在前不久的 Baidu Create 2019 百度 AI 开发者大会上,Apollo 发布了业界创始的 AVP 专用车载核算渠道——百度 AVP 专用量产核算单元 ACU-Advanced。这是一篇“硬核”的技能文章。正是这些后台的“硬核”技能,成果了令人夺目的自动驾驭。本文中介绍的相关技能现已落真实 Valet Parking 产品中的量产 ACU 硬件上。
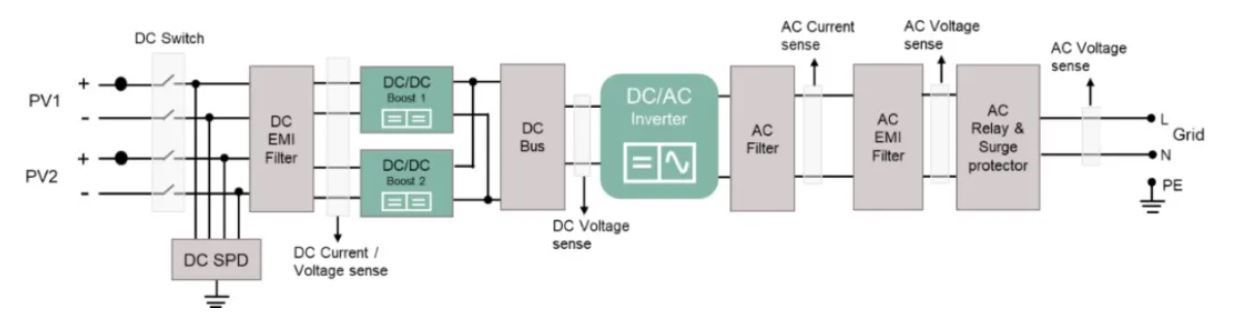
人工智能技能是自动驾驭的根底,算法、算力和数据是其三大要素。本文讨论的便是其间的“算力”。算力的凹凸,不只直接影响了行进速度的凹凸,还决议了有多大的信息冗余用来确保驾驭的安全。算力最直观地体现在硬件上,而轿车对自动驾驭的控制器有特别的要求。实践中遇到的应战是,多种多样的加快需求和有限的硬件资源的对立。需求的来历既包含深度学习前向估测、也包含根据规矩的算法。硬件资源受限包含了:FPGA 资源受限和内存带宽受限。
算法工程师选用浮点数 float32 对模型进行练习,产出的模型参数也是浮点型的。然而在咱们运用的 FPGA 中,没有专用的浮点核算单元,要完结浮点数核算,价值很大,不行行。运用 int8 核算来迫临浮点数核算,也即完结量化核算,这是需求处理的第一个问题。
在量化前,需求完结1000000次 float32 的乘法。量化成 int8 后,需求完结1000000次 int8 的乘法,和30000次量化、反量化乘法。因为量化和反量化占的比重很低,量化的收益就等于 int8 替代 float32 乘法的收益,这是十分明显的。
FPGA 片上存储十分受限,关于绝大多数的算子,不行能将输入或许输出完好缓存到片上内存中。而是从内存中一旦读取满足的数据,就开端核算。一旦核算到满足多,就立即把成果写到内存。和内存数据的流式交互是个公共的需求,咱们开发了能统筹一切算子的 DMA 的接口。
只要关于单次核算耗时很长、或调用十分频频的独立使命算子,咱们才为其定制独自 DMA 的模块,获得的收益是,这个算子能够经过多线程调度和其它 FPGA 算子并行核算。这是归纳收益和价值后,做出的以资源换时刻的折衷。
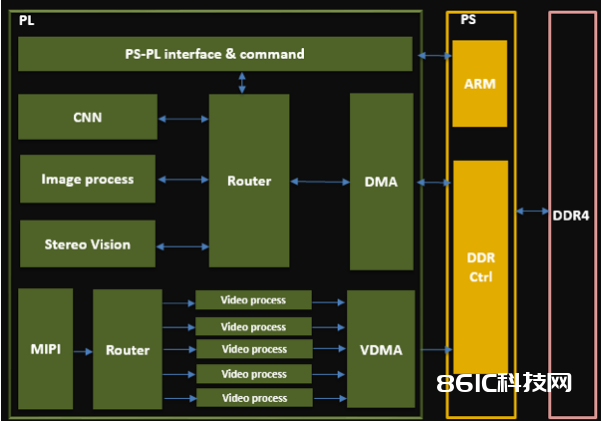
Int8 的核算,能够运用 DSP 或其它逻辑资源来完结。逻辑资源有更多的用处,所以咱们占用 DSP 来完结 int8 的乘累加核算。FPGA 内部的 DSP48E2 能够承受 27bit 的乘数。能够把两个 int8 的乘数摆放在高 8bit 和低 8bit,进行一次乘法后,再两个乘积完好的分离出来。这样,就完结了单个 DSP 一个时钟周期完结了两个乘法,达到了算力倍增的效果。
Deconv 和 conv 是网络中核算量最大的两个算子,核算资源复用收益很大。但它们核算方式上不同很大,直接复用核算资源很困难。咱们在理论进步行打破,完结了通用的资源复用的办法。简言之,SDK 要对 conv 的核算参数进行扩大以兼容 deconv,在核算 deconv 时,需求对卷积核进行分拆、重排,伪装成 conv。FPGA 核算结束后,添加少数逻辑对成果进行润饰。
ARM 核算:有些算子,比方多通道的 softmax、concat、split 等,呈现频率很低,数据量不大,对全体帧率影响很小,还有些算子比方 PSRoiPooling、核算区域不确定、数据不能确保对齐,十分不适合 FPGA 加快。把这两类算子放在 ARM 上完结。在 ARM 上对核算影响最大的单个要素是缓存命中率。经过数据重排、改动遍历次序等,进步缓存命中率,能够把表观 ARM 算力进步几十倍。
NEON 加快:选用 NEON 指令能够对多通道的 Softmax 算子有用加快,加快比虽然不及 FPGA,但相关于直接选用未优化的 C++ 的代码在 ARM 上履行,效果能够进步数倍。其它对齐的核算,大多能够经过 NEON 处理器加快数倍。
MaliGPU:咱们现在运用 Xilinx ZU 系列的 FPGA,自带 MaliGPU 400,本来被规划用来显现时烘托,并不支撑 CUDA、OpenCL 等常用库。经过特别的驱动方法,咱们做到能够利用它完结一些受限的逐像素算子。咱们实践核算运用的硬件资源包含了 FPGA、MaliGPU、ARM 主处理器、ARM Neon 协处理器4种。经过 ARM(主处理其和协处理器)和 MaliGPU 完结对部分算子进行接受,有用缓解了 FPGA 的资源压力。
而选用动态量化,查找量化标准和进行量化,需求涣散在相邻的两个算子中完结。为了确保精度,中心成果需求以半浮点(float16)方式表明。这带来两个问题:CPU 并不能直接对 FP16 的数据进行转化或核算,所以需求 FPGA 供给额定的算子,供给快速的 float32 / int8 和 float16 转化。这些额定的算子,是 CNN 自身不需求的,这构成了糟蹋。Float16 需求的缓存比 int8 大了一倍。糟蹋了 FPGA 的存储资源。
而静态量化,离线供给了固定的量化参数,中心核算成果以量化后的 int8 方式来表明。以上的糟蹋都得以防止。虽然静态量化对模型练习做额定的要求,咱们终究决议切换到静态量化。经过 SDK 将各种参数进行改换和兼并,单个 conv 算子能够完结最多支撑4个算子的组合 conv + batchnorm + scale + relu。
静态量化降低了内存吞吐,这也是咱们抛弃动态量化易用性的一个原因。使命的帧率是峰值算力、各算子算力、支撑的算子品种三个要素复合效果的成果。以上技能现已用到了 ACU 硬件中,把百度 Valet Parking 产品的帧率在数量级进步行了进步。接下来,咱们会连续发布更多这样的“硬核”技能文章,让更多开发者们愈加详尽地了解 Apollo 自动驾驭背面的技能。