FPGA究竟不是ASIC,对时序收敛的要求愈加严厉,本文首要介绍自己在工程中学习到的各种时序束缚技巧。
首要强烈引荐阅览官方文档UG903和UG949,这是最重要的参阅资料,没有之一。它发起要在规划的前期阶段就要扫除问题,越到后期时序的改进就越困难。其间HLS层次对功用的影响是最大的。
本文将从代码风格,时序批改,工程设置等几个方面介绍自己的实践经历,期望让各位初学者快速进步,也期望FPGAer能给出名贵主张。
1. 代码风格
引荐运用Xilinx language templates的代码块,这儿的代码能够归纳出正确且结构简练的电路,包含移位寄存器,乘法,复数乘法,FIR滤波器等,但凡涉及到的模块尽量运用官方写法。
合理的规划代码结构。IO相关的代码、时钟办理单元尽量放在顶层,后者有助于以共享资源然后进步功用下降功耗。模块的输出最好是运用寄存器输出,有助于下降途径延时协助时序收敛。
复位也是非常重要的问题。和ASIC不同,Xilinx FPGA的寄存器是高电平复位,支撑异步复位和同步复位,可是DSP和BRAM内部的寄存器不支撑异步复位。因而,官方更引荐规划选用高电平同步复位,能够下降资源的运用和功耗,有助于时序收敛。因为FPGA的初始状况是确认的(能够在界说阐明中指定),为了更快地时序收敛,官方文档以为,能不必复位是最好的,特别数据途径和移位寄存器的规划中。不过运用同步复位仍需要注意操控集不能太多的问题。关于这方面的内容,UG949第三章Control Signals and Control Sets给了具体的阐明。
数学运算运用DSP单元速度会更快一些,依据DSP的结构重组数学运算,充沛利用FPGA的DSP、BRAM资源。并且能做到对代码映射的硬件资源心里有数。
假如并不需要优先级,尽量将If句子转化为case句子。
尽量不要运用Don't Touch这类句子。现在Vivado归纳东西现已很完善了,除非代码有问题或许手动仿制寄存器,不然一般不会发生电路被归纳掉的现象。运用这些句子会掩盖Vivado归纳设置,导致电路没有得到充沛的优化,给时序收敛形成困难。
2. 时序批改
严厉遵守Vivado开发流程,在第一次跑归纳时最好是在没有任何物理束缚的情况下,Vivado在越少物理束缚的情况下归纳出来的作用越好。检查每个阶段的时序陈述,将每一阶段的时序违例操控在300ps以内,尽早消除问题。曾经自己RTL Analysis阶段过了之后挑选运转Implementation越过Synthesis陈述,这是不可取的行为。有时候会发现Synthesis有时序问题而在ImplementaTIon阶段反而没问题,这是因为Vivado在ImplementaTIon阶段对时序不满意的当地倾斜了更多的资源确保时序收敛。可是疏忽Synthesis的时序问题会在后期顶层模块集成占用大资源时迸发出来。
下面介绍首要面临的两个时序问题的处理技巧。
1)setup TIme 树立时刻问题
树立时刻是工程规划中最常遇到的问题了。一般说来,导致树立时刻违例首要有两个原因:逻辑级数太大或许扇出太大。
翻开Report TIming Summary界面检查途径推迟信息,如下图所示。
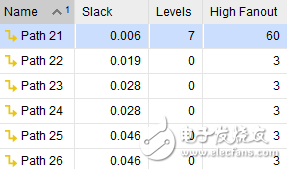
Levels指的是逻辑级数logic level,一个logic level的推迟对应的是一个LUT和一个Net的推迟,关于不同的器材,不同频率的规划能包容的logic level是不同的。假定7系列的-2速度等级250MHz的规划,电路规划的大部分levels最好不要超越8,不然会形成时序收敛困难。

Logic level太大的处理办法便是重守时(Retiming)了,典型的重守时办法便是流水线,将过于冗长的组合逻辑添加寄存器进行打拍。
High Fanout指的是扇出,相同和器材、规划频率等有关,如下图所示:

下降扇出最好不要在归纳设置中指定,过低的扇出限制会形成规划阻塞反而不利于时序收敛,最好的办法是依据规划中时序最差途径的扇出进行针对性的优化。假如是寄存器的输出扇出很大,能够运用max_fanout特点符号寄存器声明,也能够手动仿制寄存器,具体可参阅:https://blog.csdn.net/shshine/article/details/52451997
假如不是要害时序途径,并且高扇出网络直接连接到触发器,对扇出超越25K的net刺进BUFG:
set_property CLOCK_BUFFER_TYPE BUFG [get_nets netName]
当然,也能够在后期Implementation的物理优化设置中优化扇出。
2)hold time 坚持时刻问题
在实践中,我发现坚持时刻问题的问题往往是异步处理的问题。
关于一个信号的跨时钟域问题,一般运用双寄存器法(关于慢采快的结绳法这儿不评论)。为了下降MTBF(Mean Time Between Failures,均匀无障碍时刻),这两个寄存器最好坐落同一个slice中。能够运用tcl言语指定,如:
set_property ASYNC_REG TRUE [get_cells [list sync0_reg sync1_reg]]
也能够直接在代码中指定:
(* ASYNC_REG = “TRUE” *) (* keep = “true” *)reg sync0_reg, sysnc1_reg;
也能够参阅代码模板运用XPM模板进行处理。
多个信号一般是运用FIFO或许握手的办法,这儿不再赘述原理。同步CDC处理比较复杂,自己计划之后别的写一篇文章具体叙述。
3. 工程设置
Vivado归纳完成实质是时序驱动的,和ISE不同,因而再也没有ISE那种用随机种子归纳完成满意时序收敛的东西。不过Vivado在布局布线方面供给了几种不同的战略(directive),经过不同战略的组合能够发生上千种不同的布局布线成果,还能够运用tcl钩子脚本自界说布局布线进程,足以满意需求。并且,Vivado可支撑一起运转多个Implementation,这为这种规划时刻交换功用的办法供给了东西上的便当。
Implementation里Post-place Phys Opt Design和Post-route Phys Opt Design是没有使能的。工程后期使能这两个装备也能在必定程度上改进时序收敛。
FPGA工程师的作业不只是将电路功用完成,因为器材和东西不是抱负的,所以还需要研讨器材特性和东西的限制,特别是在现在算法结构越来越老练的布景下,不断被东西摧残,或许这也是FPGA工程师的悲痛吧。