字符辨认归于方式辨认的领域,一般的字符辨认办法可分为2类:根据字符结构(笔画特征)的结构辨认和根据字符核算特征的核算辨认。结构方式辨认办法的长处是能够辨认杂乱的方式,缺陷是需求进行笔画特征的提取,在输入图画质量欠安的状况下,这一点往往难以做到。在核算方式辨认办法中,特征提取便利,辨认速度与辨认方针无关,但需求得到字符集的安稳特征,且在字符笔画较多时要求的特征量非常大。二种辨认办法各有优缺陷。
人类的视觉感知体系是一个鲁棒性很强的、能抵挡实践中或许遇到的各种变形和噪声搅扰的文字辨认体系。人们的认字进程实践上是对汉字全体形象的掌握,是对汉字图画大局的处理进程[1]。因而,汉字的全体信息在无笔顺辨认中起着无法代替的重要作用。
核算方式辨认凭借概率论的常识,判别或决议计划方针的特征类别,使得决议计划的过错率到达最小。根据核算特征的辨认办法先抽取辨认方针的安稳特征,组成特征矢量,然后在字符集的特征空间中进行特征匹配。根据以上知道,在剖析轿车车牌中汉字字符的特色后,选用了有别于结构剖析的一种根据字符图画特征核算的方式辨认办法进行汉字辨认。一起针对核算办法无法区别的类似汉字,提取其微结构信息进行特别的校对辨认。
1 特征核算匹配
核算决议计划论其关键是提取待辨认方式的一组核算特征,然后依照必定原则所确认的决议计划函数进行分类判定[2]。汉字的核算方式辨认是将字符点阵看作一个全体,从该全体上经过很多核算得到所用特征,竭尽或许少的特征方式来描绘尽或许多的信息。所选用的办法有:特征核算的办法、全体改换剖析法[3]、几许矩特征、笔划密度特征、字符投影特征、外围特征、微结构特征和特征点特征等。这些办法都具有各自的优缺陷,应根据详细运用进行选取。首要办法有外围面积特征匹配法和网格特征匹配法。外围面积特征反映了字符的概括信息。外围面积特征提取法,首要是从周围形状的心理学常识来取得汉字信息的特征,即对文字周围上下左右的形状进行量化,然后结构特征向量。网格特征实践是结构方式辨认和核算方式辨认相结合的产品。字符图画被均匀或非均匀地划分为若干区域,称之为“网格”。在每个网格内寻觅各种特征,如方针面积份额、交叉点、笔划端点的个数、细化后的笔划长度和笔划密度等。特征核算以网格为单位,即便单个点核算有差错也不会造成大的影响,然后增强了特征的抗搅扰性。因而这种办法得到日益广泛的运用。在实践的车牌汉字辨认中,当相同汉字的二值图形改变较小时该办法较有用。详细运用:将尺度为34×66象素的汉字二值图均匀分红32个正方形的小区域(不考虑外边框的1个象素),核算每个8×8的小区域内方针象素(白色)所占的面积份额,就得到了归一化的32维特征矢量。核算多幅相同汉字的32维特征矢量,取均值作为该汉字的规范网格特征模板。辨认时,核算待辨认汉字的32维网格特征矢量与模板矢量之间的Euclid间隔,求得最小间隔值,其对应的汉字即为辨认成果。在详细运用中,因为外部原因常常会呈现字符含糊、字符歪斜的状况,而网格特征匹配办法对字符含糊和歪斜较灵敏,因而鲁棒性不是很强,不适合实践运用。
2 模板匹配
考虑到以上2种首要辨认办法存在的坏处,决议选用模板匹配的算法进行字符的辨认。实践研讨中发现,二值化的图形模板尽管直观,但其匹配核算进程过于简略直接,对歪斜、形变、破损、含糊的待辨认字符匹配差错较大,因而鲁棒性较差。而灰度模板因为颜色、光照等要素影响,难以找到遍及适用的模板方式完结直接的匹配核算。归纳以上二方面的问题,在引进核算方式辨认思维的基础上,提出了根据二值图形改变剖析的含糊模板匹配计划。
2.1 根据二值图形改变剖析的含糊模板匹配
在含有轿车车牌的图画中,将汉字定位并提取出来今后,还要完结规范化、二值化等操作。即便是相同的汉字,因为车牌歪斜、含糊,特别是因为每次定位不或许彻底准确共同等许多要素的影响,导致在二值图中字体的形状、巨细都会不同,字体方位也会产生不同程度的偏移。将这种二值图形的不规则现象称为图形的改变。在汉字辨认的剖析进程中,期望对图形改变的巨细进行量化处理。因而,提出了求图形全体改变量的核算办法,其长处是不需求参照规范图形,能够进行客观点评,并结构出用于匹配辨认的含糊模板。
对每一个车牌的汉字字符,选取n幅质量较好的参阅图。将这n幅参阅图规范化为17×33的规范巨细后进行二值化处理,得到规范参阅图fi(x,y)。因而每个车牌汉字字符都有n幅由0、1所组成的二值图画。将这n幅二值图画对齐后叠加,再进行归一化。得到的含糊图形F(x,y)。四个汉字的含糊图形模板(不同方向的视觉作用)如图1所示。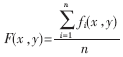
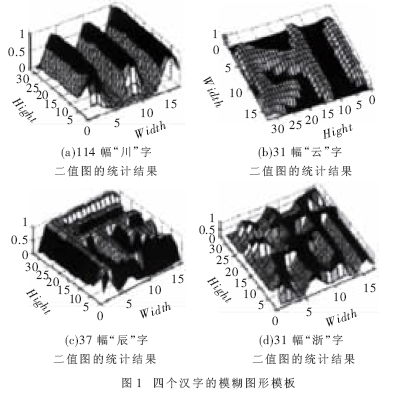
该含糊图形上每一象素点实践上都对应着一个概率值,该概率值代表白色方针(汉字笔划)在该点呈现的或许性。例如在含糊模板中若某一点值为1,标明在一切参与核算的二值图形上汉字笔划都经过该点,其为白色方针象素的或许性是100%,为黑色布景象素的或许性是0;反之亦然。进行匹配辨认时,对一幅切分后的待辨认汉字灰度图,将其规范化、二值化,然后核算每一象素点与模板的符合程度,即每一象素点正确匹配的置信度con(x,y)。引进置信度的公式: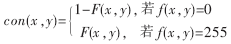
f(x,y)为得到的二值化后的待辨认图画,把一切点的置信度均匀后得到总的置信度con作为判别根据。最大置信度con所对应的模板汉字作为匹配辨认输出的成果。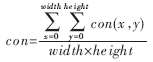
公式中的width和height别离是归一化后规范图画的长和宽。经过对试验成果的剖析发现,辨认过错的图画,往往严峻变形、含糊,二值化作用差。
2.2 根据二值图形改变剖析的含糊模板匹配的改善算法
针对以上问题,提出了一种简略的改善算法。将切分后不同巨细的灰度字符图画规范化为17×33的规范尺度今后,将各象素点的灰度值线性改换到[0,1]区间,再与含糊图形模板匹配,核算Euclid间隔,其最小间隔值对应的模板汉字作为匹配辨认输出的成果。该办法的长处是不必对灰度图画作二值化处理,防止了因为二值化操作带来的图画信息丢失。特别是对一些含糊图画,若直接选用二值化作用较差,影响匹配准确度。因而运用该办法在必定程度上进步了辨认正确率。
试验中发现,对少数明暗程度改变大或对比度不强的含糊图画,该办法也产生了少数辨认过错。这是因为将待辨认图画的各点灰度值线性拉伸到[0,1]区间后,原始图画明暗程度不同导致其均匀值与对应模板的均匀值并不共同,直接用Euclid间隔进行匹配,带来了核算差错。因而引进了归一化相关性衡量公式: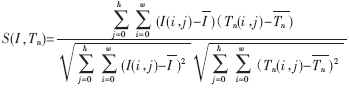
其间I(i,j)和Tn(i,j)别离是输入的待辨认的字符图画和第n个模板,别离是输入字符图画一切灰度的均值和第n个模板的均值,w和h别离为图画的长和宽,S(I,Tn)是匹配函数,其值在0~1之间,代表待辨认图画与模板图画的匹配程度。运用该公式核算相关性,能够防止因为明暗和对比度改变导致图画和模板的“能量”不共同而带来的匹配差错,进一步进步了匹配准确度。
3 试验成果的进一步校对
模板匹配体现的首要是汉字的全体特征,可是有些汉字存在着必定程度上全体的类似性,因而有必要对类似的字符进行进一步的校对才干进步辨认的正确率。对类似汉字的区别,往往是寻觅其特有的笔划结构,这也是在核算方式辨认中引进结构办法的必要之处。例如在车牌汉字辨认中,“粤”字与其他省份汉字的最大区别是底部的钩状结构。为此对预处理后的17×33二值图画的底部1/4部分作水平缓笔直方向的投影,水平投影17个特征值(由左、右二边别离投影得到),笔直投影33个特征值(由上、下二边别离投影得到),构成50维的微结构投影特征矢量。“粤”字微结构特征及其核算41幅图画后的微结构投影特征直方图如图2所示。经核算均匀后作为区别类似汉字的根据。实践校对时,核算微结构特征的匹配间隔。若小于预先设定的阈值,则直接回来该汉字作为辨认成果。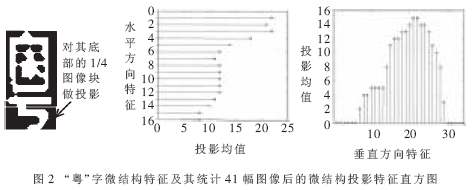
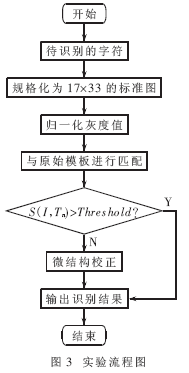
4 试验流程及成果
对辨认300幅切分后的质量较好的汉字灰度图进行辨认,试验流程如图3所示。试验成果标明,外围面积特征匹配法正确率达88%,网格特征匹配法86%,简略模板匹配法91%,改善算法的正确率到达了93%。假如对辨认成果进一步校对,正确率将进步到95%。若再进一步添加练习集,完善模板,信任正确率还能够持续进步。