


背景
随着生成式 AI 的兴起,和大语言模型对话聊天的应用变得非常热门,但这类应用往往只能简单地和你“聊聊家常”,并不能针对某些特定的行业,给出非常专业和精准的答案。这也是由于大语言模型(以下简称 LLM)在时效性和专业性上的局限所导致,现在市面上大部分开源的 LLM 几乎都只是使用某一个时间点前的公开数据进行训练,因此它无法学习到这个时间点之后的知识,并且也无法保证在专业领域上知识的准确性。那有没有办法让你的模型学习到新的知识呢?
当然有,这里一般有 2 种方案:
Fine-tuning 微调
微调通过对特定领域数据库进行广泛的训练来调整整个模型。这样可以内化专业技能和知识。然后,微调也需要大量的数据、大量的计算资源和定期的重新训练以保持时效性。
RAG 检索增强生成
RAG的全称是 Retrieval-Augmented Generation,它的原理是通过检索外部知识来给出上下文响应,在无需对模型进行重新训练的情况,保持模型对于特定领域的专业性,同时通过更新数据查询库,可以实现快速地知识更新。但 RAG 在构建以及检索知识库时,会占用更多额外的内存资源,其回答响应延时也取决于知识库的大小。
从以上比较可以看出,在没有足够 GPU 计算资源对模型进行重新训练的情况下,RAG 方式对普通用户来说更为友好。因此本文也将探讨如何利用 OpenVINO 以及 LangChain 工具来构建属于你的 RAG 问答系统。
RAG 流程
虽然 RAG 可以帮助 LLM “学习”到新的知识,并给出更可靠的答案,但它的实现流程并不复杂,主要可以分为以下两个部分:
01构建知识库检索

图:构建知识库流程
Load 载入:
读取并解析用户提供的非结构化信息,这里的非结构化信息可以是例如 PDF 或者 Markdown 这样的文档形式。
Split 分割:
将文档中段落按标点符号或是特殊格式进行拆分,输出若干词组或句子,如果拆分后的单句太长,将不便于后期 LLM 理解以及抽取答案,如果太短又无法保证语义的连贯性,因此我们需要限制拆分长度(chunk size),此外,为了保证 chunk 之间文本语义的连贯性,相邻 chunk 会有一定的重叠,在 LangChain 中我可以通过定义 Chunk overlap 来控制这个重叠区域的大小。

图:Chunk size 和 Chunk overlap 示例
Embedding 向量化:
使用深度学习模型将拆分后的句子向量化,把一段文本根据语义在一个多维空间的坐标系里面表示出来,以便知识库存储以及检索,语义将近的两句话,他们所对应的向量相似度会相对较大,反之则较小,以此方式我们可以在检索时,判断知识库里句子是否可能为问题的答案。
Store 存储:
构建知识库,将文本以向量的形式存储,用于后期检索。
02检索和答案生成

图:答案生成流程
Retrieve 检索:
当用户问题输入后,首先会利用 embedding 模型将其向量化,然后在知识库中检索与之相似度较高的若干段落,并对这些段落的相关性进行排序。
Generate 生成:
将这个可能包含答案,且相关性最高的 Top K 个检索结果,包装为 Prompt 输入,喂入 LLM 中,据此来生成问题所对应的的答案。
关键步骤
在利用 OpenVINO构建 RAG 系统过程中有以下一些关键步骤:
01封装 Embedding 模型类
由于在 LangChain 的 chain pipeline 会调用 embedding 模型类中的embed_documents和 embed_query 来分别对知识库文档和问题进行向量化,而他们最终都会调用 encode 函数来实现每个 chunk 具体的向量化实现,因此在自定义的 embedding 模型类中也需要实现这样几个关键方法,并通过 OpenVINO进行推理任务的加速。
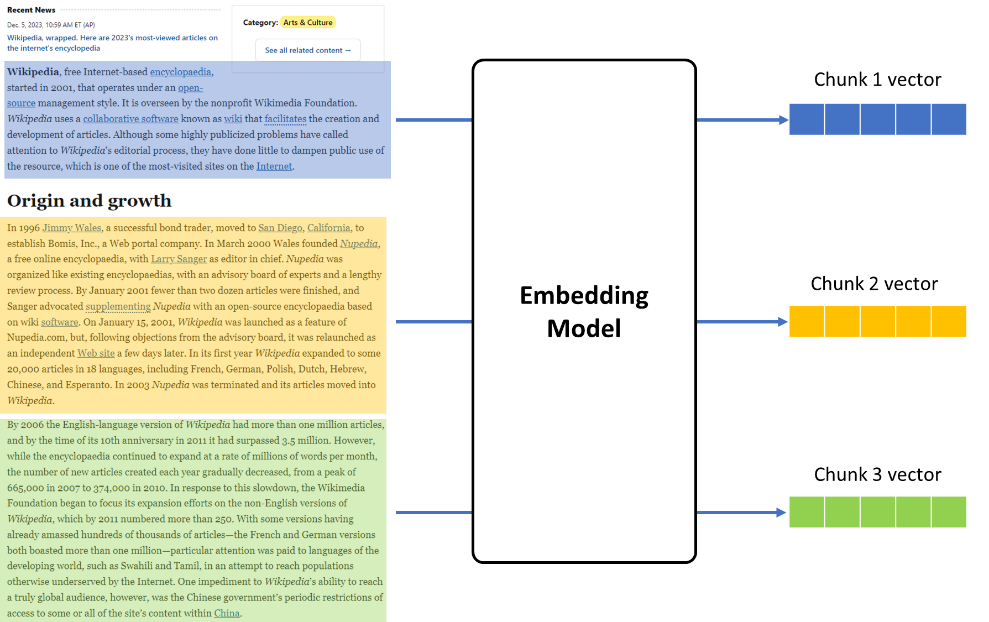
图:embedding 模型推理示意
由于在 RAG 系统中的各个 chunk 之间的向量化任务往往没有依赖关系,因此我们可以通过 OpenVINO 的 AsyncInferQueue 接口,将这部分任务并行化,以提升整个 embedding 任务的吞吐量。
左滑查看更多
此外,从 HuggingFace Transfomers 库中(https://hf-mirror.com/sentence-transformers/all-mpnet-base-v2#usage-huggingface-transformers)导出的 embedding 模型是不包含 mean_pooling 和归一化操作的,因此我们需要在获取模型推理结果后,再实现这部分后处理任务。并将其作为 callback function 与 AsyncInferQueue 进行绑定。
左滑查看更多
02封装 LLM 模型类
由于 LangChain 已经可以支持 HuggingFace 的 pipeline 作为其 LLM 对象,因此这里我们只要将 OpenVINO 的 LLM 推理任务封装成一个 HF 的 text generation pipeline 即可(详细方法可以参考我的上一篇文章)。此外为了流式输出答案(逐字打印),需要通过 TextIteratorStreamer 对象定义一个流式生成器。
左滑查看更多
03设计 RAG prompt template
当完成检索后,RAG 会将相似度最高的检索结果包装为 Prompt,让 LLM 进行筛选与重构,因此我们需要为每个 LLM 设计一个 RAG prompt template,用于在 Prompt 中区分这些检索结果,而这部分的提示信息我们又可以称之为 context 上下文,以供 LLM 在生成答案时进行参考。以 ChatGLM3 为例,它的 RAG prompt template 可以是这样的:
左滑查看更多
其中:
● {DEFAULT_RAG_PROMPT_CHINESE}为我们事先根据任务要求定义的系统提示词。
●{question}为用户问题。
●{context} 为 Retriever 检索到的,可能包含问题答案的段落。
例如,假设我们的问题是“飞桨的四大优势是什么?”,对应从飞桨文档中获取的 Prompt 输入就是:
左滑查看更多
04创建 RetrievalQA 检索
在文本分割这个任务中,LangChain 支持了多种分割方式,例如按字符数的 CharacterTextSplitter,针对 Markdown 文档的 MarkdownTextSplitter,以及利用递归方法的 RecursiveCharacterTextSplitter,当然你也可以通过继成 TextSplitter 父类来实现自定义的 split_text 方法,例如在中文文档中,我们可以采用按每句话中的标点符号进行分割。
左滑查看更多
接下来我们需要载入预先设定的好的 prompt template,创建 rag_chain。

图:Chroma 引擎检索流程
这里我们使用 Chroma 作为检索引擎,在 LangChain 中,Chroma 默认使用 cosine distance 作为向量相似度的评估方法,同时可以通过调整 db.as_retriever(search_type= “similarity_score_threshold”),或是 db.as_retriever(search_type= “mmr”)来更改默认搜索策略,前者为带阈值的相似度搜索,后者为 max_marginal_relevance 算法。当然 Chroma 也可以被替换为 FAISS 检索引擎,使用方式也是相似的。
此外通过定义 as_retriever函数中的 {“k”: vector_search_top_k},我们还可以改变检索结果的返回数量,有助于帮助 LLM 获取更多有效信息,但也为增加 Prompt 的长度,提高推理延时,因此不建议将该数值设定太高。创建 rag_chain 的完整代码如下:
左滑查看更多
05答案生成
创建以后的 rag_chain 对象可以通过 rag_chain.run(question) 来响应用户的问题。将它和线程函数绑定后,就可以从 LLM 对象的 streamer 中获取流式的文本输出。
左滑查看更多
最终效果
最终效果如下图所示,当用户上传了自己的文档文件后,点击 Build Retriever 便可以创建知识检索库,同时也可以根据自己文档的特性,通过调整检索库的配置参数来实现更高效的搜索。当完成检索库创建后就可以在对话框中与 LLM 进行问答交互了。
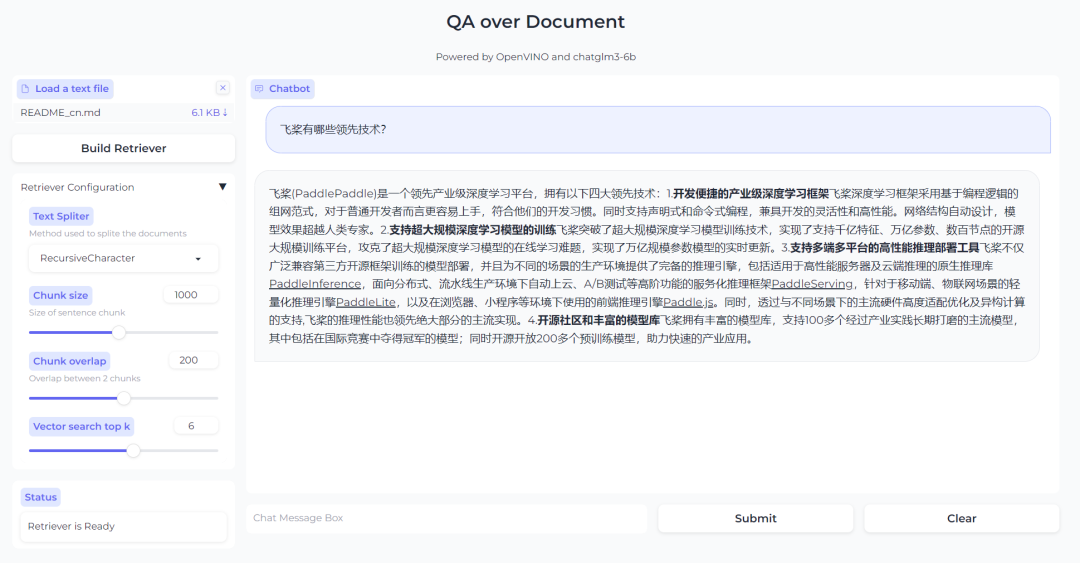
图:基于 RAG 的问答系统效果
总结
在医疗、工业等领域,行业知识库的构建已经成为了一个普遍需求,通过 LLM 与 OpenVINO 的加持,我们可以让用户对于知识库的查询变得更加精准与高效,带来更加友好的交互体验。






