在演算法生意范畴的最新发展是导入一些更低推迟的解决计划,其间最佳的方法是运用FPGA建立的客制硬体。这些FPGA硬体可说是硬编码ASIC的极致功用和CPU的灵敏度之间的桥梁,供给许多的资源且可加以装备,使其得以较软体解决计划更大幅缩短往复生意推迟。
高功用运算关于许多运用至关重要。在其间一些最比赛的运用范畴,开发人员常常能为其嵌入式体系问题找到解决计划。例如,高频生意(HFT)是一种演算生意的方法,其生意量占美国证券生意量的绝大部份。高频生意运用机器学习演算法处理商场材料、拟定战略,以及在几微秒的时刻内履行订单。
为了获得每次生意中哪怕只要几分之一美分的赢利,高频生意员以很高的生意量短期进出生意所。运用HFT演算法的体系继续监测价格动摇状况,以利于调整短线生意战略。因为这是十分短期的生意战略,HFT企业无需消耗许多本钱、累积头寸或隔夜持有其出资组合。现在,高频生意量占美国证券生意量的75%。
在21世纪初,HFT生意侧重于优质的演算法和生意战略。现在,因为最遍及的几种体系仅存在几秒的推迟,决胜的要害不再是速度,而是战略。到了2010年,因为演算法的发展已不足以获得生意优势,为了打败互相,参与者开端缩短tick-to-trade的生意推迟,从而使生意时刻缩短至数微秒。
在次毫秒级生意生意订单的影响下,HFT渠道开端了一场比赛剧烈的速度比赛,以便将商场材料的往复推迟缩短至微秒级。因为只是几奈秒的不同往往带来巨大的‘埋伏套利’比赛优势(或称为‘抢先生意’),生意企业一向在寻觅更快的生意伺服器。
选用软体途径处理订单
传统上,HFT生意一贯运用软体东西。这些东西利用了高功用运算体系,可以高效地履行杂乱的生意战略(图1)。这些体系中的作业体系中心操控对其CPU和记忆体资源的存取,而运用堆叠则负责处理一切的生意战略,由网路介面卡(NIC)衔接体系至证券生意所。
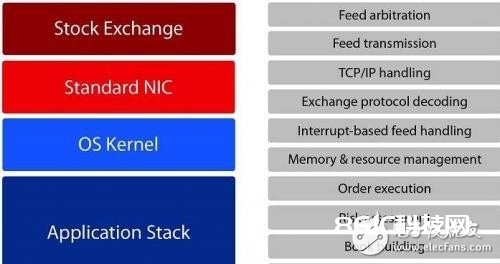
图1:选用软体途径处理订单的装备
可是,这种装备存在生意推迟的缺陷:
规范NIC并未专为处理TCP/IP和专用生意协议进行最佳化,并且无法板载处理商场材料馈送
主体系和乙太网路(Ethernet)卡之间的PCI Express汇流排会增加数微秒的推迟
中心OS原生的依据中止途径就会导致较长的推迟
这些解决计划依据同享记忆体资源的多中心处理器。在处理来自证券生意所的材料馈送不时,确认性推迟至关重要,存取共用记忆体绝不是一个最佳方法
在演算法生意范畴的最新发展是导入了一些更低推迟的解决计划,其间最佳的方法是运用现场可程式逻辑闸阵列(FPGA)建立的客制硬体。这些设备可说是硬编码ASIC的极致功用和CPU灵敏度之间的桥梁。透过FPGA供给许多的资源且可加以装备,使其得以较软体解决计划更大幅缩短往复生意推迟。
选用FPGA途径处理订单
除了灵敏之外,FPGA还可以进行编程规划,以便自行处理材料撷取、危险评价与订单处理等要害使命。这种自给自足的特性使其较软体演算法更快、更牢靠。让依据FPGA的解决计划可以大幅进步电子生意功用的要害因素是:它们能让曩昔由软体处理的进程直接在FPGA上进行。
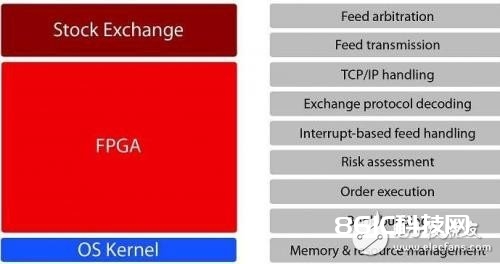
图2:选用FPGA途径处理订单的装备
相较于软体演算法,FGPA的装备具有这些优势,原因就在于以下的功用被分流到FPGA:
处理TCP/IP消息
解码FAST或相似的生意专用协议,以及撷取相关材料
进行生意决议计划,而不至于导致任何依据中心的中止推迟
透过办理FPGA中的订单簿(order book)和生意记载以下降危险
凭藉着这些优势,依据FPGA的解决计划可以供给超低推迟的材料馈送处理功用,以及更快的订单履行和危险评价速度。它们还能完成最高的每瓦功耗功用,尽或许地下降能耗和热量要求。FPGA解决计划的另一个优势是透过扩展布置‘FPGA现场’装备的才能。
组成依据FPGA途径要害之一在于奇妙地整合4倍材料率(QDR)记忆体,完成确认性记忆体存取速率以及经过最佳化的VHDL程式码。在FPGA的记忆体中需求保护的两个最重要材料集是用于保护订单簿的证券资讯和用于剖析危险的材料与时刻戳记。二者均对快取记忆体提出了不同的要求。材料封包的材料与时刻戳记关于保存生意决议计划的精确记载、重现曩昔的事情十分重要。这些记载所需的精密度达数十奈秒,这使得记忆体推迟(即为记忆体供给位址以及从材料汇流排获得材料之间的时刻推迟)愈加至关重要。
另一个材料集-订单簿-是一切订单的材料库,包括生意体系需求保护的符号和价格。这个材料库一般依据生意客户感兴趣的证券而包括一切金融东西的一部份。订单簿有必要依据从客户而来的资讯同步进行更新与存取。订单簿中的相关材料与从生意所收到的材料进行比较,然后再依据生意演算法做出买、卖或保存金融东西的决议计划。
因为来自证券生意所的输入材料串流并不是以确认次序方法接纳的,因而,履行生意战略的记忆体存取也是随机的,以小量材料的丛发进行,并以最低推迟获取材料。以记忆体术语来说,履行这种随机存取的才能是由一种名为随机生意率(RTR)的目标衡量的。RTR表明记忆体在必定时刻内可援助的随机读取或写入作业次数,其衡量目标是:生意次数/秒的倍数(例如MT/s或GT/s)。在大多数记忆体中,随机存取时刻是由周期推迟(tRC)界说。最大的RTR约为tRC的倒数(1/tRC)。
快取记忆体的挑选常常约束依据FPGA的硬体才能。大多数的FPGA只选用传统依据DRAM的记忆体,因为它们具有本钱优势,并且密度较高。可是,这些记忆体极端缓慢,并且容易发生软过错。考虑到这些体系每秒的生意量,咱们不能献身速度和牢靠性。
从纯技能的视点讨论两种运用最广泛的DRAM:同步DRAM(SDRAM)和低推迟DRAM(RLDRAM)。曩昔10年来,SDRAM的tRC并没有很大改变(将来或许也不会),一向维持在48ns左右,对应21 MT/s RTR,其它依据DRAM的记忆体规划则以献身密度改进了tRC。例如,RLDRAM 3的tRC为8ns,对应于125MT/s RTR。基本上,DRAM是为那些依序存取确认性运算演算法而最佳化的,但高频生意并非选用这样的方法。
一个更好的挑选是同步SRAM。尽管依据DRAM的记忆体具有较高的记忆体容量,但它们无法满意生意渠道运用快取记忆体的推迟和功用要求。数十年来,SRAM一向是大多数高功用运用的首选记忆体。依据SRAM的解决计划或许比一般依据DRAM的解决计划更快高达24倍。
在SRAM中,QDR系列SRAM的功用比任何类型的记忆体都要高。QDR SRAM是专为突发和随机存取而规划的。藉由一个读写专用埠,QDR记忆体是订单簿办理等读写均衡作业的抱负挑选。例如赛普拉斯半导体(Cypress Semiconductor)最新推出的QDR SRAM——QDR-IV,更进一步供给了两个双向埠。当读写作业不均衡时,例如当查询TCP/IP处理和材料串流处理等操作时,选用QDR-IV将会十分高效。
下表比较各种中心记忆体技能选用的解决计划:
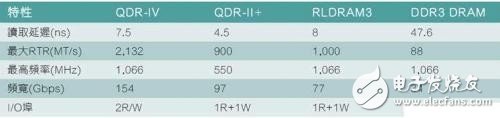
表1:各种中心记忆体技能计划的特性比较
各种记忆体的RTR功用比较
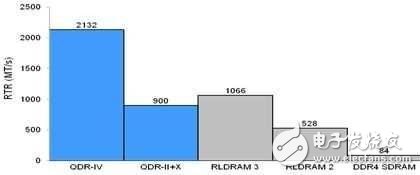
图3:各种记忆体技能的RTR比较
除了RTR和推迟优势之外,许多SRAM还包括一系列新的特性,例如可完成高牢靠性的过错纠正码(ECC)、晶片上终端(ODT)以及可进步信号完整性的偏斜校对(De-skew)练习。
有鉴于几奈秒所能带来的比赛优势,在打造一个依据FPGA的客制化解决计划时,所选用的记忆体类型也是一项要害因素。因为QDR记忆体所具有的固有优势,许多FPGA厂商正为其最新一代依据FPGA的高功用生意解决计划导入QDR记忆体。相较于那些运用传统记忆体解决计划的生意员,选用这些FPGA的生意员具有先下手为强的优势。QDR记忆体还获得了Altera、Xilinx等业界首要FPGA供货商的支撑。Altera最新发布的Arria 10 FPGA即可援助QDR-IV。估计Xilinx等者很快也会宣告在其产品中供给相似的援助。
QDR-IV记忆体的RTR为2132MT/s,推迟为7.5ns。考虑到随机存取功用关于FPGA解决计划的重要性,这些记忆体有助于大幅缩短生意的总推迟。该款SRAM较高的作业频率和双埠作业特性,可为那些要求苛刻的网路环境建立超低推迟的材料封包缓冲区。此外,QDR-IV无与伦比的RTR可加速需求即时查询或其它材料结构的客制运用。而DRAM则更适合贮存材料许多的材料记载资讯,而高功用的SRAM可与其合作作业,贮存推迟要害型途径的运算查询或缓存材料。