ARM的NEON协处理器技能是一个64/128-bit的混合SIMD架构,用于加快包括视频编码解码、音频解码编码、3D图画、语音和图画等多媒体和信号处理运用。本文首要介绍怎么运用NEON的汇编程序来写SIMD的代码,包括怎么开端NEON的开发,怎么高效的运用NEON。首要会重视内存操作,即怎么改动指令来灵敏有用的加载和存储数据。接下来是由于SIMD指令的运用而导致剩余的若干个单元的处理,然后是用一个矩阵乘法的比方来阐明用NEON来进行SIMD优化,最终重视怎么用NEON来优化各式各样的移位操作,左移或许右移以及双向移位等。本节胪陈NEON供给的各式各样的移位操作,左右移位,移位刺进以及移位限定符如饱满舍入等以及这些移位操作怎么能有用的处理图画中的色深。
移位向量
NEON中的移位指令和ARM指令中的标量移位,把向量中的各个元素左移或许右移若干比特。那些移到接近元素的比特会被丢掉掉,不会影响到附近元素的移位成果。移位操作的移位数能够直接编码到指令里,或许用 一个指定的移位比特向量,假如运用移位向量,每一个元素的移位比特值将取决于对应的移位向量里存储的值,移位向量里保存的移位值是有符号的,所以或许进行左移,右移或许不移位的操作。
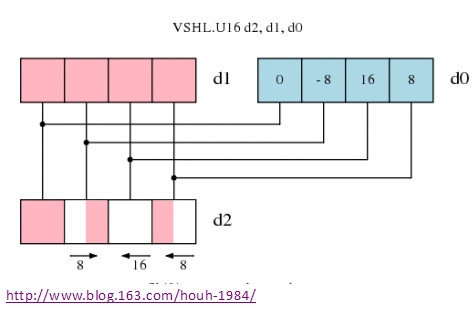
图1. 带移位向量的左移操作,能够左移、右移或许不移位
有符号数据的右移操作的类型能够依据指令来拟定,如是否进行符号扩展(算术右移仍是逻辑右移),这对应于ARM指令里的移位操作。关于无符号的右移而言,就不必进行符号扩展了。
移位并右侧刺进
NEON还支撑带刺进的移位,即进行两个向量的比特位域的组合。比方VLSI指令左移并刺进,会把向量进行左移,然后用 方针向量的右侧数据来填充。如下图所示:
arm.com/index.php?app=core&module=attach§ion=attach&attach_rel_module=blogentry&attach_id=511″ rel=”nofollow” >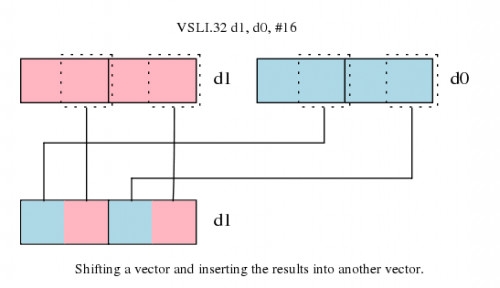
图2. 向量移位并填充成果向量
移位并累加
NEON支撑把向量的各个元素右移然后累加成果到别的一个向量。这关于那些中心成果需求更高精度的状况十分适用,然后才把 成果保存到一个低精度的累加器里。
指令修正符
每个移位指令都能包括一个或许多个修正符,这些修正符不会改动移位操作自身,可是输入和输出成果会去除基准或许饱满到一个有用规模,有5种移位限定符:
- 舍入(round),运用R前缀,用于纠正右移切断导致的基准;
- 变窄(narrow),运用N前缀,标明向量中一切元素的位宽变窄为一半,即源是128-bit的Q寄存器,而成果是64-bit的D寄存器;
- 变长(long),运用L前缀,标明向量中一切元素的位宽变宽为两倍,即源是64-bit的D寄存器,而成果是128-bit的Q寄存器;
- 饱满(saturate),运用Q前缀,把成果元素变成其能标明的最大和最小值规模内,位宽比特数和符号类型来标明该元素的有用规模;
- 无符号的饱满(Unsigned Saturating),运用Q前缀,U后缀,相似于饱满限定符,但成果会饱满到无符号数据规模,不论输入是有符号仍是无符号的;
这些限定符的有些组合起来不能描绘有用的操作,因此NEON并不包括这些指令。比方相似VQSHR的饱满右移并不需求,由于右移会让数据变小,不会超越有用规模。
有用的移位操作表格
一切NEON支撑的移位指令如下表所示,他们依照上面说到的限定符摆放。

图3. NEON支撑的移位操作,用当即数标明的移位数和用寄存器标明的
色深转化的比方
色深转化是图画处理中经常用到的。一般输入数据是RGB565 16-bit色度格局,需求转化成RGB888格局才更适合于NEON这种并行处理。 但是NEON仍是能处理RGB565的数据的,这就需求用到前面说到的移位指令了。

图4. RGB888和RGB565的色度格局
从RGB565到RGB888
首要看怎么从RGB565转化成RGB888,假定输入的8个16-bit的像素保存到寄存器Q0,咱们想把重量别离成R通道,G通道和B通道,保存到d2到d4寄存器。
vshr.u8 q1, q0, #3 @ 把R通道右移3比特,丢掉G通道比特
vshrn.i16 d2, q1, #5 @ 右移并变窄,获得R重量数据到d2寄存器
vshrn.i16 d3, q0, #5 @ 右移并变窄获得G重量数据
vshl.i8 d3, d3, #2 @ 左移G重量2个比特,丢掉R重量部分,一起把G重量保存到正确的方位;
vshl.i16 q0, q0, #3 @ 把B重量左移到最重要的8-bit数据
vmovn.i16 d4, q0 @ 丢地依然有的R和G重量,保存B重量为8-bit
这些指令的意义能够参阅注释处,根本上完结的操作便是去除接近通道的不必的色度数据,然后持续移位把色度重量的值到最高位。
一个小问题
你或许注意到,这样转化成RGB888格局后,本来的白就不是彻底的白色了,这是由于R和B重量是左移3bit,而G重量则只左移两bit,因此如RGB565值(0x1F, 0x3F, 0x1F)变成RGB888 (0xF8, 0xFC, 0xF8),并不跟曾经的标明色彩共同。
从RGB888到RGB565
从RGB888转化成RGB565,假定RGB888的输入是用上面代码标明的方式,独自通道的重量保存在从寄存器d0到d2,成果保存到16-bit的RGB565格局到q2寄存器。
vshll.u8 q2, d0, #8 @ 左移赤色重量到16bit成果中的最重要的5bit
vshll.u8 q3, d1, #8 @ 左移绿色重量数据到16bit最重要的8比特
vsri.16 q2, q3, #5 @ 移位绿色重量,并刺进到赤色元素寄存器里。
vshll.u8 q3, d2, #8 @ 左移赤色重量到16bit成果中的最重要的8-bit
vsri.16 q2, q3, #11 @ 把蓝色重量刺进到赤色和绿色重量后边
根本操作是把重量扩展成16-bit,然后右移刺进指令把重量放到适宜的方位;
总结
NEON供给了功能强大的移位指令,能完结:
- 快速的把数据乘以或许除以2,并带有舍入和饱满操作;
- 移位并复制若干比特从一个 向量到另一个向量;
- 中心计算成果在高精度,而把成果累加到低精度。