跟着微电子和嵌入式技能的蓬勃开展,依据高性能ARM理器的嵌入式工控机渠道,以其体积小、可靠性高、本钱低一级长处,克服了传统工控机体积巨大、故障率高以及难以较长时刻习惯于工业操控恶劣环境等缺陷,广泛使用于工业操控范畴。英创公司的嵌入式主板正是习惯这样的开展趋势,敏捷生长为嵌入式主板的首要供货商之一。
嵌入式操作体系是嵌入式工控机体系的核心技能之一。WinCE(Windows CE)体系是Windows宗族中的成员,专门为嵌入式规划的微内核操作体系。这样的操作体系可使便携式技能与现有的Windows桌面技能整合作业。它是一个抢先式多任务、多线程的并具有强壮通讯才能的32位嵌入式操作体系。
WinCE是实时性较强的嵌入式操作体系,与另一个实时性较好的操作体系——Linux比较,WinCE以更友爱的图形界面、开发门槛低一级长处,在操控、通讯、多媒体等范畴得到广泛的使用;一起,有Microsoft公司强壮的技能开发支撑做后台,更有利于开发危险的化解,而Linux的开发更多的是依赖于程序员个人的经历,然后进步了研制的门槛。
在嵌入式宗族中,选用32位RISC架构的ARM微处理器以其体积小、功耗低、本钱低、高性能等长处敏捷占据了大部分商场。跟着国内嵌入式使用范畴的开展,ARM芯片必然会取得更广泛的注重和使用。跟着ARM 芯片在通讯、多媒体等数据处理速度要求高的范畴的广泛使用,对浮点运算的要求越来越高,高端的ARM芯片为了满意这种要求,嵌入了数学协处理器。Cirrus Logic公司的EP9315便是这样的芯片,其内部嵌入了Maverick Crunch数学协处理器,完结了硬件浮点运算,处理了浮点运算速度问题。但是惋惜的是,在WinCE渠道国内大多数公司只把此款高性能芯片作为一般的ARM9来用,没有发挥其超强的核算才能。这样,那些对实时核算要求严厉的客户不得不选用ARM+DSP架构,这样,不光进步了硬件本钱,也进步了产品研制难度,英创公司的EM9000嵌入式主板处理了浮点运算速度问题,其选用WinCE渠道,降低了开发难度。
EM9000嵌入式主板是英创承继了英创公司长时间服务于工控范畴所构成的技能特征及产品风格,选用高端的ARM9芯片EP9315,其明显的特点是内部集成Maverick Crunch数学协处理器,因为它选用硬件完结浮点运算,所以能明显进步ARM的浮点运算和数字信号处理才能。英创为了满意对浮点运算速度要求严厉的客户,代替ARM+DSP架构嵌入式主板,通过不断的尽力,使数学协处理器成功运转在WinCE渠道,为即需求WinCE体系又需求高速的信号处理的客户供给了新的高性价比的挑选。为了合作EM9000客户在EVC或许VS开发渠道上运用Maverick Crunch数学协处理器进行浮点运算和数字信号处理,特供给下列数学运算函数。
下列函数通过在EM9000渠道EVC开发环境下实践测验,在EM9000嵌入式主板上实践运转,下列函数的运转速度有3—5倍的进步。其间,数组乘加函数em_arraymultadd进步速度近9倍。需求着重的是,只要需求处理的数据是浮点型时,速度才会有进步。当数据是整形时,无须调用下列函数。
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 功用描绘:核算浮点型变量source1与source2的和
// 输入参数:float source1,float source2
// 回来值:source1与source2的和
///////////////////////////////////////////////////////////////////////////////////////////////////////////
float em_add(float source1,float source2);
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 功用描绘:核算浮点型变量source1与source2的差
// 输入参数:float source1,float source2
// 回来值: source1与source2的差
///////////////////////////////////////////////////////////////////////////////////////////////////////////
float em_sub(float source1,float source2);
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 功用描绘:核算浮点型变量source1与source2的乘积
// 输入参数:float source1,float source2
// 回来值: source1与source2的乘积
///////////////////////////////////////////////////////////////////////////////////////////////////////////
float em_mult(float source1,float source2);
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 留意:在进行数组运算时,请保证数组source1、数组source2和数组result为长度为nlen的等长数组。假如不满意此条件,运算成果是不行预知的。
///////////////////////////////////////////////////////////////////////////////////////////////////////////
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 功用描绘:数组source1与数组source2对应相加,成果保存在数组result对应方位处。
// 即:
// 输入参数:数组source1的地址,数组source2的地址,nlen数组长度
// 输出参数:数组result的地址
///////////////////////////////////////////////////////////////////////////////////////////////////////////
void em_arrayadd(float *source1, float *source2,float *result,int nlen);
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 功用描绘:数组source1与数组source2对应相减,成果保存在数组result对应方位处。
// 即:
// 输入参数:数组source1的地址,数组source2的地址,nlen数组长度
// 输出参数:数组result
///////////////////////////////////////////////////////////////////////////////////////////////////////////
void em_arraysub(float *source1, float *source2, float *result, int nlen);
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 功用描绘:数组source1与数组source2对应相乘,成果保存在数组result对应方位处。
// 即:
// 输入参数:数组source1的地址,数组source2的地址,nlen数组长度
// 输出参数:数组result
///////////////////////////////////////////////////////////////////////////////////////////////////////////
void em_arraymult(float *source1,float *source2,float *result,int nLen);
///////////////////////////////////////////////////////////////////////////////////////////////////////////
// 功用描绘:数组source1与数组source2对应相乘并相加的和。
// 即:
// 输入参数:数组source1的地址,数组source2的地址,nlen数组长度
// 回来值 :回来 数组source1与数组source2对应相乘并相加的和。
///////////////////////////////////////////////////////////////////////////////////////////////////////////
float em_arraymultadd(float *source1,float *source2, int nlen);
使用办法:
1、把em9000_crunch.lib和crunch.h文件拷贝到EVC或许VS工程目录下,并在程序中包括crunch.h头文件。
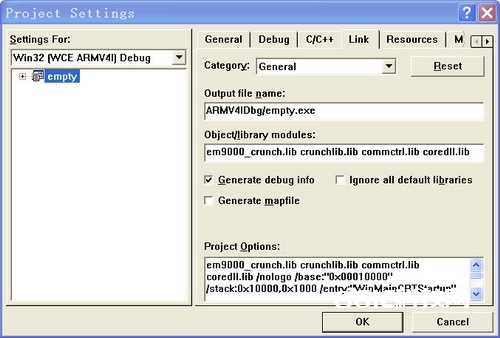
2、挑选 project—>setting呈现下图所示窗口,把em9000_crunch.lib添加到如下图所示的方位。在程序中调用以上函数就能够了。
测验办法:
1、树立依据EM9000嵌入式主板开发环境,使开发板能够与EVC联合调试。具体步骤请参看英创公司供给的开发光盘。
2、树立依据EM9000的EVC项目工程。把下列测验代码添加到主函数中:
iStartTime = GetTickCount(); // 运算计时开端
for(n=0;n1000;n++)
arraymultaddresult=arraymultadd(arraya,arrayb,1024); // arraya,arrayb为长度1024的浮点型数组
iEndTime=GetTickCount(); // 函数运转完毕
time=iEndTime-iStartTime;
printf(‘the result of emulator arrayadd is %f arraymultadd elpses time is %d ms\n’,arraymultaddresult,time);
iSartTime = GetTickCount();
for(n=0;n1000;n++)
multaddresult=em_arraymultadd(arraya,arrayb,1024);
iEndTime=GetTickCount();
time=iEndTime-iStartTime;
printf(‘the result of em_arraymultadd is %f em_arraymultadd elpse time is %d ms\n’,multaddresult,time);
以上程序,在EM9000嵌入式主板上运转的成果为:
arraymultadd elpses time is 919ms
em_arraymultadd elpses time is 104 ms
由以上的成果能够看出:用英创公司供给的函数,能够明显进步浮点运算速度。
现在英创公司供给的函数首要完结根本的浮点处理,咱们将依据客户的需求,不断的完善浮点库的功用,如FIR滤波等。一起客户若需求专用的处理算法,也可与咱们联络有关完结专用浮点处理功用的事宜。