摘要:针对高压断路器毛病样本难以获取等问题,在研讨了其机械特性的基础上,本文提出了一种依据实数阴性挑选法(RNS)和支撑向量机(SVM)的两级分类器确诊办法。树立分类器的数学模型。经过实数阴性挑选算法发生检测器,进行榜首次分类,对不属于检测器的数据导入二次分类器,进行二级分类。实验标明,依据实数阴性算法和支撑向量机算法相结合的断路器毛病确诊算法,对断路器的多种毛病都可以有效地分类,提高了断路器毛病确诊的准确率和速度。
高压断路器是电力体系的重要设备之一,是电网运转中正常情况下切换电路和毛病情况下断开电路的首要设备,在电网中能起到维护和操控作用。其运转情况的安全与否直接关系到整个电力体系的安全性。因而,随时检测断路器情况,及早发现并扫除或许存在的毛病,是确保供电体系可靠性的重要手法之一。
近年来,呈现了许多新的毛病确诊办法,如神经网络、毛病树、支撑向量机、灰色理论、专家体系、遗传算法等。在断路器毛病确诊方面,这些办法存在部分缺点,例如神经网络会呈现部分极小值、敛速度慢、欠学习与过学习以及练习网络时需求很多样本等缺乏。所以依据以上办法交融的智能确诊办法可发挥各自优势,战胜各自的缺点。针对高压断路器毛病样本难以获取的问题,文中在研讨了以上种办法的基础上,提出了依据实数阴性挑选法和支撑向量机的复合确诊办法。
1 实数阴性挑选法
阴性挑选法(RNS)是人工免疫体系的算法中的一种算法,免疫体系是人类和脊椎动物体必备的防护体系,人工免疫体系,是依据是依据免疫体系机制和理论免疫学而开展的各种人工典范的总称,其首要进程是抽取免疫机制、规划免疫模型或算法、实验验证或核算机仿真(处理问题)。
阴性挑选法是Forrest的研讨小组在于免疫体系的专家协作研讨中初次提出的,算法仿照了免疫细胞的老练进程,构成检测器仿照老练的免疫细胞。首要的进程分为两个阶段:耐受和检测。耐受阶段首要经过现有样本发生老练的检测器,树立非己;检测阶段,检测器对不知道的采样样本进行检测,以发现改变。经过随机发生检测器,并删去那些能检测出自己的检测器,以便生成的检测器集有更好的空间掩盖率能,更好的检测出非己。
实数阴性挑选法的组成包含数据空间表明、检测器的表明、匹配规矩、检测器发生\铲除机制,其间最重要的检测器的生成。
实数阴性挑选算法可以论述为:把自己/非已空间作为Rn的一个子集,归一化到空间[0,1]n。检测器由一个n维向量和一个实数构成,用n维向量表明检测器中心,实数表明列应的半径。因而,检测器可以看作Rn空间内的一个超球。匹配规矩由检测器与自己间的欧氏(Euclidean)间隔和检测半径组成。将已知样本S(表明为n维向量的点)作为算法的输入,经过算法发生检测器D让它掩盖非己空间。检测器具有只与非己空间匹配、不与自己空间匹配的特性。向量检测器具有与自己向量相同的维数,但其散布在非己空间内,向量检测器D需满意以下不等式:
E(D,S)>r (1)
其间,E(·)为D与S的欧氏间隔,S为自己空间的恣意样本向量,r为阈值。
2 支撑向量机
支撑向量机是一种监督式学习办法,是Cortes和Vapnik于1995年提出的,他在处理小样本,非线性,高维形式识别中表现出许多特有的优势,并可以推行应用到函数拟合和其他机器学习问题中。
支撑向量机是树立在核算学习理论和结构危险最小原理基础上的,依据有限的样本信息在模型的复杂性学和学习才能之间寻求最佳折衷,以期取得最好的泛华才能。
支撑向量机首要针对样本的二分类问题,在样本数量小、非线性的情况下,可以很好的样本分类的作用,因为支撑向量机对样本的依靠程度较低,比较神经网络,能更好的反响现场的情况,支撑向量机首要是构建一个超平面。

依据以上公式,求出支撑向量,阈值b,并求出最优分类超平面。
3 断路器毛病确诊实验
断路器的机械特性首要经过分合闸信号来表现,DSP收集传感器的信号,经过小波去噪和小波重构等办法获取分合闸信号的要害参数:I1,I2,I3,t1,t2,t3,t4,t5。如图1所示:其间t0~t1为铁芯的发动时刻,t1时刻铁芯开端运动,t1~t2铁芯运动,t2时刻铁芯碰到机械负载,到达电流谷底。t2~t3铁芯中止运动,t3~t4为上一阶段的连续,t4~t5为电流开断阶段,此刻辅佐开关分断,在辅佐开关处发生电弧,迫使电压升高,电流快速下降。I1,I2,I3,别离反映了电源电压、线圈电阻,电磁铁芯运动速度。
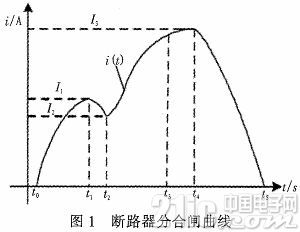
当分合闸信号呈现异常时,表明断路器或许呈现了毛病。常见的毛病有:电源过低(GD)、合闸铁心有卡涩(HKS)、操作组织有卡涩(CKS)、合闸铁芯空行程太大(TD)、辅佐开关接触不良(FK)。
3.1 确诊模型树立
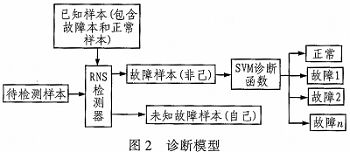
模型的树立有两种形式,榜首种为:经过已知样本获取检测器,将已知的多类毛病样本、已知正常样本、检测器作为支撑向量机的输入,树立支撑向量机模型。为了完结对不知道毛病有较高的掩盖率,检测器的个数在实验中到达1 000个,导致在生成支撑向量机模型和不知道样本做测验时会花费很多的时刻,不利于毛病的快速确诊。第二种为:榜首阶段,将不知道样本代入检测器,判别是自己还对错己,假如对错己,则代入有已知样本构建的支撑向量机模型。经过实验证明,这样会大大加速确诊的速度,而且可以确保确诊的精度。
如图2所示,首要经过已知样本,其间包含正常样本和毛病样本,树立实数阴性挑选法的仿照,得到检测器。将待检测的样本代入一级分类确诊模型,核算其亲和力,判别是否为自己,假如对错己则将其代入二级分类确诊模型,对毛病进行详细分类。
3.2 一级分类模型树立
1)检测器老练阶段。如图3所示:输入参数,S-自体样本,Nmax-最大检测器数,rs-自体半径,rd-检测半径。将自体样本用公式归一化到n维空间[0,1]n
![]()
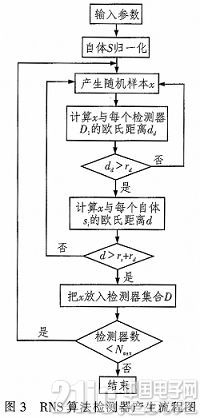
其间,S(i)为自体样本S矩阵的第i列,min[S(i)]为S(i)中所有元素的最小元素,max[S(i)]为S(i)中所有元素的最大元素,B’=[1,1,…,1]1×n,n为样本的维数,s(i)为归一化后的自体样本s矩阵的第i列。再从[0,1]n空间中随机发生样本x,核算x与检测器调集D中的每个检测器Di的欧氏间隔dd和x与每个自体样本si的欧氏间隔d。Di,Si和x别离为n维向量,是空间[0,1]n中的一个点。

终究,满意条件dd>rd且d>rs+rd的x为非己,将其放入检测器调集D中直到检测器个数满意要求。条件dd>rd用来确保x与检测器调集D中已有的每个检测器的欧氏间隔大于rd,
避免检测器过度集合,使其更均匀的掩盖非己空间;条件d>rs+rd用来确保检测器落在非己空间。
依据上述所述,断路器归一化后的部分毛病参数如表1所示,经过随机发生检测器,设定rs=O.05、rd=0.1,依照上述的规矩生成检测器,部分检测器如表2所示。
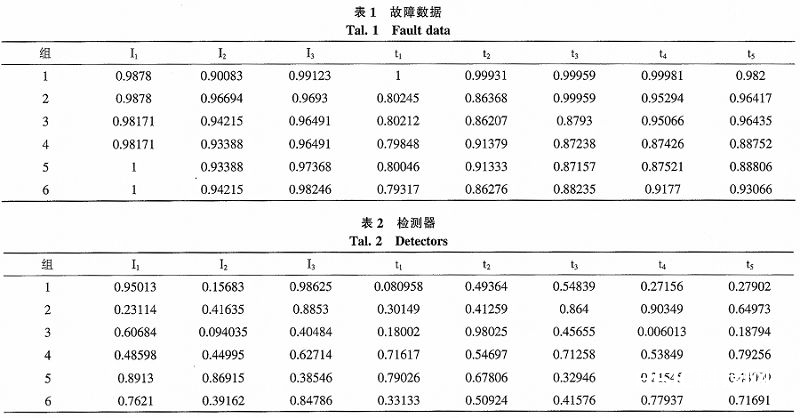
2)确诊阶段。将不知道样本带入练习好的检测器,判别自己还对错己,假如对错己,将数据导入二级毛病分类模型,完结体系的毛病确诊使命。
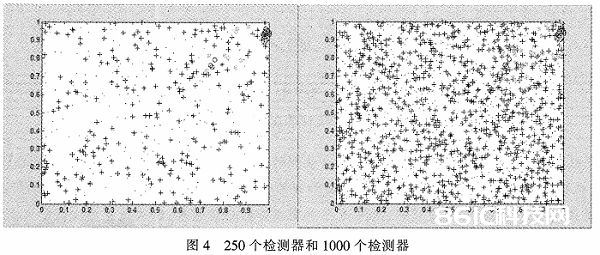
取样本和检测器前二维作图,查验成果如图4所示,左面图为250个检测器,右边图为1 000个检测器,图中“+”为检测器,“o”为已知样本,“*’为待检测样本。从图中可以看出当检测器到达1 000个的时分,检测器基本上掩盖了整个区域。经过实验证明,1 000个检测器与250个检测器比较,毛病确诊的正确率提高了23%,全体正确率到达了92%,而且在确诊时刻上没有增到多少,契合毛病确诊的要求。
3.3 二级分类模型树立
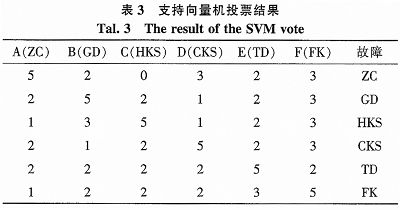
已知样本中有正常样本和详细的毛病样本,将正常样本和毛病样本(5类)作为支撑向量机的输入。支撑向量机是用来处理二分类问题的,在处理多分类问题的时分,需求加以改善,这儿咱们选用1对1的练习办法(OVO),将练习样本分红A、B、C、D、E、F六类,树立15个SVM,求解出15个判别函数组成的确诊模型。将不契合检测器的数据作为确诊模型的输入,取得每个判别函数的判别输出,选用投票的办法,确认终究的确诊成果。
如表3所示,将6组不契合检测器的数据带入确诊模型可以很快的得出详细的毛病类型,得出的成果与实在毛病类型比较,正确率为100%,确诊模型在速率和准确度方面都有很大的改善。
4 定论
针对断路器毛病数据难以获取的问题,在深入研讨了实数阴性挑选法和支撑向量机的机理后,本文树立了依据实数阴性挑选法和支撑向量机的二级分类器模型。将已知样本作为检测器的输入,发生检测器集。将检测集和已知样本树立榜首级分类器,经过此算法可以很好的掩盖非己空间。使用已知样本树立二级分类器,用来详细区别毛病类型。在毛病样本难以获取的情况下,两种算法的结合,大大发挥了其各自的优势,提高了断路器毛病确诊的准确率和速度。