


Lte所挑选的上行传输计划是一个新变量:SC-FDMA(单载波-频分多址)比较于传统OFDMA其长处是既有单载波的低峰均功率比(PAPR),又有多载波的可靠性。在上行链路这点特别重要,较低的PAPR可在传输成效方面极大进步移动终端的功用,因而可延长电池运用寿命。代表LTE物理上行同享信道(PUSCH)的基带信号发生进程如图1所示[1]。
图1中的转化预编码是由一种对称方式DFT完结,其品种及改换长度L=2k1×3k2×5k3(L≤1 200)见表1。

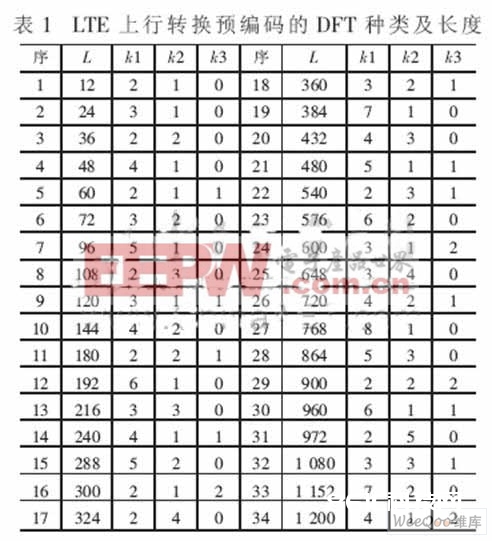
转化预编码是依据不同的输入长度L动态地履行表1中的一种DFT。其主要特色是包括的DFT品种多、规划巨大,这给硬件规划带来应战。曾经的文献大都以基2或单个混合基FFT[6]为要点进行论述,而以多种混合基FFT为中心的文章还很难发现。本文提出一种根据FPGA的转化预编码解决计划。
1 算法挑选
Cooley-Tukey算法和Good-Thomas算法是当时盛行的FFT算法,文献[2]中已对其原理进行过深化评论,这儿不再赘述。
(1)Cooley-Tukey算法具有杰出的模块性,而且能够完结原位核算,对输入数据以及旋转因子的抽取具有规律性。文献[3]提出的一种基3 FFT算法是Cooley-Tukey算法运用在基3 FFT中的另一种表述。这一算法差异于其他FFT算法的一个重要现实便是因子能够恣意选取,通用性强,且一切的运算单元均相同,易于完结。
(2)Good-Thomas算法只合适因子互质的状况,由于避免了中间级乘旋转因子的运算,因而比Cooley-Tukey算法的运算次数少得多。FFT点数越大,越能表现其在节约资源方面的长处。
文献[4]提出一种根据Cooley-Tukey算法的传输预编码解决计划。此计划的长处是操作简略、模块规矩、利于编程完结;缺陷是需求做的级间旋转因子乘法较多(最多达几百),乘法器和存储器等硬件资源开支较大,一起将大大添加系数初始化的作业量。对几种不同长度FFT运算量进行比较见表2。

表2中的混合算法指Good-Thomas算法与Cooley-Tukey算法相结合。能够看出,Good-Thomas算法与Cooley-Tukey算法相结合与文献[4]比较,削减了级间旋转因子乘法数,能够有用下降运算量,这些运算量的下降对整个体系的完结起着至关重要的效果,而其支付的价值仅仅复杂度的稍微提高。
综上所述,在完结混合FFT时,挑选Good-Thomas算法与Cooley-Tukey算法相结合,且优先挑选Good-Thomas算法,其次为Cooley-Tukey算法,体系规划将从Good-Thomas算法动身。
2 全体结构规划
从表1中看出,LTE上行转化预编码要进行的FFT改换品种多,但每一种改换的架构是类似的,都是由基2及非基2点FFT的公共模块组成。基2有点数为4,8,16,32,64,128,256的模块,非基2的有点数为3,9,15,27,45,75,81,135,225和243的模块,只需抽出这些公共模块并精心规划,再合理地调用,就会顺利完结这个看似繁琐的作业。
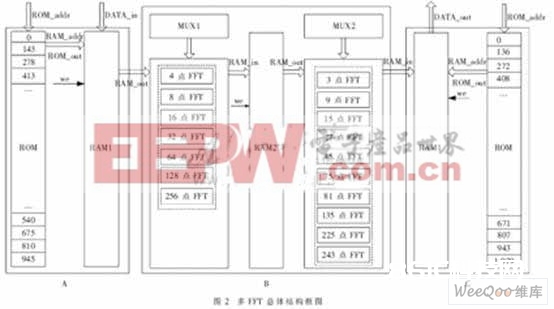
图2所示全体结构框图中,模块A和C分别为数据输入和输出模块;模块B为数据处理模块,其主要思维是动态装备和公共模块的复用,内部FFT模块事前独自生成,MUX1,MUX2是挑选器,在不同输入点数的状况下动态装备不同的内部FFT模块来组合成外层FFT,这样内部FFT模块就能够到达复用的意图,能够大大削减全体资源耗用,而处理速度也与独自履行各FFT适当。
3 硬件完结
在实践运用中,一般由FPGA完结需求快速和较为固定的运算,由DSP完结灵敏多变和运算量较大的使命[7]。Xilinx Virtex-5 SXT渠道针对具有低功耗串行连接功用的DSP和存储器密集型运用进行了优化,具有硬件结构可重构的特色,合适算法结构固定、运算量大的前端数字信号处理,能够很多卸载这些功用,开释DSP带宽以处理其他功用,一切这一切都使得FPGA在数字信号处理范畴显示出自己特有的优势。
3.1 地址映射
以1 080点FFT在图2所示体系中的完结进程剖析体系作业原理。由于1 080=8×135,且8和135互质,故外层选用Good-Thomas算法。
输入地址映射:

FPGA内嵌Block RAM的运用能够大大节约FPGA的可装备逻辑功用块(CLB)资源。Good-Thomas算法需求对输入输出数据进行排序,输入输出端处理办法相同,这儿只介绍输入端处理。在输入端,鉴于Block RAM的特征,设置一个ROM和RAM,如图2模块A所示。关于不同长度的FFT,ROM不同,但RAM能够共用。在ROM里预先寄存输入数据在RAM1中的方位序号,此方位序号由(1)式得到,在时钟沿到来时,先次序读出存储在ROM中的方位序号,将此数作为RAM1的地址输入,就能将输入数据寄存到RAM1中的不同方位。这样在输入数据的一起完结了数据的排序,一箭双雕。1 080点FFT的输入和输出端地址索引如图2所示,其逻辑时序图见图3。图3中,RAM_in由测试数据xn_i和xn_r进行位拼接后输入。

3.2 内部FFT处理单元
当进行图2模块B中的操作时,内部FFT模块先独自生成。Xilinx供给的FFT IP核适用于基2点的FFT改换,其所选用的算法为Cooley-Tukey算法,改换长度为N=pow2(m),m=3~16,数据采样精度和旋转因子精度都为8~24,故模块B的8、16、32、64、128及256点FFT都可用IP核生成。挑选“Pipelined,streaming I/O”生成基2点FFT模块,能够削减全体处理时刻。15、45、75、135、225点FFT模块的外层算法是Good-Thomas算法,其他选用Cooley-Tukey算法完结。






