解码等。程序依据C头文件所界说的音讯生成XSD文件,其是与C头文件中的结构体逐个对应的,然后依据发生的XSD文件、逻辑表以及装备参数生成解码器。其数据流程图如图1所示。

2 编码办法
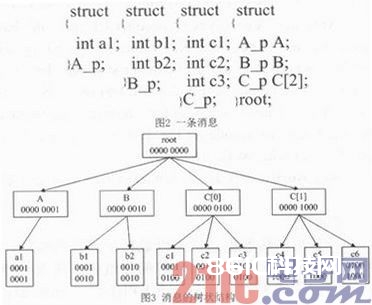
每条音讯都可由相应的结构体表明,这些结构体坐落C头文件中,能够写成树状结构的方法。假定某条音讯如图2所示,由以下结构体表明:其间A p、B p和C p处于同一层,root为根结构体,包括了A p、B p和C p结构体。根本数据类型包括整形、字符型、位域等,为叶子结点,非根本类型数据包括结构体数组、联合等,为非叶子结点。在此,这条音讯可由树状结构来表明,如图3所示,root根结点表明为0000 0000,A结点表明为0000 0001,a1表明为0001 0001;B结点表明为0000 0010,b1表明为0001 0010,b2表明为0010 0010;C[0]表明为00000 100,c1表明为0001 0100,c2表明为0010 0100,c3表明为0100 0100;C表明为0000 1000,c4表明为0001 1000,c5表明为0010 1000,c6表明为01001000。可见root、A、B、C[0]、C[1]为非叶子结点,对错根本数据类型,其他是叶子结点,是根本数据类型。咱们称root为A、B、C[0]和C[1]的父结点,A是a1的父结点,B是b1和b2的父结点,以此类推。注意到,每个父结点和其子结点位与()的成果值都为父结点,例如:root(0000 0000)A(0000 0001)=root(0000 0000),A(0000 0001)a1(0001 0001)=A(0000 0001),B(0000 0010)b2(0010 0010)=B(00 00 0010)。由此,若要取KPI b2和c4的值,那么传入的方针值为m=b2 |(位或)c4=0011 1010,让方针值顺次与某结点位与(&),假如成果值等于某结点,那么阐明某结点的子结点包括或许是方针值,例如m(0011 1010)&B(0000 0010)=B(0000 0010),又已知B对错叶子结点,故B的子结点中必定包括方针结点,然后m顺次与b1和b2按位与,mb1 b1,又知b1是叶子结点,故b1不是要解的方针值,则越过b1,持续解b1的兄弟b2,明显,mb2=b2,又知b2是叶子结点,故b2是要解的方针值,以此可得到c4也为方针值。又mA A,又知A对错叶子结点,故可把A结点以下的子结点越过不解,以此类推,C[1]及其子结点也能够越过不解,那么这就大大提高了解码的功率。
有时分存储信息不需求一个完好的字节,只需求占一个或几个二进制位,这种存储信息的方法称为位域。当音讯里边包括位域的时分,因为不同的机器可能是大端或许小端。那么就需求界说是依照大端解码仍是依照小端解码。
3 模块规划
体系分为初始化、XSD转化、XSD解析、XSD拜访等四个模块。
初始化模块首要进行参数装备,然后开端运转Eclipse生成解码器。需求装备的参数有:音讯称号、C头文件途径、逻辑表途径、解码器输出途径、端类型等。
XSD转化模块首要进行C头文件界说的结构体的解析,并生成XSD文件。
XSD解析模块将XSD文件解析成XSD素目标。这儿选用DOM方法进行解析XSD文件,DOM(文档目标模型)界说了层次化模型来表明XSD文档,对应XSD中的每一个元素界说一个相应的类与其逐个映射。解析时读入整个XSD文件,然后在内存构建一个树状结构,每遇到一个元素就实例化一个元素目标。XSD元素目标分为根元素、结构体元素和叶子元素。根元素为整个XSD文件,如图3中的root,结构体元素为XSD文件的非叶子结点,如图3中的A、C[0]等,叶子元素为XSD文件的叶子结点,其存储了详细的KPI的值,如图3中的a1等。
XSD拜访模块的功用是在XSD目标中查询逻辑表中的数据,并生成解码器。
逻辑表首要是用来表明在C头文件中不能表明的逻辑状况,在此有三类常见的逻辑。通常在一个union里边有多个元素,在解码原始数据流时要挑选正确的元素,那么,就必须有一个指引元素,其指明晰哪一个元素是被挑选的。假如这个指引元素是在union外,那么就称其为key out union,相反则称其为key in union。假如咱们要解码的KPI是一个变长数组,那么明显在C头文件中是没有办法描绘的,在此咱们界说一个变量专门用来界说变长数组的长度,称其为variable length array。在某种条件下在数据流中有的数据是没有意义的,那么就需求咱们界说一个变量来决议其是否有意义,咱们称这样的变量为optional。
4 结束语
针对数据包中的很多数据,解码器使用树状结构的编码规矩能够快速找到希望的KPI的值,这种对信息提取的高效性,能够大大提高工作功率,添加效益。此解码器不只能够独自用来对数据包里边的数据进行提取,也能够和其它软件一同构成一个小型测验体系等。