


依据Mali-T604嵌入式GPU的二维浮点矩阵运算并行优化
ARM Cortex-A15系列处理器是当时最新的嵌入式ARM SoC,该系列处理器初次集成了Mali-T600系列的移动端GPU,该系列GPU支撑OpenGL以及OpenCL等核算结构,能够有用加快通用核算,而现在对其运用办法和实践优化作用的研讨很少。本文依据以三星的Exynos5250处理器为中心的Arndale Board嵌入式开发渠道,对集成于处理器上的Mali-T604嵌入式GPU的GPGPU(General-Purpose computation on GPU)技能进行研讨并对不同运算规划的浮点矩阵乘法进行并行加快优化,供给实践测验成果。
GPGPU技能早年首要在超级核算机渠道进行高功能核算,而近年该技能逐步被引进嵌入式范畴。但在曩昔的移动GPU渠道上没有专门针对通用核算的软件结构和编程接口,软件规划者难以关于数据的同步和核算的并行进行操控,所以移动GPU在通用核算范畴一向难以运用。本文依据Exynos5250 SoC渠道胪陈Mali GPU的硬件特性和将其运用于通用核算的编程的办法,最终将二维浮点矩阵乘法并行化作为优化实例,验证Mali GPU的并行才干,为计划运用嵌入式GPU的GPGPU技能进行优化作业的研讨人员和运用开发者供给技能参阅和学习。
1.Mali T604 GPU的硬件结构和编程特性
Mali是由ARM研制规划的移动显现芯片组(GPUs)系列,不只能够在移动端供给强壮的图画烘托才干,一起在近期对通用核算进行了杰出的软硬件支支撑。
1.1 Mali T604 GPU的组成结构
Mali-T604是Mali系列中首款运用一致烘托架构Midgard的移动GPU,Mali-T604 GPU包括4个着色器中心,选用AMBA 4 ACE-LITE总线接口,该总线以Cache Coherent Interconnect技能为特征,在多个处理器之间供给彻底Cache一致性,经过ARM的一致性和互连技能,核算使命在异构体系中进行同享处理时,能够轻松跨过CPU、GPU和其他可用核算资源,更高效地拜访数据。图1展现了Mali-T604 GPU的根本结构。如图2所示,Cortex-A15 CPU中心以及Mali GPU中心物理上同享了片外的RAM存储器并坚持了L2Cache的一致性。
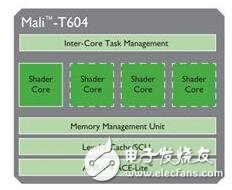
图1 Mali-T604根本硬件框图
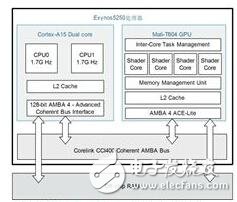
图2 Exynos5250处理器框图
Mali-T604 GPU在硬件层面优化了对使命办理和事情依靠的处理,并将这部分功用彻底集成在其硬件的使命办理单元之中,可将核算使命从CPU卸载到GPU,并在活动的着色器中心之间完结无缝负载平衡。
1.2 Mali GPU的并行化线程结构特征
Mali GPU进行通用核算的技能中心是以多核多线程的思维将密布的核算使命进行拆解,将很多的核算线程分配于很多核算中心中,GPU能够一起处理成百上千的线程,很多晶体管用于ALU.GPU合适做高密度数据的并行运算,只要在运算的并行粒度满足大的时分才干发挥出强壮的并行运算才干。图3展现了CPU和 Mali GPU之间作业分配的进程。
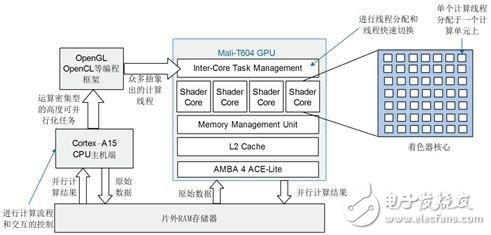
图3 Cortex-A15 CPU和Mali GPU之间的作业分配
Mali GPU中每个核算线程会占用着色器中心的一部分资源(存储器和ALU等),每个线程占用资源的多少影响了一起并行处理的活动线程的数量。对Mali GPU,每一个线程都有自己的程序计数器,这意味着Mali GPU和桌面GPU渠道不同,程序分支的发散不是一个影响功率的重要的问题。每个Mali-T604 GPU的着色器中心最多能够一起包容256个线程,Mali GPU在进行通用核算时需求很多的线程进行切换才干确保得到核算功率上的收益,关于Mali-T604而言,这个最少的总作业项数量是4096.假如分配于单个着色器中心上的线程数目缺乏128,很可能带来并行功率的下降,这时需求拆分作业为不同的进程,简化每个进程的线程复杂度,让单个着色器中心并行包容的线程数量满足多以确保并行度。
2.Mali GPU的并行化核算模型构建
Mali-T600系列的GPU对OpenCL 1.1 Full Profile标准进行了杰出的支撑,OpenCL是真实意义上的跨渠道异构并行结构,能够真实挖掘出Mali GPU的并行核算特性。
2.1 Mali GPU在OpenCL结构下的并行使命笼统及线程规划
OpenCL是一个由编程言语标准,运用程序接口、库函数和运行时体系组成的跨渠道异构并行核算结构,Mali-T604 GPU在OpenCL下的笼统层次如下面的图4所示:
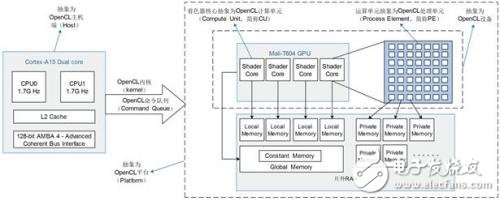
图4 OpenCL针对Mali-T604的笼统层次
OpenCL的并行依据SMT(一起多线程)的思维,由用户指定自定义数目的线程,并依据线程的标识符规划核算线程与数据相关的映射规律,SMT架构首要用于荫蔽访存的延时。OpenCL结构下,CPU主机端程序由OpenCL的API编写,完结核算渠道的初始化,存储器的分配和交互的操控,并决议分配的核算线程的维度和每一维的数量。设备端的内核程序由OpenCL C言语编写,Mali GPU会依据内核目标创立主机端恳求数量的线程实例,每个线程的运算作业都由图4中一个对应的PE进行处理,线程的作业逻辑决议了线程标识号和数据的相关联系。多个线程被安排为作业组的办法,每一个作业组固定分配到一个CU上进行处理,同一个作业组中的线程会在对应的CU上由Mali GPU的使命办理单元进行快速的切换和调度,确保一个CU上的PE最大极限坚持繁忙。
2.2 Mali GPU多核环境下的存储器空间映像办法
如图4所示,Mali GPU和Cortex A15 CPU所共用的RAM在逻辑上被OpenCL结构切开成了四种不同的类型,Mali-T600系列的GPU运用一致存储器模型,四种类型的存储器都映射到片外RAM上,Cortex-A15 CPU和Mali-T604 GPU同享物理RAM,相对桌面GPU渠道而言,在Mali渠道大将数据从全局存储器复制到部分或许私有存储器并不能使访存功能得到提高,但相对地也不必像桌面GPU相同进行从主存到显存的数据复制。Mali GPU有三种拜访RAM的办法,由传入clCreateBuffer函数中的不同参数决议,其示意图如下:
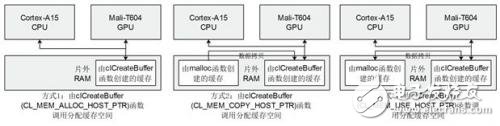
图5 OpenCL结构下Mali GPU对存储器的不同拜访办法
Cortex-A15 CPU和Mali-T604 GPU运用不同的虚拟地址空间,在主机端由malloc函数分配的缓存,Mali GPU无法拜访。Mali GPU能够拜访clCreateBuffer函数分配出的缓存,CPU凭借OpenCL中的map映射操作也可完结对这类缓存的读写,图5中的办法2需求主机端的缓存进行数据复制来初始化,办法3和办法2相似,但只在OpenCL的内核函数初次运用该缓存时才进行数据复制,在CPU端进行map操作时 GPU还会将数据复制回主机端的缓存,关于Mali GPU而言,剩余的数据复制操作会下降访存功率。图5中的办法1是ARM官方主张的访存办法,CPU和GPU同享一块物理缓存,高速完结数据交互。
2.3 Mali GPU的向量处理特性
Mali-T604 GPU内部有128位宽度的向量寄存器,运用OpenCL C中的内建向量类型能够让数据主动以SIMD的办法在Mali GPU的ALU中进行并行核算,Mali GPU中将数据以16个字节对齐能够使得数据的长度和高速缓存适配,加快数据存取速度,Mali-T600系列GPU中加载一个128位的向量和加载一个单字节数据花费的时刻是相同的。将数据以128位进行对齐,能够最大极限发挥Mali-T604 GPU的访存和运算功率。
3.依据Mali-T604 GPU的快速浮点矩阵乘法并行化完结
矩阵乘法运算在途径计划求解、线性方程组求解、图画处理等范畴一向有着广泛运用,一般的迭代式串行算法的时刻复杂度为O(n3),关于大型的矩阵乘法,特别是浮点类型的矩阵乘法,核算量十分惊人,传统的算法依据CPU进行规划,CPU并不能供给大型的并行度和强壮的浮点核算才干,关于大型浮点类型矩阵乘法的处理无能为力。
AB两个矩阵的乘法的成果矩阵中的每个数据均依靠于A中的一行和B中的一列的点积成果,每个核算成果没有依靠和相关,显然是高度可数据并行的核算问题,很合适运用GPU做并行处理,运用GPU上的多个线程能够并行进行矩阵A和B中不同行和列的点积。
实践进行试验时,以N*N的两个浮点矩阵A和B进行乘法,得出N*N的浮点成果矩阵matrixResult,运用Mali GPU进行并行化的时分,一共分配N*N个线程,以二维办法进行排布,标识号为(i,j)的线程提取出矩阵matrixA的第i行和矩阵matrixB的第j列,运用OpenCL中长度为128位的float4向量类型快速完结两个一维向量的点积,再将该点积成果存储到matrixResult[i] [j]方位。主机端分配线程的代码段如下:

笔者将clEnqueueNDRangeKernel函数中作业组巨细参数设置为NULL,由Mali GPU硬件主动确认最佳的作业组巨细。由于内核中每次会接连读取4个浮点数值凑成float4类型的数据,所以关于矩阵的宽度不是4的倍数的状况需求进行特别处理,可在主机端首先将输入矩阵A修改为N行N/4+4列,将矩阵B修改为N/4+4行N列,多出的矩阵部分均以0补齐,这样既不影响核算成果,也不会影响线程的分配计划,完结并行计划的内核函数如下所示:

本文选用Arndale Board开发板作为测验渠道,软件渠道选用Linaro组织为Arndale Board定制的依据Ubuntu的嵌入式Linux操作体系,其内核版别为3.10.37,试验时运用arm-linux-gnueabihf东西链对程序进行编译。不同规划的二维浮点矩阵乘法运算在ARM Cortex-A15 CPU上的串行计划和Mali-T604 GPU上的并行计划的测验成果如面的表1所示,为不失一般性,测验时输入矩阵内容为随机值,每种不同矩阵巨细的测验项进行10次测验,将测验值的平均值作为测验成果。
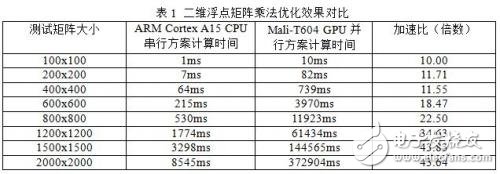
上表仅列出了输入量较大时的测验成果,笔者实践测验时,发现输入数据量较小的时分,并行计划没有串行计划的功率高,由于核算进程大部分都耗费在数据的传输上,由于核算量小,GPU端的核算瞬间完结,没有办法将Mali GPU访存的推迟掩盖,所以此刻访存速度较快的CPU端的串行计划反而功率更高。
当核算量逐步添加的时分,Mali GPU的并行才干逐步体现出其优势,加快比有明显提高,当核算量大到必定程度的时分,加快比趋于稳定,由于这时Mali GPU上有很多的线程切换,不只荫蔽了访存的推迟,也使得Mali GPU上的核算单元满载,其核算功率已达到硬件能够接受的极限,此刻Mali GPU能够提挨近40倍的供惊人的加快比。
实践测验时,笔者运用top指令调查矩阵进程的CPU占用量,串行计划的CPU占用量在98%左右,而依据Mali GPU的并行计划对CPU几乎没有占用量,阐明并行计划不只能够提高核算功率,还下降了CPU的担负,大大提高了体系实时性。试验的实践测验成果和GPU 异构运算特色符合。
4.结语
本文针对Mali-T604 GPU论说了依据OpenCL的Linux渠道上进行通用核算并行优化的办法,论说了Mali-T604 GPU的硬件特色,并依据OpenCL规划了二维矩阵乘法的并行计划,在Mali-T604上获得了惊人的加快比,成果表明Mali GPU关于巨大输入量的核算密布型高度可数据并行化通用核算问题有明显的加快才干,且并行优化成果正确牢靠。






