Linux 网络文件体系简介
网络文件体系(NFS)协议是由 Sun MicroSystem 公司在 20 世纪 80 时代为了供给对同享文件的长途拜访而规划和完结的,它选用了经典的客户机/服务器形式供给服务。为了到达好像 NFS 协议经过运用 Sun 公司开发的远在本机上运用本地文件体系相同快捷的作用,NFS 经过运用长途进程调用协议(RPC Protocol)来完结运转在一台核算机上的程序来调用在另一台长途机器上运转的子程序。一起,为了处理不同平台上的数据交互问题,它供给了外部数据表明(XDR)来处理这个问题。为了灵敏地供给文件同享服务,该协议能够在 TCP 协议或者是 UDP 协议上运转,典型的状况是在 UDP 协议上运转。在此基础上,NFS 在数据的传送进程中需求 RPC 指令得到承认,而且在需求的时分会要重传,这样既能够经过 UDP 协议取得较高的通讯功率,也能经过 RPC 来取得较高的通讯可靠性。
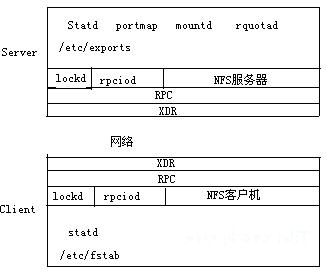
因为 NFS 依据 C/S 形式供给服务,所以它的中心组件首要包含客户机和服务器两部分。图 1 详细说明晰 NFS 的首要组件以及首要的配置文件。在服务器端,portmap、mountd、nfsd 三个监控程序将在后台运转。portmap 监控程序用来注册依据 RPC 的服务。当一个 RPC 的监控程序发动的时分,它告知 portmap 监控程序它在哪一个端口进行侦听,而且它在进行什么样的 RPC 服务。当一个客户机向服务器提出一个 RPC 恳求,那么它就会和 portmap 监控程序取得联系以确认 RPC 音讯应该发往的端口号。而 Mountd 监控程序的功用是来读取服务器端的/etc/exportfs 文件而且创立一个将服务器的本地文件体系导出的主机和网络列表,因而客户机的挂接(mount)恳求都被定位到 mountd 监控程序(daemon)。当验证了服务器的确具有挂接所恳求的文件体系的权限今后,mountd 为恳求的挂接点回来一个文件句柄。而 nfsd 监控程序则被服务器用来处理客户机端发送过来的恳求。因为服务器需求一起处理多个客户机的恳求,所以在缺省状况下,操作体系将会主动发动八个 nfsd 线程。当然,假如 NFS 服务器特别忙的时分,体系有或许依据实践状况发动更多的线程。
图 1 网络文件体系简图
NFS 的客户机与服务器之间经过 RPC 进行通讯,通讯进程如下所示:
用户将 NFS 服务器的同享目录挂载到本地文件体系中。
客户拜访 NFS 目录中的文件时,NFS 客户端向 NFS 服务器端发送 RPC 恳求。
NFS 服务端接纳客户端发来的 RPC 恳求,并将这个恳求传递给本地文件拜访程序,然后拜访服务器主机上的一个本地的磁盘文件。NFS 服务器能够一起接纳多个 NFS 客户端的恳求,并对其进行并发操控。
NFS 客户端向服务器主机宣布一个 RPC 调用,然后等候服务器的应对。NFS 客户端收到服务器的应对后,把成果信息展示给用户或应用程序。
NFS 下的数据备份、康复的首要功用
对数据进行备份与康复是确保数据安全和事务连续性的十分老练的做法。在 Linux 下的本地文件体系(例如 Ext2、Ext3 等)中,数据备份和康复一般选用惯例的办法来进行操作,例如运用 Tar、Archive 等。而关于 NFS 来说,其数据备份需求选用量身定制的办法来进行。
为了确保数据在灾祸环境中的可用性和事务连续性,针对它的数据备份、康复计划应具有如下重要功用:
经过对体系重要数据的快速备份,实在确保体系数据的安全;
能够依据指令完结备份体系的实时切入,确保服务不被中止,坚持体系继续运转的才能;
经过实时记载一切文件的操作日志,体系管理员能够在产生灾祸的状况下对日志进行剖析和取证,然后发现入侵者的蛛丝马迹。
NFS 多版别备份技能
为了确保服务器呈现毛病后能敏捷康复,要求体系数据能快速康复到一个最近的正确状况,一切这些都需求多版别技能的支撑,经过同步记载文件的在某些时间的状况,在整个体系范围内建立起类似于数据库体系的”检查点”,以确保上述方针的完结。
关于多版别体系而言,需求较好地处理两个方面的问题:功能和空间使用率。关于前者,最首要的是确保在生成版别的时分能够快速完结,一起康复时也具有较好的功能。此外,体系引进多版别构成的全体开支也应该比较抱负。关于第二点,首要考虑是节省磁盘空间,尽管跟着硬件技能的不断发展,磁盘空间越来越大,性价比也越来越高,可是当版别较多而且文件数量较多、较大时,引进多版别添加的开支也或许相当可观,一起,较大的空间也意味着版别生成时或许需求更多的写操作,这样也必将影响整体功能。
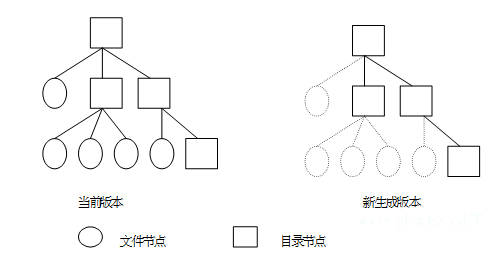
为了确保引进多版别特性后文件体系仍具有较好的功能,以及确保较高的空间使用率,咱们开发了一种高效的慵懒版别生成算法。首要思维是:生成版别时不进行文件的仿制,仅仿制目录结构,在新版别生成后到下一版别生成前,假如有文件需求修正,则第一次修正时对该文件进行仿制,然后确保该文件状况与对应的版别坚持一致。
在一般状况下,目录结构的数据量远远小于文件的数据量,因而这种办法能够大大下降版别生成时需求仿制的数据量,因而具有较高的功能。一起,这种把单个文件版别生成的实践操作推后到非做不行的时分,而且恣意文件在两次版别之间最多生成一次版别,因而这种慵懒战略能够使需求实践生成版别的文件数量到达最少,一起还能够把多个文件版别生成操作涣散到详细的文件操作中,然后避免了会集的一次性版别生成办法或许构成的服务暂时中止的问题。
版别生成后的结构如图 2 所示。
图 2 多版别生成示意图
详细算法包含两个部分,即版别生成算法和文件第一次修正处理算法,版别生成算法首要完结版别生成作业,首要进程如下:
找到需求构成版别的最高层目录作为原目录;
使用文件体系供给的函数,生成新的目录节点,称为新目录;