核算机开展到今日,现已大大改变了咱们的日子,咱们现已进入了智能化的年代。但要是想完结影视作品中那样充沛互动的人工智能与人机互动体系,就不得不说到深度学习。
深度学习
深度学习的概念源于人工神经网络的研讨。含多隐层的多层感知器便是一种深度学习结构。深度学习经过组合低层特征构成愈加笼统的高层表明特色类别或特征,以发现数据的分布式特征表明。
深度学习的概念由Hinton等人于2006年提出。依据深信度网(DBN)提出非监督贪心逐层练习算法,为处理深层结构相关的优化难题带来期望,随后提出多层主动编码器深层结构。此外Lecun等人提出的卷积神经网络是第一个真实多层结构学习算法,它运用空间相对联系削减参数数目以前进练习功能。
深度学习是机器学习研讨中的一个新的范畴,其动机在于树立、仿照人脑进行剖析学习的神经网络,它仿照人脑的机制来解说数据,例如图画,声响和文本。
同机器学习办法相同,深度机器学习办法也有监督学习与无监督学习之分.不同的学习结构下树立的学习模型很是不同.
例如,卷积神经网络(Convolutional neural networks,简称CNNs)便是一种深度的监督学习下的机器学习模型,而深度相信网(Deep Belief Nets,简称DBNs)便是一种无监督学习下的机器学习模型。
Artificial Intelligence,也便是人工智能,就像长生不老和星际周游相同,是人类最夸姣的愿望之一。虽然核算机技能现已取得了长足的前进,可是到现在为止,还没有一台电脑能发生“自我”的认识。是的,在人类和很多现成数据的协助下,电脑能够表现的十分强壮,可是离开了这两者,它乃至都不能分辩一个喵星人和一个汪星人。
图灵(图灵,咱们都知道吧。核算机和人工智能的开山祖师,别离对应于其闻名的“图灵机”和“图灵测验”)在 1950 年的论文里,提出图灵实验的想象,即,隔墙对话,你将不知道与你说话的,是人仍是电脑。这无疑给核算机,尤其是人工智能,预设了一个很高的期望值。可是半个世纪曩昔了,人工智能的开展,远远没有到达图灵实验的规范。这不只让多年翘首以待的人们,灰心丧气,以为人工智能是忽悠,相关范畴是“伪科学”。
可是自 2006 年以来,机器学习范畴,取得了突破性的开展。图灵实验,至少不是那么可望而不可及了。至于技能手段,不只仅依靠于云核算对大数据的并行处理才干,并且依靠于算法。这个算法便是,Deep Learning。凭借于 Deep Learning 算法,人类总算找到了怎么处理“笼统概念”这个亘古难题的办法。

2012年6月,《纽约时报》披露了Google Brain项目,招引了大众的广泛重视。这个项目是由闻名的斯坦福大学的机器学习教授Andrew Ng和在大规划核算机体系方面的国际顶尖专家JeffDean一同主导,用16000个CPU Core的并行核算渠道练习一种称为“深度神经网络”(DNN,Deep Neural Networks)的机器学习模型(内部共有10亿个节点。这一网络自然是不能跟人类的神经网络混为一谈的。要知道,人脑中可是有150多亿个神经元,相互衔接的节点也便是突触数更是如银河沙数。从前有人估算过,假如将一个人的大脑中一切神经细胞的轴突和树突顺次衔接起来,并拉成一根直线,可从地球连到月亮,再从月亮回来地球),在语音辨认和图画辨认等范畴取得了巨大的成功。
项目负责人之一Andrew称:“咱们没有像一般做的那样自己框定鸿沟,而是直接把海量数据投放到算法中,让数据自己说话,体系会主动从数据中学习。”别的一名负责人Jeff则说:“咱们在练习的时分历来不会告知机器说:‘这是一只猫。’体系其实是自己创造或许领会了“猫”的概念。”

2012年11月,微软在我国天津的一次活动上揭露演示了一个全主动的同声传译体系,讲演者用英文讲演,后台的核算机趁热打铁主动完结语音辨认、英中机器翻译和中文语音组成,效果十分流通。据报道,后边支撑的关键技能也是DNN,或许深度学习(DL,DeepLearning)。
用什么加快核算速度?异构处理器
在摩尔定律的效果下,单核标量处理器的功能持续进步,软件开发人员只需求写好软件,而功能就等候下次硬件的更新,在2003年之前的几十年里,这种“免费午饭”的形式一直在持续。2003年后,首要由于功耗的原因,这种“免费的午饭”现已不复存在。为了生计,各硬件生产商不得不选用各种办法以前进硬件的核算才干,以下是现在最盛行的几种办法是。
1) 让处理器一个周期处理多条指令 ,这多条指令可相同可不同。如Intel Haswell处理器一个周期可履行4条整数加法指令、2条浮点乘加指令,一同访存和运算指令也可一同履行。
2) 运用向量指令 ,首要是SIMD和VLIW技能。SIMD技能将处理器一次能够处理的数据位数从字长扩大到128或256位,也就进步了核算才干。
3) 在同一个芯片中集成多个处理单元 ,依据集成办法的不同,分为多核处理器或多路处理器。多核处理器是如此的重要,以至于现在即使是手机上的嵌入式ARM处理器都现已是四核或八核。
4) 运用异构处理器,不同的架构规划的处理器具有不同的特色,如X86 处理器为推迟优化,以削减指令的履行推迟为首要规划考量(当然今日的X86 处理器规划中也有许多为吞吐量规划的影子);如NVIDIA GPU和AMD GPU则为吞吐量规划,以前进整个硬件的吞吐量为首要规划方针。
GPU加快
比较之前在游戏、视觉效果中的运用,GPU正在成为数据中心、超算中心的标配,并广泛运用于深度学习、大数据、石油化工、传媒文娱、科学研讨等职业。GPU核算正在加快着深度学习革新,作为深度学习研讨技能渠道领导厂商,NVIDIA将为我国的深度学习供给更多的技能渠道和处理方案,并持续与我国的合作伙伴一同积极参加和推进深度学习生态链的构建。
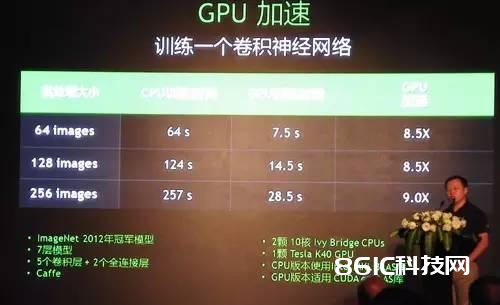
依据GPU加快的深度学习算法,百度、微柔和Google的核算机视觉体系在ImageNet图画分类和辨认测验中别离到达了5.98% (2015年1月数据)4.94%(2015年2月数据)、4.8%(2015年2月数据)、的错误率,挨近或超过了人类辨认水平——跑分比赛虽然有针对已知数据集进行特定优化之嫌,但优化成果对工业界的实践依然具有参考价值。
人工智能从曩昔依据模型的办法,变成现在依据数据、依据核算的办法,首要得益于GPU高度并行的结构、高效快速的衔接才干。事实证明GPU很合适深度学习。
简直一切深度学习的研讨者都在运用GPU
了解深度学习的人都知道,深度学习是需求练习的,所谓的练习便是在不计其数个变量中寻觅最佳值的核算。这需求经过不断的测验完结收敛,而终究取得的数值并非是人工确认的数字,而是一种常态的公式。经过这种像素级的学习,不断总结规则,核算机就能够完结像像人相同考虑。现在,简直一切的深度学习(机器学习)研讨者都在运用GPU进行相关的研讨。当然,我说的是“简直”。除了GPU之外,包含M%&&&&&%和FPGA也供给了不同的处理方案。NVIDIA怎么看待不同的硬件架构对深度学习的影响,又是怎么点评这些技能的呢?
NVIDIA我国区处理方案架构工程总监罗华平以为:“技能开展和科技的开展,是需求不同的技能一同来参加。不管是GPU也好、FPGA也好或许是专用的神经网芯片也好,它的首要目的都是推进深度学习(机器学习)这个方向的技能开展。那么咱们在初期,的确能够测验不同的技能,来讨论哪种技能能够更好的合适这项运用。从现在来看,深度学习很多的运用,首要会集在练习方面。那么在这个范畴,GPU的确是十分合适的,这也表现在一切的这些工业界的大佬如BAT、谷歌,Facebook等等,都在运用GPU在做练习。”而除了练习之外,在实践的运用方面,NVIDIA也正在结合我国区域IDC机房遍及具有的功耗、网络等特色,“考虑是否规划低功耗的GPU,来满意用户的需求”。
除了硬件方面的要素之外,英伟达我国区技能司理赖豪杰也从软件方面回答了GPU关于深度学习运用的价值。首要从深度学习运用的开发东西视点,具有CUDA支撑的GPU为用户学习Caffe、Theano等研讨东西供给了很好的入门渠道。其实GPU不只仅是指专心于HPC范畴的Tesla,包含Geforce在内的GPU都能够支撑CUDA核算,这也为初学者供给了相对更低的运用门槛。除此之外,CUDA在算法和程序规划上比较其他运用愈加简单,经过NVIDIA多年的推行也积累了广泛的用户群,开发难度更小。最终则是布置环节,GPU经过PCI-e接口能够直接布置在服务器中,便利而快速。得益于硬件支撑与软件编程、规划方面的优势,GPU才成为了现在运用最广泛的渠道。
深度学习开展遇到瓶颈了吗?
咱们之所以运用GPU加快深度学习,是由于深度学习所要核算的数据量反常巨大,用传统的核算办法需求绵长的时刻。可是,假如未来深度学习的数据量有所下降,或许说咱们不能供给给深度学习研讨所需求的满足数据量,是否就意味着深度学习也将进入“隆冬”呢?对此,赖豪杰也提出了别的一种观点。“做深度神经网络练习需求很多模型,然后才干完结数学上的收敛。深度学习要真实挨近成人的智力,它所需求的神经网络规划十分巨大,它所需求的数据量,会比咱们做言语辨认、图画处理要多得多。假设说,咱们发现咱们没有办法供给这样的数据,很有或许呈现隆冬”。
不过他也弥补以为——从今日看到的成果来说,其实深度学习现在还在蓬勃开展往上的阶段。比如说咱们现阶段首要做得比较老练的语音、图画方面,整个的数据量仍是在不断的增多的,网络规划也在不断的变杂乱。现在我没有办法猜测,将来是不是会有一天数据真不够用了。
关于NVIDIA来说,深度学习是GPU核算开展的大好时机,也是继HPC之后一个全新的事务增长点。正如Pandey所说到的那样,NVIDIA将国际各地的成功经验带到我国,包含国外的成功事例、与合作伙伴的杰出联系等等,协助我国客户的快速生长。“由于现在是互联网的年代,是没有跨界的年代,咱们都是平等一同的。”
GPU、FPGA 仍是专用芯片?
虽然深度学习和人工智能在宣传上炙手可热,但不管从仿生的视角抑或核算学的视点,深度学习的工业运用都仍是初阶,深度学习的理论基础也没有树立和完善,在一些从业人员看来,依托堆积核算力和数据集取得成果的办法显得过于暴力——要让机器更好地舆解人的目的,就需求更多的数据和更强的核算渠道,并且往往仍是有监督学习——当然,现阶段咱们还没有数据缺少的忧虑。未来是否在理论完善之后不再依靠数据、不再依靠于给数据打标签(无监督学习)、不再需求向核算力要功能和精度?
退一步说,即使核算力仍是必需的引擎,那么是否必定便是依据GPU?咱们知道,CPU和FPGA现已显示出深度学习负载上的才干,而IBM主导的SyNAPSE巨型神经网络芯片(类人脑芯片),在70毫瓦的功率上供给100万个“神经元”内核、2.56亿个“突触”内核以及4096个“神经突触”内核,乃至答应神经网络和机器学习负载逾越了冯·诺依曼架构,二者的能耗和功能,都足以成为GPU潜在的挑战者。例如,科大讯飞为打造“讯飞超脑”,除了GPU,还考虑凭借深度定制的人工神经网络专属芯片来打造更大规划的超算渠道集群。
不过,在二者没有产品化的今日,NVIDIA并不忧虑GPU会在深度学习范畴失宠。首要,NVIDIA以为,GPU作为底层渠道,起到的是加快的效果,协助深度学习的研制人员更快地练习出更大的模型,不会遭到深度学习模型完结办法的影响。其次,NVIDIA表明,用户能够依据需求挑选不同的渠道,但深度学习研制人员需求在算法、核算方面精雕细镂,都需求一个生态环境的支撑,GPU现已构建了CUDA、cuDNN及DIGITS等东西,支撑各种干流开源结构,供给友爱的界面和可视化的办法,并得到了合作伙伴的支撑,例如浪潮开发了一个支撑多GPU的Caffe,曙光也研制了依据PCI总线的多GPU的技能,对了解串行程序规划的开发者愈加友爱。比较之下,FPGA可编程芯片或许是人工神经网络专属芯片关于植入服务器以及编程环境、编程才干要求更高,还缺少通用的潜力,不合适遍及。