首要,咱们要知道在zImage的生成进程中,是把arch/arm/boot/compressed/head.s和解压代码misc.c,decompress.c加在紧缩内核的最前面终究生成zImage的,那么它的发动进程便是从这个head.s开端的,而且假如代码从RAM运转的话,是与方位无关的,能够加载到内存的任何当地。
下面以arch/arm/boot/compressed/head.s为主线进行发动进程解析。
1.head.s的debug宏界说部分
最开端的一段都是head.s的debug宏界说部分,这部分能够便利咱们调试时运用。
如下:
#ifdefDEBUG
#if defined(CONFIG_DEBUG_ICEDCC)
#if defined(CONFIG_CPU_V6) defined(CONFIG_CPU_V6K) defined(CONFIG_CPU_V7)
.macro loadsp, rb, tmp
.endm
.macro writeb, ch, rb
mcrp14, 0, \ch, c0, c5, 0
.endm
#elif defined(CONFIG_CPU_XSCALE)
.macro loadsp, rb, tmp
.endm
.macro writeb, ch, rb
mcrp14, 0, \ch, c8, c0, 0
.endm
#else
.macro loadsp, rb, tmp
.endm
.macro writeb, ch, rb
mcrp14, 0, \ch, c1, c0, 0
.endm
#endif
#else
#include
.macro writeb, ch, rb
senduart \ch, \rb
.endm
#if defined(CONFIG_ARCH_SA1100)
.macro loadsp, rb, tmp
mov\rb, #0x80@ physical base address
#ifdef CONFIG_DEBUG_LL_SER3
add \rb, \rb, #0x50 @ Ser3
#else
add \rb, \rb, #0x10 @ Ser1
#endif
.endm
#elif defined(CONFIG_ARCH_S3C2410)
.macro loadsp, rb, tmp
mov\rb, #0x50
add \rb, \rb, #0x4 * CONFIG_S3C_LOWLEVEL_UART_PORT
.endm
#else
.macro loadsp, rb, tmp
addruart \rb, \tmp
.endm
#endif
#endif
#endif
假如敞开DEBUGging宏的话,这部分代码分两段CONFIG_DEBUG_ICEDCC是用ARMv6以上的加构支撑的ICEDCC技能进行调试,DCC(Debug Communications Channel)是ARM的一个调试通讯通道,在串口无法运用的时分能够运用这个通道进行数据的通讯,详细的技能参前ARM公司文档《ARM Architecture Reference Manual》。
第二部分首要#include
#include
#include
.macroaddruart, rp, rv
ldr \rp, =ARM_EVB_UART0_BASE@ System peripherals (phys address)
ldr \rv, =(IO_BASE+ ARM_EVB _UART0_BASE)@ System peripherals (virt address)
.endm
.macrosenduart,rd,rx
strb\rd, [\rx, #(0x00)]@ Write to Transmitter Holding Register
.endm
.macrowaituart,rd,rx
1001:ldr \rd, [\rx, #(0x18)]@ Read Status Register
tst \rd, #0x20@when TX FIFOFull, then wait
bne 1001b
.endm
.macrobusyuart,rd,rx
1001:ldr \rd, [\rx, #(0x18)]@ Read Status Register
tst \rd, #0x08@ when uart is busy then wait
bne 1001b
.endm
首要完结addruart,senduart,waituart,busyuart这四个函数的详细施行。这个是调试函数打印的根底。
下面是调试打印用到的kputc和kphex
.macrokputc,val
movr0, \val
blputc
.endm
.macrokphex,val,len
movr0, \val
movr1, #\len
blphex
.endm
它所调用的putc和phex是在head.s终究的一段界说的,如下
#ifdef DEBUG
.align2
.typephexbuf,#object
phexbuf:.space12
.sizephexbuf, . – phexbuf
上面是分配打印hex的buffer,下面是详细的完结:
@ phex corrupts {r0, r1, r2, r3}
phex:adr r3, phexbuf
movr2, #0
strbr2, [r3, r1]
1:subsr1, r1, #1
movmi r0, r3
bmiputs
and r2, r0, #15
movr0, r0, lsr #4
cmpr2, #10
addger2, r2, #7
add r2, r2, #0
strbr2, [r3, r1]
b1b
@ puts corrupts {r0, r1, r2, r3}
puts:loadspr3, r1
1:ldrbr2, [r0], #1
teq r2, #0
moveqpc, lr
2:writebr2, r3
movr1, #0x20
3:subsr1, r1, #1
bne 3b
teq r2, #\n
moveqr2, #\r
beq 2b
teq r0, #0
bne 1b
movpc, lr
@ putc corrupts {r0, r1, r2, r3}
putc:
movr2, r0
movr0, #0
loadspr3, r1
b2b
@ memdump corrupts {r0, r1, r2, r3, r10, r11, r12, lr}
memdump:movr12, r0
movr10, lr
movr11, #0
2:movr0, r11, lsl #2
add r0, r0, r12
movr1, #8
blphex
movr0, #:
blputc
1:movr0, #
blputc
ldrr0, [r12, r11, lsl #2]
movr1, #8
blphex
and r0, r11, #7
teq r0, #3
moveqr0, #
bleqputc
and r0, r11, #7
add r11, r11, #1
teq r0, #7
bne 1b
movr0, #\n
blputc
cmpr11, #64
blt2b
movpc, r10
#endif
嘿嘿,还有memdump这个函数能够用,不错。
好了,言归正传,再往下看,代码如下:
.macrodebug_reloc_start
#ifdef DEBUG
kputc#\n
kphexr6, 8
kputc#:
kphexr7, 8
#ifdef CONFIG_CPU_CP15
kputc#:
mrcp15, 0, r0, c1, c0
kphexr0, 8
#endif
kputc#\n
kphexr5, 8
kputc#-
kphexr9, 8
kputc#>
kphexr4, 8
kputc#\n
#endif
.endm
.macrodebug_reloc_end
#ifdef DEBUG
kphexr5, 8
kputc#\n
movr0, r4
blmemdump
#endif
.endm
debug_reloc_start
用来打印出一些代码重定位后的信息,关于重定位,后边会说,debug_reloc_end
用来把解压后的内核的256字节的数据dump出来,查看是否正确。很不幸的是,这个不是有必要调用的,调试的时分,这些都是要自己把这些调试函数加上去的。好debug部分到这儿就完了。
2.head.s的.start部分,进入或保持在svc形式,并关中止
持续向下剖析,下面是界说.start段,这段在链接时被链接到代码的最最初,那么zImage发动时,最早履行的代码也便是下面这段代码start开端的,如下:
.section”.start”, #alloc, #execinstr
.align
.arm@ Always enter in ARM state
start:
.typestart,#function
.rept7
movr0, r0
.endr
ARM(movr0, r0)
ARM(b1f)
THUMB(adr r12, BSYM(1f))
THUMB(bxr12)
.word0x016f2818@ Magic numbers to help the loader
.wordstart@ absolute load/run zImage address
.word_edata@ zImage end address
THUMB(.thumb)
1:movr7, r1@ save architecture ID
movr8, r2@ save atags pointer
#ifndef __ARM_ARCH_2__
mrsr2, cpsr@ get current mode
tstr2, #3@ not user?
bne not_angel
movr0, #0x17@ angel_SWIreason_EnterSVC
ARM(swi 0x123456)@ angel_SWI_ARM
THUMB(svc 0xab)@ angel_SWI_THUMB
not_angel:
mrsr2, cpsr@ turn off interrupts to
orr r2, r2, #0xc0@ prevent angel from running
msrcpsr_c, r2
#else
teqppc, #0x0c003@ turn off interrupts
#endif
为何这个会先履行呢?问的好。那么来个中止吧:这个是由arch/arm/boot/compressed/vmlinux.lds的链接脚本决议的,如下:
.text : {
_start = .;
*(.start)
*(.text)
*(.text.*)
*(.fixup)
*(.gnu.warning)
*(.rodata)
*(.rodata.*)
*(.glue_7)
*(.glue_7t)
*(.piggydata)
. = ALIGN(4);
}
怎么样,看到没,.text段最开端的一部分便是.start段,所以这就注定了它便是最早履行的代码。
好了,中止完毕,再回到从前面的代码,这段代码的最开端是会被编译器编译成8个nop,这个是为了留给ARM的中止向量表的,可是整个head.s都没有用到中止啊,谁知道告诉我一下,谢了。
然后呢,把u-boot传过来的放在r1,r2的值,存在r7,r8中,r1存是的evb板的ID号,而r2存的是内核要用的参数地址,这两个参数在解压内核的时分不要用到,所以暂时保存一下,解压内枋完了,再传给linux内核。
再然后是几个宏界说的解说,ARM(),BSYM(),THUMB(),再加上W()吧,这几个个宏界说都是在arch/arm/include/asm/unified.h里鸿沟说的,好了,这儿也算个中止吧,如下:
#ifdefCONFIG_THUMB2_KERNEL
……
#defineARM(x…)
#defineTHUMB(x…)x
#ifdef __ASSEMBLY__
#defineW(instr)instr.w
#endif
#defineBSYM(sym)sym + 1
#else
……
#defineARM(x…)x
#defineTHUMB(x…)
#ifdef __ASSEMBLY__
#defineW(instr)instr
#endif
#defineBSYM(sym)sym
#endif
好的看到上面的界说你就会了解了,这儿是为了兼容THUMB2指令的内核。
关于#defineARM(x…)里边的“…”,没有见过吧,这个是C言语的C99的新标准,变参宏,便是在x里,你能够随意你输入多少个参数。别急还没有完,由于没有看见文件里有什么方包括这个头文件。是的文件中的确没有包括,它的界说是在:arch/arm/makefile中加上的:
KBUILD_AFLAGS+= -include asm/unified.h
行,这些宏解说到此,下面再呈现,我就无视它了。
好了,再回来,读取cpsr并判别是否处理器处于supervisor形式——从u-boot进入kernel,体系现已处于SVC32形式;而运用angel进入则处于user形式,还需求额定两条指令。之后是再次承认中止封闭,并完结cpsr写入。
注:Angel是ARM公司的一种调试办法,它本身便是一个调试监控程序,是一组运转在方针机上的程序,能够接纳主机上调试器发送的指令,履行比如设置断点、单步履行方针程序、调查或修正寄存器、存储器内容之类的操作。与根据jtag的调试署理不同,Angel调试监控程序需求占用必定的体系资源,如内存、串行端口等。运用angel调试监控程序能够调试在方针体系运转的arm程序或thumb程序。
好了,里边有一句:teqppc, #0x0c003@ turn off interrupts
是否很古怪,不过咱们千万不要纠结它,由于它是ARMv2架构曾经的汇编办法,用于形式改换,和中止封闭的,看不了解也不要紧,由于咱们今后也用不到。这儿知道一下有这个事就行了。
行,到这儿.start段就完了,代码那么多,其实便是做一件事,确保运转下面的代码时现已进入了SVC形式,并确保中止是关的,完了.start部分完毕。
3.。text段开端,先是内核解压地址的确认
再往下看,代码如下:
.text
#ifdefCONFIG_AUTO_ZRELADDR
@ determine final kernel image address
movr4, pc
and r4, r4, #0xf8
add r4, r4, #TEXT_OFFSET
#else
ldrr4, =zreladdr
#endif
额~~~~不要小这一段代码,东西许多啊。如哪下手呢?好吧,先从linux基本参数下手吧,见表.1,里边我写的很详细,由于表格我要放一页,解说我就写在上面了。TEXT_OFFSET是代码相关于物理内存的偏移,一般选为32k=0x8。这个是有原因的,详细的原因后边会说。先看CONFIG_AUTO_ZRELADDR这个宏所含的内容,它的意思是假如你不知道ZRELADDR地址要定在内存什么当地,那么这段代码就能够帮你。看到0xf8了吧,那么后边有多少个0呢?答案是27个,那么2的27次便利是128M,这就了解了,只需你把解压程序放在你终究解压完结后的内核空间的128M之内的偏移的话,就能够主动设定好解压后内核要运转的地址ZRELADDR。
假如你没有界说的话,那么,就会去取zreladdr作为终究解压的内核运转地。那么这个zreladdr是从哪里来的呢?答案是在:arch/arm/boot/compressed/Makefile中界说的
# Supply ZRELADDR to the decompressor via a linker symbol.
ifneq ($(CONFIG_AUTO_ZRELADDR),y)
LDFLAGS_vmlinux += –defsymzreladdr=$(ZRELADDR)
endif
ZRELADDR这又是哪里界说的呢?答案是在:arch/arm/boot/Makefile中界说的
ifneq ($(MACHINE),)
include $(srctree)/$(MACHINE)/Makefile.boot
endif
# Note: the following conditions must always be true:
#ZRELADDR == virt_to_phys(PAGE_OFFSET + TEXT_OFFSET)
#PARAMS_PHYS must be within 4MB of ZRELADDR
#INITRD_PHYS must be in RAM
ZRELADDR:= $(zreladdr-y)
PARAMS_PHYS:= $(params_phys-y)
INITRD_PHYS:= $(initrd_phys-y)
而里边的几个参数是在每个arch/arm/Mach-xxx/ Makefile.boot里鸿沟说的,内容如下:
zreladdr-y:= 0x28
params_phys-y:= 0x20100
initrd_phys-y:= 0x21
这下知道了,绕了一大圈,总算知道r4存的是什么了,便是终究内核解压的起址,也是终究解压后的内核的运转地址,记住,这个地址很重要。
|
解压内核参数 |
解压时symbol |
解说 |
|
ZTEXTADDR |
千成不要当作ZTE啊,呵,这儿是zImage的运转的开端地址,当内核从nor flash中运转的时分很重要,假如在ram中运转,这个设为0 |
|
|
ZBSSADDR |
这个地址也是相同的,这个是BSS的地址,假如在nor中运转解压的话,这个地址很重要。这个要放在RAM。 |
|
|
ZRELADDR |
这个地址很重要,这个是解压后内核寄存的地址,也是终究解压后内核的运转起址。 一般设为内存起址的32K之后,如ARM: 0x28 ZRELADDR = PHYS_OFFSET + TEXT_OFFSET |
|
|
INITRD_PHYS |
RAM disk的物理地址 |
|
|
INITRD_VIRT |
RAM disk的虚拟地址 __virt_to_phys(INITRD_VIRT) = INITRD_PHYS |
|
|
PARAMS_PHYS |
内核参数的物理地址 |
|
|
内核参数 |
PHYS_OFFSET |
实践RAM的物理地址 关于当时ARM来说,便是0x20 |
|
PAGE_OFFSET |
内核空间的如始虚拟地址,一般: 0xC0,高端1G __virt_to_phys(PAGE_OFFSET) = PHYS_OFFSET |
|
|
TASK_SIZE |
用户进程的内存的最太值(以字节为单位) |
|
|
TEXTADDR |
内核启运转的虚拟地址的起址,一般设为0xC8 TEXTADDR = PAGE_OFFSET + TEXT_OFFSET __virt_to_phys(TEXTADDR) = ZRELADDR |
|
|
TEXT_OFFSET |
相关于内存起址的内核代码寄存的偏移,一般设为32k (0x8) |
|
|
DATAADDR |
这个是内核数据段的虚拟地址的起址,当用zImage的时分不要界说。 |
表.1内核参数解说
4.翻开ARM体系的cache,为加速内核解压做好预备
能够看到,翻开cache的就一个函数,如下:
blcache_on
看起来很少,其实翻开后内容仍是许多的。咱们来看看这个cache_on在哪里,能够找到代码如下:
.align5
cache_on:movr3, #8@ cache_on function
bcall_cache_fn
这儿规划的很精妙的,只可意会,留意movr3, #8,不多解说,跟进去call_cache_fn:
call_cache_fn:adr r12,proc_types
#ifdefCONFIG_CPU_CP15
mrcp15, 0, r9, c0, c0@ get processor ID
#else
ldrr9, =CONFIG_PROCESSOR_ID
#endif
1:ldrr1, [r12, #0]@ get value
ldrr2, [r12, #4]@ get mask
eor r1, r1, r9@ (real ^ match)
tstr1, r2@& mask
ARM(addeqpc, r12,r3) @ call cache function
THUMB(addeqr12,r3)
THUMB(moveqpc, r12) @ call cache function
add r12, r12,#PROC_ENTRY_SIZE
b1b
首要看一下proc_types是什么,界说如下:
proc_types:
……
.word0xf0@ new CPU Id
.word0xf0
W(b)__armv7_mmu_cache_on
W(b)__armv7_mmu_cache_off
W(b)__armv7_mmu_cache_flush
…….
.word0@ unrecognised type
.word0
movpc, lr
THUMB(nop)
movpc, lr
THUMB(nop)
movpc, lr
THUMB(nop)
能够看到这是一个以proc_types为开端地址的表,上面我列出了榜首个表项,和终究一个表项,假如查表不成功,则走终究一个表项回来。它完结的功用便是存两个数据,三条跳转指令,咱们能够榜首条是它的值,第二条是它的mask值,三条跳转分别是:cache_on,cache_off,cache_flush。
我想从ARMv4指令向下都是有CP15协处理器的吧,故:CONFIG_CPU_CP15是界说的,那下面咱们来剖析指令吧。
mrcp15, 0, r9, c0, c0@ get processor ID
这个意思是获得ARM处理器的ID,这个又要看《ARM Architecture Reference Manual》了,这儿我找了arm1176jzfs的架构手册,也是我用的ARM所用的架构。里边的解说如下:
这儿咱们首要关怀Architecture这项,咱们的ARM这个值是: 0x410FB767,阐明用的是r0p7的release。
好了读取了这个值存入r9寄存器,然后运用算法(real ^ match) & mask,程序中:
( r9 ^r1)&r2,这儿r1存是是表中的榜首个CPU的ID值,r2是mask值,关于咱们的ARM,成果如下:
0x410FB767 ^ 0xf0 = 0x4100B767
0x4100B767 & 0xf0 = 0
故match上了,这个时分就会如下:
ARM(addeqpc, r12,r3) @ call cache function
咱们知道r3的值是0x8,那么r12表项的基址加上0x8就正好是表中的榜首条跳转指令:
W(b)__armv7_mmu_cache_on
了解了,为何r3要等于0x8了吧,假如要调用cache_off,那么只需把r3设为0xC就能够了。精妙吧。行接着往下看__armv7_mmu_cache_on,如下:
__armv7_mmu_cache_on:
movr12, lr
#ifdef CONFIG_MMU
mrcp15, 0, r11, c0, c1, 4@ read ID_MMFR0
tstr11, #0xf@VMSA见注:
blne__setup_mmu
注:VMSA (Virtual Memory System Architecture),其实便是虚拟内存,浅显地地说便是否支撑MMU。
首要是保存lr寄存器到r12中,由于咱们立刻就要调用__setup_mmu了,终究回来也只需用r12就能够了。然后再查看cp15的c7,c10,4看是否支撑VMSA,详细的见注解。咱们在这儿咱们的ARM肯定是支撑的,所以就要树立页表,预备翻开MMU,然后能够使能cache。
好了下面,便是跳到__setup_mmu进行建产页表的进程,代码如下:
__setup_mmu:sub r3, r4, #16384@ Page directory size
bicr3, r3, #0xff@ Align the pointer
bicr3, r3, #0x3f00
movr0, r3
movr9, r0, lsr #18
movr9, r9, lsl #18@ start of RAM
add r10, r9, #0x10@ a reasonable RAM size
movr1, #0x12
orr r1, r1, #3 << 10
add r2, r3, #16384
1:cmpr1, r9@ if virt > start of RAM
#ifdef CONFIG_CPU_DCACHE_WRITETHROUGH
orrhsr1, r1, #0x08@ set cacheable
#else
orrhsr1, r1, #0x0c@ set cacheable, bufferable
#endif
cmpr1, r10@ if virt > end of RAM
bichsr1, r1, #0x0c@ clear cacheable, bufferable
strr1, [r0], #4@ 1:1 mapping
add r1, r1, #1048576
teq r0, r2
bne 1b
关于MMU的常识又有许多啊,相同能够参看《ARM Architecture Reference Manual》,还能够看《ARM体系架构与编程》关于MMU的部分,我这儿只简略介绍一下咱们这儿用到MMU。这儿只运用到了MMU的段映,故我只介绍与此相关的部分。
关于段页的巨细ARM中为1M巨细,关于32位的ARM,可寻址空间为4G=4096M,故每一个页表项表明1M空间的话,需求4096个页表项,也便是4K巨细,而每一个页表项的巨细是4字节,这便是说咱们进行段映射的话,需求16K的巨细存储段页表。
下面来看一下段页表的格局,如下:
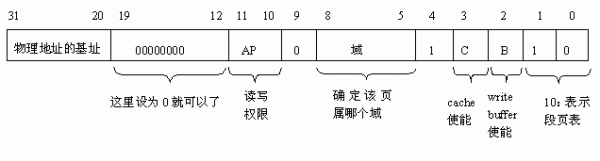
图.1段页表项的详细内容
能够知道关于进行mmu段映射这种方法,一共有4K个这样的页表项,点巨细16K字节。在这儿咱们的16k页表放哪呢?看程序榜首句:
__setup_mmu:sub r3, r4, #16384@ Page directory size
咱们知道r4存内核解压后的基址,那么这句便是把页表放在解压后的内核地址的前面16K空间如下图所示:
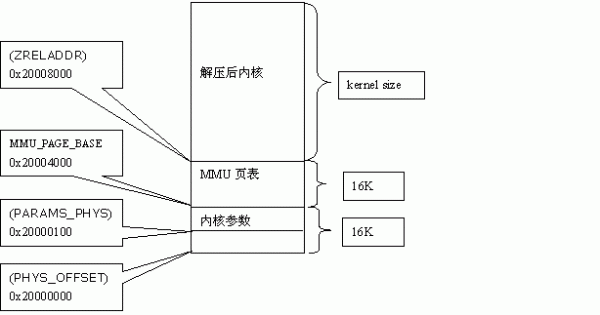
图.2 linux内核地址空间
(里边地址是用的是以我用的ARM为例的)
好了,再回到MMU,从MMU_PAGE_BASE (0x24)树立好页表后,ARM的cpu怎么知道呢?这个便是要用到CP15的C2寄存器了,页表基址便是存在这儿边的,其间[31:14]为内存中页表的基址,[13:0]应为0如下图:

图.3 CP15的C2寄存器中的页表项基址格局
所以咱们初始化完段页表后,就要把页表基址MMU_PAGE_BASE (0x24)存入CP15的C2寄存器,这样ARM就知道到哪里去找那些页表项了。下面咱们来看一下整个MMU的虚拟地址的寻址进程,如图4所示。
简略解说一下。首要,ARM的CPU从CP15的C2寄存器中找取出页表基地址,然后把虚拟地址的最高12位左移两位变为14位放到页表基址的低14位,组合成对应1M空间的页表项在MMU页表中的地址。然后,再取出页表项的值,查看AP位,域,判别是否有读写的权限,假如没有权限测会抛出数据或指令反常,假如有权限,就把最高12位取出加上虚拟地址的低20位段内偏移地址组合成终究的物理地址。到这儿整个MMU从虚拟地址到物理地址的转化进程就完结了。
这段代码里,只会敞开页表地点代码的开端的256K对齐的一个0x10(256M)空间的巨细(这个空间必定包括解压后的内核),使能cache和write buffer,其他的4G-256M的空间不敞开。这儿运用的是1:1的映射。到这儿也很简单了解MMU和cache和write buffer的关系了,为什么不开MMU无法运用cache了。
图.4 MMU的段页表的虚拟地址与物理地址的转化进程
这儿的4G空间悉数映射完结之后,还会做一个映射,代码如下:
movr1, #0x1e
orr r1, r1, #3 << 10
movr2, pc
movr2, r2, lsr #20
orr r1, r1, r2, lsl #20
add r0, r3, r2, lsl #2
strr1, [r0], #4
add r1, r1, #1048576
strr1, [r0]
movpc, lr
通过注释就能够知道把当时PC地点地址1M对齐的当地的2M空间敞开cache和write buffer为了加速代码在nor flash中运转的速度。然后反回,到这儿16K的MMU页表就彻底树立好了。
然后再反回到树立页表后的代码,如下:
movr0, #0
mcrp15, 0, r0, c7, c10, 4@ drain write buffer
tstr11, #0xf@ VMSA
mcrnep15, 0, r0, c8, c7, 0@ flush I,D TLBs
#endif
mrcp15, 0, r0, c1, c0, 0@ read control reg
bicr0, r0, #1 << 28@ clear SCTLR.TRE
orr r0, r0, #0x5@ I-cache enable, RR cache replacement
orr r0, r0, #0x003c@ write buffer
#ifdef CONFIG_MMU
#ifdef CONFIG_CPU_ENDIAN_BE8
orr r0, r0, #1 << 25@ big-endian page tables
#endif
orrner0, r0, #1@ MMU enabled
movner1, #-1
mcrnep15, 0, r3, c2, c0, 0@ load page table pointer
mcrnep15, 0, r1, c3, c0, 0@ load domain access control
#endif
mcrp15, 0, r0, c1, c0, 0@ load control register
mrcp15, 0, r0, c1, c0, 0@ and read it back
movr0, #0
mcrp15, 0, r0, c7, c5, 4@ ISB
movpc, r12
这段代码就不详细解说了,多数是关于CP15的操控寄存器的操作,首要是flush I-cache,D-cache, TLBS,write buffer,然后存页表基址啊,终究翻开MMU这个是终究一步,前面一切东西都设好之后再运用MMU,不然体系就会挂掉。终究用保存在r12中的地址,反回到BL cache_on的下一句代码。如下:
restart:adr r0,LC0
ldmiar0, {r1, r2, r3, r6, r10, r11, r12}
ldrsp, [r0, #28]
sub r0, r0, r1@ calculate the delta offset
add r6, r6, r0@ _edata
add r10, r10, r0@ inflated kernel size location
好了,先来看一下LC0是什么东西吧。
.align2
.typeLC0, #object
LC0:.wordLC0@ r1
.word__bss_start@ r2
.word_end@ r3
.word_edata@ r6
.wordinput_data_end – 4 @ r10 (inflated size location)
.word_got_start@ r11
.word_got_end@ ip
.word.L_user_stack_end@ sp
.sizeLC0, . – LC0
好吧,要了解它,再把arch/arm/boot/vmlinux.lds.in搬出来吧:
_got_start = .;
.got: { *(.got) }
_got_end = .;
.got.plt: { *(.got.plt) }
_edata = .;
. = BSS_START;
__bss_start = .;
.bss: { *(.bss) }
_end = .;
. = ALIGN(8);
.stack: { *(.stack) }
.align
.section “.stack”, “aw”, %nobits
再加上终究一段代码,关于stack的空间的巨细分配:
.L_user_stack:.space4096
.L_user_stack_end:
这儿不只能够看到各个寄存器里所存的值的意思,还能够看到. = BSS_START;在这儿的效果
arch/arm/boot/compressed/Makefile里边:
ifeq ($(CONFIG_ZBOOT_ROM),y)
ZTEXTADDR:= $(CONFIG_ZBOOT_ROM_TEXT)
ZBSSADDR := $(CONFIG_ZBOOT_ROM_BSS)
else
ZTEXTADDR:= 0
ZBSSADDR := ALIGN(8)
endif
SEDFLAGS = s/TEXT_START/$(ZTEXTADDR)/;s/BSS_START/$(ZBSSADDR)/
对应到这儿的话,便是BSS_START =ALIGN(8),这个替换进程会在vmlinux.lds.in到vmlinux.lds的进程中完结,这个进程首要是为了有些内核在nor flash中运转而设置的。
好了,再次言归正传,从vmlinux.lds文件,能够看到链接后各个段的方位,如下。
图.5 zImage各个段的方位
从这儿能够看到,zImage在RAM中运转和在NorFlash中直接运转是有些差异的,这便是为何前面要差异ZTEXTADDR和ZBSSADDR的原因了。
好了,再看下面这两句的差异,假如这个当地弄了解了,那么,下面的内容就会变得很简略,往下看:
restart:adr r0,LC0
addr0,pc,#0x10C
LC0:.wordLC0@ r1
dcd0x17C
故可知,当zImage加到0x28运转时,PC值为:0x28070,这个时分r0=0x2817C
而通过ldmiar0, {r1, r2, r3, r6, r10, r11, r12}加载内存值后,r1=0x17C
那么咱们看一看这句:sub r0, r0, r1@ calculate the delta offset的值是多少?如下:
r0=0x2817C-0x17C =0x28
see~~~看出来什么没有,这个便是咱们的加载zImage运转的内存开端地址,这个很重要,后边就要靠它知道咱们当时的代码在哪里,搬移到哪里。然后再下一条指令把仓库指针设置好。然后再把实践代码偏移量加在r6=_edata和(r10=input_data_end-4)上面,这便是实践的内存中的地址。好持续往下看:
ldrbr9, [r10, #0]
ldrblr, [r10, #1]
orr r9, r9, lr, lsl #8
ldrblr, [r10, #2]
ldrbr10, [r10, #3]
orr r9, r9, lr, lsl #16
orr r9, r9, r10, lsl #24
紧缩的东西会把所紧缩后的文件的终究加上用小端格局表明的4个字节的尾,用来存储所压内容的原始巨细,这个信息很要,是咱们后边分配空间,代码重定位的重要依据。这儿为何要一个字节,一个字节地取,只由于要兼容ARM代码运用大端编译的状况,确保读取的正确无误。好了,再往下:
#ifndef CONFIG_ZBOOT_ROM
add sp, sp, r0
add r10, sp, #0x10
#else
movr10, r6
#endif
咱们这儿在RAM中运转,所以加上重定位SP的指针,加上偏移里,变成实践地点内存的仓库指针地址。这儿首要是为了后边的查看代码是否要进行重定位的时分所提早设置的,由于假如代码不重定位,就不会再设仓库指针了,重定位的话,则还要重设一次。然后再在仓库指针的上面拓荒一块64K巨细的空间,用于解压内核时的暂时buffer。
再往下看:
add r10, r10, #16384//16K MMU页表也不能被掩盖哦,不然解压到复盖后,ARM就挂了。
cmpr4, r10
bhswont_overwrite
add r10, r4, r9
ARM(cmpr10, pc)
THUMB(movlr, pc)
THUMB(cmpr10, lr)
blswont_overwrite
这段的检测有点绕人,两种状况都画个图看一下,如图.6所示,下面咱们来看剖析两种不会掩盖的状况:
榜首种状况是加载运转的zImage鄙人,解压后内核运转地址zreladdr在上,这种状况假如最上面的64k的解压buffer不会掩盖到内核前的16k页表的话,就不必重定位代码跳到wont_overwrite履行。
第二种状况是加载运转的zImage在上,而解压的内核运转地址zreladdr鄙人面,只需终究解压后的内核的巨细加上zreladdr不会到当时pc值,则也不会呈现代码掩盖的状况,这种状况下,也不必重位代码,直接跳到wont_overwrite履行就能够了。
图.6内核的两种解压不要重定位的状况
能够咱们一般加载的zImage的地址,和终究解压的zreladdr的地址是相同的,那么,就必定会发生代码掩盖的问题,这时分就要进行代码的自搬移和重定位。详细完结如下:
add r10, r10, #((reloc_code_end-restart+ 256) & ~255)
bicr10, r10, #255
adr r5, restart
bicr5, r5, #31
sub r9, r6, r5@ size to copy
add r9, r9, #31@ rounded up to a multiple
bicr9, r9, #31@ … of 32 bytes
add r6, r9, r5
add r9, r9, r10
1:ldmdbr6!, {r0 – r3, r10 – r12, lr}
cmpr6, r5
stmdbr9!, {r0 – r3, r10 – r12, lr}
bhi 1b
这段代码便是完结代码的自搬移,最开端两句是获得所要搬移代码的巨细,进行了256字节的对齐,注释上说了,为了防止偏移很小时发生自我掩盖(这个当地暂没有想了解,不过不影响下面剖析)。这儿仍是再画个图表明一下整个搬移进程吧,以zImage加载地下和zreladdr都为0x28为例,其他的相似。
图.7 zImage的代码自搬移和内核解压的全程图解
图.7中我现已标好了序号,代码的自搬移和内核解的整个进程都在这儿边下面一步步来分化:
①.首要核算要搬移的代码的.text段代码的巨细,从restart开端,到reloc_code_end完毕,这个便是剩余的.text段的内容,这段内容是接在翻开cache的函数之后的。然后把这段代码搬到核实践解压后256字节对齐的鸿沟,然后进行搬移,搬移时一次转移32个字节,故存有搬移巨细的r9寄存器进行了一下32字节对齐的扩展。
②.搬移完结后,会保存一下新旧代码间的offset值,存于r6中。再从头设置一下新的仓库的地址,方位如图所示,代码如下:
subr6, r9, r6
#ifndef CONFIG_ZBOOT_ROM
addsp, sp, r6
#endif
③.然后进行cache的flush,由于立刻要进行代码的跳转了,接着就核算新的restart在哪里,接着越过去履行新的重定位后的代码。
blcache_clean_flush
adrr0, BSYM(restart)
addr0, r0, r6
mov pc, r0
这个时分就又会到restart处履行,会把前面的代码再履行一次,不过这次在履行时,会进入图.6所示的代码不必重定位的状况,预料之后的事,接着跳到wont_overwirte履行,如下:
teqr0, #0
beqnot_relocated
这两行代码的意思是,看一下只什么时分越过来的,假如r0的值为0,阐明没有进行代码的重定位,那这个时分跳到no_relocated处履行,这段就会越过.got符号表的搬移,由于方位没有变啊。代码写得好谨慎啊,敬服。
④.咱们这种通过代码重定位的状况下,r0的值必定不会零,那么这个时分就要进行.got表的重搬移,如图中所示,代码如下:
1:ldrr1, [r11, #0]@ relocate entries in the GOT
add r1, r1, r0@ table.This fixes up the
strr1, [r11], #4@ C references.
cmpr11, r12
blo 1b
⑤.下面就来初始化咱们一向没有进行初始化的.bss段,其实便是清零,方位如图所示。我虽画了一个箭头,可是其实并没有进行任何搬移动作,只是清零,代码如下:
not_relocated:movr0, #0
1:strr0, [r2], #4@ clear bss
strr0, [r2], #4
strr0, [r2], #4
strr0, [r2], #4
cmpr2, r3
blo 1b
这儿看到咱们心爱的not_relocated标号了吧,这个标号便是前面所见到的假如没有进行重定位,就直接越过来进行bss的初始化。
⑥.设置好64K的解压缓冲区在仓库之后,代码如下:
mov r0, r4
mov r1, sp@ malloc space above stack
addr2, sp, #0x10@ 64k max
mov r3, r7
⑦.进行内核的解压进程
bldecompress_kernel
arch/arm/boot/compressed/misc.c
voiddecompress_kernel(unsigned longoutput_start, unsigned longfree_mem_ptr_p,
unsigned longfree_mem_ptr_end_p, intarch_id)
这个函数是C下面的函数,那些仓库的设置啊,.got表啊,64k的解压缓冲啊,都是为它预备的。榜首个参数是内核解压后所寄存的地址,第二,第三参数是64k解压缓冲开端地址和完毕地址,终究一个参数ID号,这个由u-boot传入。
⑧.这是终究一步了,总算到终究一步了。代码如下:
blcache_clean_flush
blcache_off
mov r0, #0@ must be zero
mov r1, r7@ restore architecture number
mov r2, r8@ restore atags pointer
mov pc, r4@ call kernel
这儿先进行cache的flush,然后关掉cache,再预备好linux内核要发动的几个参数,终究跳到zreladdr处,进入解压后的内核,到这儿紧缩内核的任务就完结了。可是它的劳绩可不小啊。下面便是真真正正的linux内核的发动进程了,这儿会进入到arch/arm/kernel/head.s这个文件的stext这个地址开端履行榜首行代码。