Cortex-A9的NEON多媒体处理器是依据ARMv7的SIMD(Single Instruction Multiple Data)和向量浮点VFPv3(Vector Floating-Point)指令集的,在详细的芯片规划中NEON组件是可选的,NEON处理器是面向音频、视频编解码器、图画处理和语音信号处理以及其他的基带等信息处理范畴的。 本文介绍了NEON处理器的根本架构、NEON处理器的并发情况下Cortex-A8和Cortex-A9的差异、NEON的寄存器组和数据类型、NEON编程的针对编译器、汇编器的优化办法以及其他的进步功用的并行办法。

图1. ARM体系结构的演进
Cortex-A9处理器简介
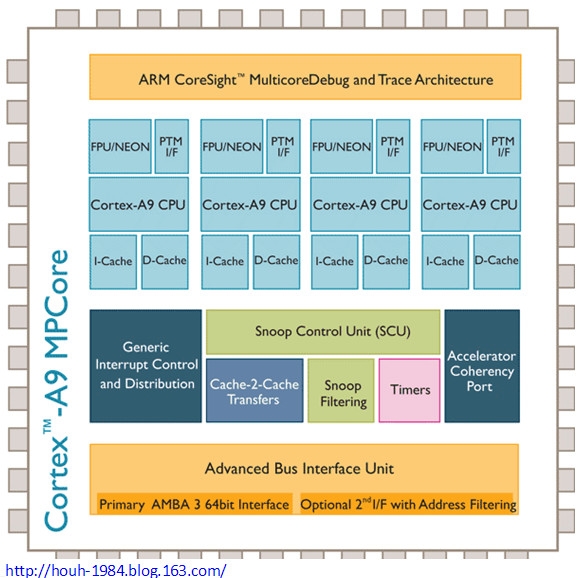
图2. Coretex-A9处理器的架构框图(View Larger Cortex-A9处理器Image)
Cortex-A9是功用最高的ARM处理器,可完结遭到广泛支撑的ARMv7体系结构的丰厚功用。Cortex-A9处理器的规划旨在打造最先进的、高效率的、长度动态可变的、多指令履行超标量体系结构,供给选用乱序猜想办法履行的8阶段管道处理器,凭仗规模广泛的消费类、网络、企业和移动运用中的前沿产品所需的功用,它能够供给前所未有的高功用和高能效。ARMCortex?-A9处理器供给了前所未有的高功用和高能效,然后使其成为需求在低功耗或散热受限的本钱灵敏型设备中供给高功用的规划的抱负解决方案。它既可用作单核处理器,也可用作可装备的多核处理器,一同可供给可组成或硬宏完结。该处理器适用于各种运用范畴,然后能够对多个商场进行安稳的软件出资。
Cortex-A9微体系结构既可用于可弹性的多核处理器(Cortex-A9 MPCore?多核处理器),也可用于更传统的处理器(Cortex-A9单核处理器)。可弹性的多核处理器和单核处理器支撑16、32或64KB 4路相关的L1高速缓存装备,关于可选的L2高速缓存操控器,最多支撑8MB的L2高速缓存装备,它们具有极高的灵敏性,均适用于特定运用范畴和商场。
下载Cortex-A9白皮书
窗体顶端
与高功用核算渠道耗费的功率比较,ARM Cortex-A9处理器可供给功率更低的杰出功用,其间包含:
-
无与伦比的功用,2GHz标准操作可供给TSMC 40G硬宏完结
-
以低功耗为方针的单核完结,面向本钱灵敏型设备
-
运用高档MPCore技能,最多可扩展为4个共同的内核
-
可选NEON?媒体和/或浮点处理引擎
经过同享以下常见需求,Cortex-A9处理器可供给满足各种不同商场运用需求的可扩展解决方案,包含移动手机以及高功用的消费类产品和企业产品:
-
经过进步功用、下降功耗来进步能效;
-
进步最高功用,满足要求更高的运用需求;
-
能够在多个设备之间同享软件和东西出资;
Cortex-A9 MPCore多核处理器集成了经验证十分成功的ARM MPCore技能以及更多增强功用,以此简化了多核解决方案,并使其运用规模得到扩展。Cortex-A9 MPCore处理器可供给前所未有的可扩展的最高功用,一同还支撑灵敏规划和新功用,然后进一步下降和操控处理器和体系级的能耗。凭借Cortex-A9 MPCore处理器的定向完结,移动设备的最高功用还可在现在的解决方案的基础上不断进步,详细办法是:运用规划灵敏性和ARM MPCore技能供给的高档功率办理技能,在散热受限以及移动电源预算严重的情况下保持运转。运用可弹性的最高功用,该处理器可超越如今相似的高功用嵌入式设备的功用,并可在拓展商场的基础上进行安稳的软件出资。
Cortex-A9多核处理器是首款结合了Cortex运用级架构以及用于可扩展功用的多处理才干的ARM处理器,供给了下列增强的多核技能:
*加快器共同性端口(ACP),用于进步体系功用和下降体系能耗
*先进总线接口单元(Advanced Bus Interface Unit),用于在高带宽设备中完结低延迟时刻
*多核TrustZone® 技能,结合中止虚拟,答应依据硬件的安全和加强的类虚拟(paravirtualization)解决方案
*通用中止操控器(GIC),用于软件移植和优化的多核通讯
Cortex-A9 NEON媒体处理引擎(MPE)
Cortex-A9 MPE可用于任一Cortex-A9处理器,并可供给一个具有Cortex-A9浮点单元的功用和功用以及NEON高档SIMD指令集完结的引擎,以便进一步进步媒体和信号处理功用的速度。MPE可扩展Cortex-A9处理器的浮点单元(FPU),供给一个quad-MAC以及附加的64位和128位寄存器集,在每个周期8位、16位和32位整型以及32位浮点数据量的基础上支撑一组丰厚的SIMD操作。
Cortex-A9浮点单元(FPU)
在与任一Cortex-A9处理器一同完结时,FPU可供给与ARM VFPv3体系结构兼容的高功用的单双精度浮点指令,该体系结构是与上一代ARM浮点协处理器兼容的软件。
物理IP:供给在Cortex-A9处理器上完结低功耗、高功用运用所需的许多标准单元库和存储器。标准单元包含功耗办理东西包,可完结动态和漏泄功耗节省技能,例如时钟门控、多电压岛和功率门控。还供给具有先进的功耗节省功用的存储编译器。
· Fabric IP:Cortex-A9处理器得到广泛的PrimeCell® fabric IP元件的支撑。这些元件包含:一个动态存储操控器、一个静态存储操控器、一个AMBA® 3 AXI可装备的内部互连及一个优化的L2 Cache 操控器,用于匹配Cortex-A9处理器在高频规划中的功用和吞吐才干。
· 图形加快: ARM Mali? 图形处理单元及Cortex-A9处理器的组合,将使得SoC协作活动能够发明高度整合的体系级解决方案,带来最佳的尺度、功用和体系带宽优势。
· 体系规划:ARM RealView® SoC Designer东西供给快速的架构优化和功用剖析,并答应在硬件完结曾经很长时刻即可进行软件驱动程序和对时刻要求很严厉的代码的前期开发。RealView体系发生器(RealView System Generator)东西为依据Cortex-A9处理器的虚拟渠道的选用供给超快建模才干。Realview东西中关于Cortex-A9处理器的依据周期的(cycle based)及程序员视角的模型将于2008年第二季度上市。
· 调试: ARM CoreSight?片上技能加快了杂乱调试的时刻,缩短了上市时刻。程序追寻宏单元技能(Program Trace Macrocell technology)具有程序流追寻才干,能够将处理器的指令流彻底可视化,一同装备与ARMv7架构兼容的调试接口,完结东西标准化和更高的调试功用。用于Cortex-A9处理器的CoreSight规划东西包扩展了其调试和追寻才干,以包含整个片上体系,包含多个ARM处理器、DSP以及智能外设。
· 软件开发:ARM RealView开发套件(ARM RealView Development Suite)包含先进的代码生成东西,为Cortex-A9处理器供给杰出的功用和无以比较的代码密度。这套东西还支撑矢量编译,用于NEON媒体和信号处理扩展集,使得开发者无需运用独立的DSP,然后下降产品和项目本钱。包含先进的穿插触发在内的Cortex-A9 MPCore多核处理器调试得到RealView %&&&&&%E和Trace产品的支撑,一同也得到一系列硬件开发板的支撑,用于FPGA体系原型规划和软件开发。
作为许多下一代设备的中心,Cortex-A9处理器一般与许多其他IP块集成。
体系IP
体系IP组件关于在芯片上构建杂乱的体系至关重要,经过运用体系IP组件,开发人员能够明显缩短开发和验证周期,然后节省本钱并缩短产品的上市时刻。
东西支撑
一切ARM处理器均受ARM RealView?系列开发东西以及各种第三方东西、操作体系和EDA供货商的支撑。ARM RealView东西绝无仅有,所供给的解决方案触及从概念到终究产品布置的整个开发进程。
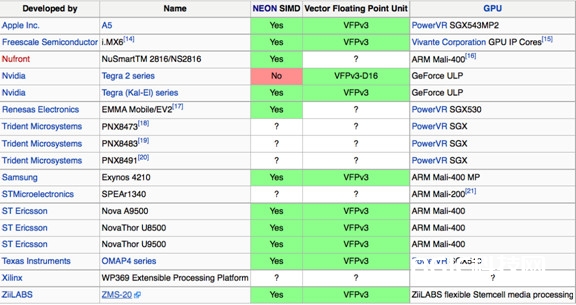
图3. 依据Coretex-A9核的首要芯片
NEON多媒体SIMD引擎简介
NEON是一个SIMD数据处理架构,256字节的寄存器堆包含32个64-bit位宽的寄存器或许16个128-bit位宽的寄存器。一切的寄存器都被视为具有相同数据类型的一个向量,支撑的数据类型包含有符号或许无符号的8-bit、16-bit、32-bit和64-bit的整型数据或许单精度浮点数据。NEON指令都是针对相同数据类型的通道处理的,即一切通道履行相同的指令操作。如下图4所示。
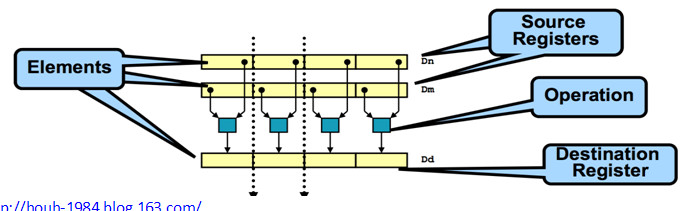
图4. ARM NEON处理器的SIMD操作
NEON的寄存器组:NEON和VFPv3 浮点协处理器同享寄存器组,这些寄存器和ARM核的寄存器天壤之别,NEON还会选用ARM的寄存器作为地址寄存器直接寻址。图5是NEON寄存器的视图,16个128-bit的4字节寄存器Q0~Q15,或许32个64bit的双字寄存器D0~D31,VFPv3的寄存器堆还有32个32-bit的寄存器S0~S31.

图5. NEON和VFPv3协处理器的寄存器堆视图
NEON指令支撑的操作数类型包含:有符号或许无符号的8-bit、16-bit、32-bit和64-bit的整型数据(I8、S8、U8、I16、S16、U16、I32、S32、U32、I64、S64、U64)或许单精度浮点数据(F32)。
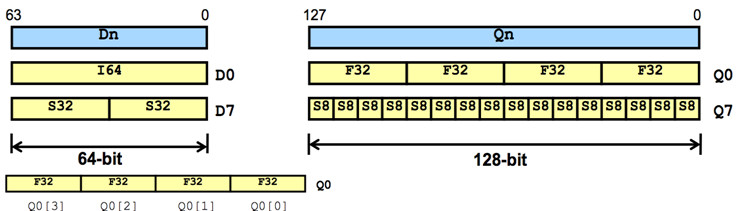
图6. 单个寄存器组的元素分配
NEON支撑的一些数据拜访:支撑非对齐拜访但对齐的拜访速度更快,能够经过拜访@bits来指定地址对齐的位数,如@32、@64、@128等。加载和存储支撑打包的数据类型,即能够有2、3、4个通道的interleave的数据加载和存储,还能在标量和向量间进行数据的移动,可是速度比较慢、还能支撑单精度浮点的数据运算。
NEON指令集
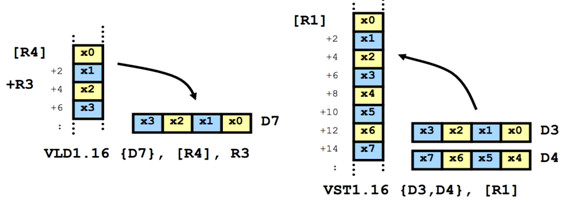
图7. NEON的线性加载和存储指令

图8. 交错的数据加载和存储指令

图9. 运用结构化的加载指令加载RGB数据
vld1.32 {d16-d19}, [r1]!
vmul.f32 q12, q8, d0[0]
vmla.f32 q12, q9, d0[1]
vst1.32 {d24-d27}, [r0]!
NEON的并行优化办法
ARM编译器优化办法
NEON并行化和向量化的编译选项:ARM RVDS 3.0以上版别或许DS-5运用编译选项armcc –vectorize或许Codesourcery 2007q3之后的gcc版别运用如下编译选项使能vfp:-mcpu=cortex-a8 -mtune=cortex-a8 -O3 -mfloat-abi=softfp -mfpu=vfp或许运用-mcpu=cortex-a8 -mtune=cortex-a8 -O3 -mfloat-abi=softfp -mfpu=neon -ftree-vectorize来使能NEON的并行处理。一般认为RVDS或许DS-5编译器的armcc针对并行处理功用很差,即便调整算法的结构以合适编译器进行NEON指令的优化,可是生成的代码仍是难以让人满足。而GCC的主动并行化处理的成果功用更差,针对Android开发,只能选用Google供给的NDK的GCC东西链能够用来开发。但ARM EABI供给了编译器支撑的C内联intrinsics。能够参阅ARM V7-A的 ABI手册以及arm_neon.h文件。
ARM汇编器的优化办法
运用NEON的intrinsic指令进行优化需求对NEON的指令集十分了解,并且运用intrinsics无法操控寄存器分配和内存对齐等,因此许多的NEON的优化仍是依据汇编代码。当然手艺写汇编代码总是需求许多的额定开支的,并且还要了解ARM EABI编程标准。
NEON编程优化的根本办法
一般NEON优化是针对需求很多数据处理的函数,而函数的根本操作都是先加载数据,然后进行数据处理,最终把核算的成果保存到内存。首要针对NEON数据的加载和存储,能够参阅http://houh-1984.blog.163.com/blog/static/3112783420111159169507/,即恰当考虑结构化的加载/存储以有用的进行数据加载成为有利于并行处理的办法,当然除了数据加载有利于并行处理,还要考虑数据加载有利于cache功用的优化。然后选用NEON指令进行核算,针对数据拜访,能够考虑运用Q0~Q3的参数寄存器以及Q8~Q15寄存器,而关于Q4~Q7寄存器则有必要依据EABI的标准在函数调用内保存。
别的便是关需数据的加载类型,一个是数据的对齐,尽管NEON彻底支撑非对齐拜访,可是对齐数据一个是有利于加载、存储,别的一个是也更cache友爱,非对齐的数据拜访要耗费更多的时钟周期尤其是在非对齐还要跨过cache行的情况下,数据对齐办法能够选用[
Vld1.8 {D0}, [R1:64]
Vld1.8 {D0,D1}, [R1:128]!
Vld1.8 {D0,D1,D2,D3}, [R2:256]!,R3
Cortex-A8和Cortex-A9的多指令并发有所不同,A8是每次并发两次fetch,而A9除了屡次并发外,还能乱序履行,因此指令重排的优化十分重要。一般来说NEON的SIMD优化能进步至少2倍的体系功用,取决于实践处理的位宽。
http://houh-1984.blog.163.com/
http://baike.baidu.com/view/2937500.htm
http://www.arm.com/zh/products/processors/cortex-a/cortex-a9.php
Cortex-A9的NEON多媒体处理器是依据ARMv7的SIMD(Single Instruction Multiple Data)和向量浮点VFPv3(Vector Floating-Point)指令集的,在详细的芯片规划中NEON组件是可选的,NEON处理器是面向音频、视频编解码器、图画处理和语音信号处理以及其他的基带等信息处理范畴的。 本文介绍了NEON处理器的根本架构、NEON处理器的并发情况下Cortex-A8和Cortex-A9的差异、NEON的寄存器组和数据类型、NEON编程的针对编译器、汇编器的优化办法以及其他的进步功用的并行办法。