Patrick Madden在“多核处理器出路未卜(Multi-core processors face uncertain future)”一文中关于多核芯片的评论焦点集中于单个的通用处理器架构上,实践上这种观念对运用多处理器来处理体系架构问题作出了不用要的约束。正如 Madden所言,大型半导体和服务器处理器供货商能够供给多核的对称多处理器,每个对称多处理器都能够运转并行的多线程软件程序。这些多核处理器常在运转根据SAMD(single application multiple data)模型运用的大型服务器和笔记本电脑中。SAMD运用可回溯至前期的大型机年代,其时核算机专心于航班预订体系和实时银行体系等实时运用。
当时,嵌入式规划中对称多处理器(SMP)架构的运用引起了业界极大的重视。实践上,很少运用是一起并行(embarrassingly parallel)的。就像Madden提及,图画和多媒体处理是一起并行的,可是这些运用现已有专用的多媒体芯片处理了,例如IBM的Cell处理器和 ATI/Nvidia的图形处理器。因而,包括Madden在内的许多专家都以为,对称多处理器上的并行运用现已被约束在一个很小的规模之内。
软件工程师不习惯并行地考虑问题
在Madden的文章中,大多关于对称多处理器的评论都会谈到开发东西的问题。实践运用中,依托软件东西把一个巨大的单线程运用程序主动分配给多个处理器运转是不大或许的。类似于Verilog这样的硬件描绘言语能够很简单地表达并行操作,而像C这样的软件言语更适用于单线程算法的完结。为了让C言语更适用于并行编程,人们做了许多改善测验,比方Concurrent C、UPC、mpC、pC等。它们有些经过特别的库,有些经过并行的API来完结并行进程的显式标识和进程间的通讯,例如Madden的文章中说到的 MPI和OpenMP技能。
还有些研究人员试图用全新的整合了并行编程结构的软件开发言语来代替C言语。可是业界对这些新的编程言语并不认可(例如,Ada言语和Inmos公司的 Occam言语均以失利告终)。咱们现已习惯于单使命的算法描绘,对大多数程序员来说,考虑并行程序或多线程操作都适当困难。可是,跳出SMP的约束来扩展处理器架构,咱们发现至少有两种运用异构而非同构的并行办法。运用该两种快捷并行(convenient concurrency)办法能充分地将软件开发人员从并行作业的考虑中释放出来,由于不同的并行使命间的联络并非非常严密。
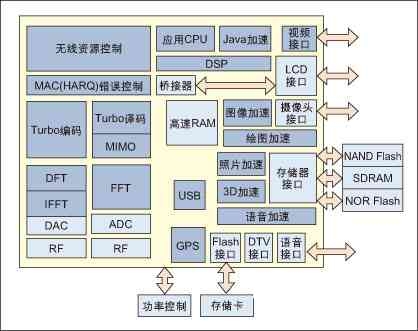
图1:超级3G移动电话原理图
第一种办法
你能够称这种并行为“组合并行”,由于这种并行操作将不同的子体系组合在一起,而每个子体系中都包括一个或多个针对特定使命优化过的处理器。在这种架构规划中,结构化的子体系间的通讯只在需求时才相互影响。图1所示的超级3G移动电话体系表现了该思维。图中共有18个独立的处理模块(灰色标明部分),每个模块都有明晰的功用界说,因而很简单将整个体系功用区分开来用18个处理器完结规划(考虑到子使命处理的话,或许需求更多处理器)。
一些人对这种架构规划提出批判,由于处理器和门电路的功率看上去并不是很高,至少在理论上只需用几个高时钟频率的通用处理器(或者是SMP多核处理器)就能够代替10个、20个或更多的处理器核。实践上这些批判并不恰当,摩尔定律持续促进在一片芯片上能够集成更多的晶体管,而Denard经典标准则供给速度更快、功耗更低的晶体管,可是从90nm开端,Denard理论无法持续供给更快的速度和更低的功耗了。在90nm节点上,功耗和能耗变得很难操控,并且跟着工艺的进步问题将更严峻。所以嵌入式体系的规划人员从现在开端就必须承受下降体系时钟频率以满意预期功耗和能耗目标的规划风格。
组合并行规划具有许多长处
* 将运算使命分配给几个片上处理器来运转是典型的添加晶体管数量交换低主频以下降功耗和能耗的办法。这是一种很好的工程折衷,由于时钟速度和内核作业电压之间的严密联系,时钟频率的进步将使功耗呈超线性增加。此外,较低时钟速度的处理器不用选用最新的制程工艺。相同光刻节点情况下,选用速度较慢的低功耗制程的静态漏电流水平比选用高性能制程的漏电流水平小三个数量级。
* 当不需用到某个专用子体系时,能够堵截其电源供给。因而,规划人员能够很简单地确认何时运用或不运用这些专用子体系。
* ASIP能够比通用处理器具有更高效的运用面积和功耗,而用作组合并行体系中的使命处理器。由于所运用的通用处理器核很少,也相应地减少了晶体管的数量。组合并行的规划防止了与SMP硬件规划和多线程代码相关联的子体系所需的杂乱交互与同步。一个四内核的SMP体系带有音频、视频和照相功用,在运转其他使命时仍不会吊销911紧迫电话,因而一般需求进行很多的仿真与剖析。而高层完结交互的独立子体系能很简单地进行独自和组合的验证操作。根据SystemC 的体系仿真东西现已能够方便地对组合并行的体系规划进行仿真。不同的子体系能够用C言语来描绘,并别离进行验证,然后运用指令集仿真器对整个体系进行仿真,这比进行RTL仿真快几百乃至上千倍。值得注意的是,C言语现已为嵌入式程序员广泛承受并选用,因而软件工程师无需学习新的言语。
第二种办法
核算一般能够区分为由独立使命引擎构成的流水线,因而快捷并行的第二种办法便是流水式数据流。各个流水式使命引擎都接纳、处理并输出数据块,一旦处理使命完结后,数据块就被送到下一级引擎。非对称多处理算法常常出现在信号处理和图画处理运用上,比如移动电话的基带处理、视频处理和静态图画处理等。流水线不光答应并行处理,并且还答应履行根据ASIP的运用,由于流水线中的每一个处理器都能高度集中于履行某一部分的使命。
上述两种快捷并行是互补的。因而,各个子体系的非对称多处理能和流水式规划的组合子体系进行交融。消费类、便携式和多媒体运用产品或许需求10到100个处理器,而这些处理器都将针对产品功用的特定使命进行优化。对根据非对称多处理器的运用进行编程要比根据对称多处理器的简单得多,由于不用考虑太多的交互使命依靠联系。经历标明经过这种办法能更明晰地编写软件,并且能够防止在同构多处理器上运转多线程运用所带来的很多优化问题。