当今的规划工程师遭到面积、功率和本钱的束缚,不能选用GHz级的核算机完成嵌入式规划。在嵌入式体系中,一般是由相对数量较少的算法决议最大的运算需求。运用规划主动化东西能够将这些算法快速转化到硬件协处理器中。然后,协处理器能够有效地衔接到处理器,发生“GHz”级的功用。
本文首要研讨了代码加快和代码转化到硬件协处理器的办法。咱们还剖析了经过一个涉及到根据辅佐处理器单元(APU)的实践图画显现事例的基准数据均衡决议计划的进程。该规划运用了在一个渠道FPGA中完成的一个嵌入式PowerPC。
协处理器的含义
协处理器是一个处理单元,该处理单元与一个主处理单元一同运用来承当一般由主处理单元履行的运算。一般,协处理器功用在硬件中完成以代替几种软件指令。经过削减多种代码指令为单一指令,以及在硬件中直接完成指令的办法,然后完成代码加快。
最常用的协处理器是浮点单元(FPU),这是与CPU紧密结合的仅有一般协处理器。没有通用的协处理器库,即使是存在这样的库,将仍然难以简略地将协处理器与一个CPU(例如Pentium 4)衔接。Xilinx Virtex-4 FX FPGA具有一个或两个PowerPC,每个都有一个APU接口。经过在FPGA中嵌入一个处理器,现在就有机会在单芯片上完成无缺的处理体系。
带APU接口的PowerPC使得在FPGA中得以完成一个紧密结合的协处理器。由于频率的需求以及管脚数量的约束,选用外部协处理器不大可行。因而能够创立一个直接衔接到PowerPC的专用运用协处理器,大大地提高了软件速度。由于FPGA是可编程的,你能够快速地开发和测验衔接到CPU的协处理器处理计划。
协处理器衔接模型
协处理器有三种根本的办法:与CPU总线衔接的、与I/O衔接的和指令流水线衔接(Instruction Pipeline Connection)。此外,还存在一些这些办法的混合办法。
1. CPU总线衔接
处理器总线衔接加快器需求CPU在总线上移动数据以及发送指令。一般,单个数据处理就需求许多的处理器时钟周期。由于总线裁定以及总线驱动的时钟是处理器时钟的分频,所以会下降数据处理速度。一个与总线衔接的加快器能够包含一个存储器存取(DMA)引擎。在添加额定的逻辑情况下,DMA引擎答应协处理器作业在坐落衔接到总线的存储器上的数据块,独立于CPU。
2. I/O衔接
与I/O衔接的加快器直接衔接到一个专用的I/O端口。一般经过GET或PUT函数供给数据和操控。由于缺少了裁定、操控复杂度下降以及衔接器材较少,因而这些接口的驱动时钟一般比处理器总线更快。这种接口的一个较好的比如如Xilinx Fast Simplex Link(FSL)。FSL是一种简略的FIFO接口,能够衔接到Xilinx MicroBlaze软核处理器或Virtex-4 FX PowerPC。与处理器总线接口中的数据移动比较,经过FSL移动的数据具有较低的延时和更高的数据速率。
3. 指令流水线衔接
指令流水线衔接加快器直接衔接到CPU的核算内核。经过与指令流水线衔接,CPU不能辨认的指令能够由协处理器履行。操作数、成果以及状况直接从数据履行流水线向外传递,或接纳。单个运算能够完成两个操作数的处理,一同回来一个成果和状况。
作为一个直接衔接的接口,衔接道指令流水线的加快器能够用比处理器总线更快的时钟驱动。Xilinx经过APU接口完成这种协处理器衔接模型,关于典型的双操作数指令,在数据操控和数据传输上能够减缩10倍的时钟周期。APU操控器还衔接到数据缓存操控器,经过它能够履行数据加载/存储操作。因而,APU接口能在每秒内移动数百兆字节,挨近DMA速度。
I/O衔接加快器或指令流水线衔接加快器能够与总线衔接加快器结合起来。在添加额定的逻辑条件下,能够创立一个加快器,这个加快器运转在一个坐落总线衔接存储器上的数据块上,经过一个快速、低延时的接口接纳指令并回来状况。
在本文中介绍的C-HDL东西组能够完成总线衔接和I/O衔接加快器,它还能完成衔接到PowerPC的APU接口的加快器。虽然APU衔接是根据指令流水线的,C-HDL东西组完成了一种I/O流水线接口,该接口具有I/O衔接加快器的典型功用。
FPGA/PowerPC/APU接口
FPGA答应硬件规划工程师运用单芯片上的处理器、解码逻辑、外设和协处理器完成一个无缺的核算体系。FPGA能够包含数千到数十万的逻辑单元,能够从这些逻辑单元完成一个处理器,如Xilinx PicoBlaze或MicroBlaze处理器,或许能够是一个或许更多的硬逻辑单元(如Virtex-4 FX PowerPC)。很多的逻辑单元使你能够完成数据处理单元,这些单元与处理器体系一同作业,由处理器对其进行操控或监控。
FPGA作为一种可重复编程的单元,答应你在规划进程中进行编程并对其进行测验。假如你发现了一个规划缺点,你能够当即对其进行从头编程规划。FPGA还答应你完成硬件运算功用,而这在曾经的完成本钱是很高的。CPU流水线与FPGA逻辑之间紧密结合,这样就能够创立高功用软件加快器。
图1的模块框图显现了PowerPC、集成的APU操控器以及一个与之相连的协处理器。来自高速缓存或存储器中的指令能够当即出现在CPU解码器和APU操控器上,假如CPU能辨认指令,则运转这些指令。不然,APU操控器或用户创立的协处理器能够对指令做出应对并履行指令。一个或许两个操作数被传递到协处理器,并回来一个成果或状况。APU接口还支撑用一个指令发送一个数据单元。数据单元的巨细规模从一个字节到4个32位的字。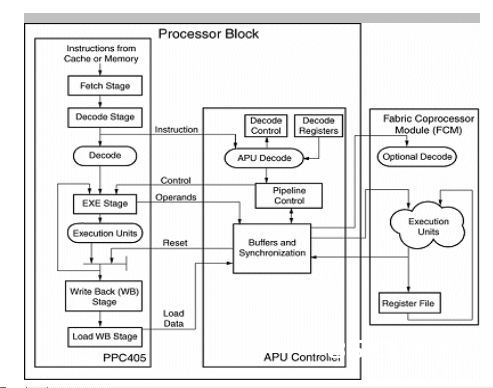
图1:PowerPC、集成的APU操控器和协处理器
经过一个结构协处理器总线(FCB),能够将一个或多个协处理器衔接到APU接口。衔接到总线的协处理器规模包含现存的内核(例如FPU)到用户创立的协处理器。一个协处理器能够衔接到FCB用于操控和状况运算,并衔接到一个处理器总线,完成直接存储器数据块拜访以及DMA数据传递。一种简化的衔接计划,例如FSL,也能够在FCB和协处理器之间运用,在献身必定功用的条件下完成FIFO数据和操控通讯。
为展现指令流水线衔接加快器的功用优势,咱们选用一个处理器总线衔接FPU首要完成了一个规划,然后选用APU/FCB衔接的FPU完成规划。表1总结了两种完成办法下有限脉冲响应(FIR)滤波器的功用。如表1中所反映的相同,衔接到一个指令流水线的FPU使软件浮点运算速度添加30倍,而APU接口比较于总线衔接FPU来说改进了近4倍。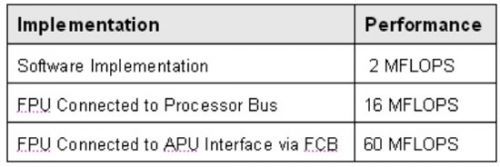
表1:未加快与加快的浮点功用
C代码转化到HDL
选用C到HDL的转化东西将C代码转化到HDL加快器是一种创立硬件协处理器的高效办法。图2所示以及下面胪陈的进程总结了C到HDL转化的进程: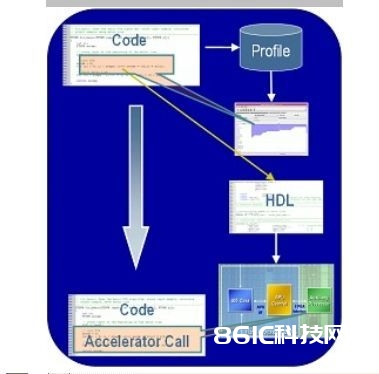
图2:C-HDL规划流程
1. 运用规范C东西完成运用程序或算法。开发一种软件测验向量(test bench)用于基线功用和正确性(主机或台式电脑仿真)测验。运用一种编译器(例如gprof)来开端确认要害的函数。
2. 确认是否浮点到定点转化恰当。运用库或宏来辅佐这种转化,运用一个基线测验向量来剖析功用和精确性。运用编译器来从头评价要害函数。
3. 运用C到HDL转化东西(如Impulse C),在每个要害功用上重复,以完成:将算法分割成并行的进程;创立硬件/软件进程接口(流、同享存储器、信号);对要害的代码段(例如内部代码循环)进行主动优化和并行化;运用桌面电脑仿真、周期精确的C仿真以及实践的在体系测验对得到的并行算法进行测验和验证。
4. 运用C到HDL转化东西将要害的代码段转化到HDL协处理器。
5. 将协处理器衔接到APU接口用于终究的测验。
Impulse:C到HDL转化东西
如图3所示的Impulse C经过结合运用C兼容库函数与Impulse CoDeveloper C代码到硬件的编译器,使嵌入式体系规划工程师能创立高度并行的、FPGA加快的运用。Impulse C经过运用界说无缺的数据通讯、音讯传递和同步处理机制,简化了硬件/软件混合运用规划。Impulse C供给了C代码(例如循环流水线处理、打开和运算符调度)的主动优化以及交互式东西,答应你对每个周期的硬件行为进行剖析。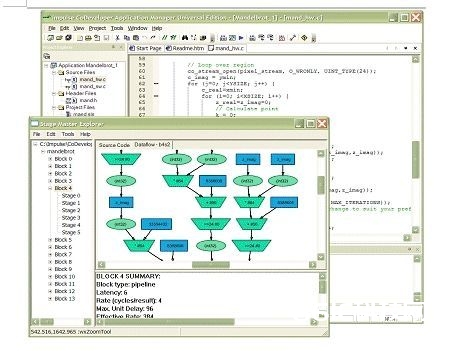
图3. Impulse C
Impulse C规划用于面向数据流的运用,可是它也具有满足的灵活性来支撑其他的编程模型,包含运用同享存储器。这一点很重要,由于根据FPGA不同的运用具有不同的功用和数据要求。在一些运用中,经过块存储器读和写在嵌入式处理器和FPGA之间搬运数据是有含义的;在其它的情况下,撒播数通讯信道或许供给更高的功用。能够快速建模、编译和评价可选的算法的才能关于完成某个运用最佳的成果来说,非常重要。
到目前为止,Impulse C库包含以新数据类型和预界说的函数调用办法的最少C言语扩展。运用Impulse C函数调用,你能够界说多个并行程序段(调用进程),并运用流、信号和其他机制描绘它们的互连。Impulse C编译器将这些C言语进程转化并优化成:能够归纳到FPGA的较初级HDL,或能够经过广泛存在的C穿插编译器编译到支撑的微处理器上规范C(带相关的库调用)。
无缺的CoDeveloper开发环境包含与规范C编译器和调试器(包含微软公司的Visual Studio和GCC/GDB)兼容的台式电脑仿真库。运用这些库,Impulse C程序规划工程师能编译和履行他们用于算法验证和调试意图的运用程序。C程序规划工程师还能查验并行进程,剖析数据移动,并运用CoDeveloper Application Monitor处理进程到进程的通讯问题。
在编译时,Impulse C运用的输出是一组硬件和软件源文件,用于输入到FPGA归纳东西。这些文件包含:
1. 用于描绘编译硬件进程的主动发生的HDL文件;
2. 用于描绘衔接硬件进程到体系总线所需的流、信号和存储器组件的主动发生的HDL文件;
3. 主动发生的软件组件(包含运转时刻库)用于树立任何硬件/软件流衔接的软件端;
4. 附加文件,包含脚本文件,用于输入发生的运用程序到方针FPGA布局布线环境。这种编译进程的成果是一个无缺的运用,包含需求的硬件/软件接口,用于在根据FPGA的编程渠道上完成。
规划实例
图4所示的Mandelbrot图是一种经典的不规则几何图形,该图形广泛用在科学和工程学界用于仿真无序事情,例如气候。不规则图形也用于发生纹路和在视频显现运用上成像。Mandelbrot图画描绘为自相似性。扩大图形的部分,能够获得类似于整个图形的别的一个图形。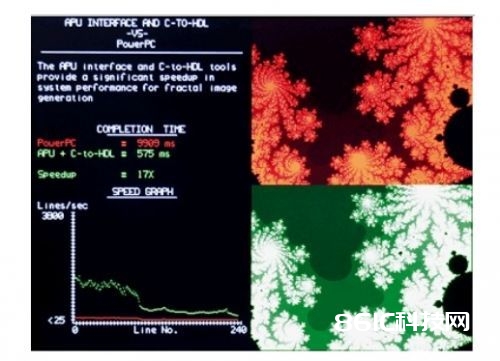
图4:Mandelbrot图
Mandelbrot图形是硬件/软件协同规划的抱负挑选,由于它具有单个运算密布的函数。经过将要害的函数搬运到硬件完成将大大地添加整个体系的速度,使这个要害函数更快。Mandelbrot运用还能清楚地区别硬件和软件进程,运用C-HDL东西很简单完成。
本文运用CoDeveloper东西组作为C-HDL东西组用于该规划实例,并且只修改了软件Mandelbrot C程序以使其与C-HDL东西兼容。其间的改动包含:将软件项目分割成不同的进程(次序履行的独立单元);函数接口转化(硬件到软件)到流;添加编译器指令来对发生的硬件进行优化。咱们随后运用CoDeveloper东西组来创立Pcore协处理器,将该协处理器输入到Xilinx Platform Studio(XPS)。运用XPS,咱们将PC衔接到PowerPC APU操控器接口,并测验体系。
Xilinx公司的运用阐明材料XAPP901中供给了该规划的全面描绘和规划文件,并供给下载。一同,用户攻略UG096供给一种完成规划实例的逐渐规划辅导。
咱们对Mandelbrot图画纹路问题、图画滤波运用和三倍DES加密的功用改进进行了丈量。功用改进显现了从11倍到34倍的加快。