5.7 FPGA规划的IP和算法运用
根据IP的规划已成为现在FPGA规划的干流办法之一,本章首要给出IP的界说,然后以FFT IP核为例,介绍赛灵思IP核的运用。
5.7.1 IP核总述
IP(Intelligent Property) 核是具有知识产权核的集成电路芯核总称,是通过重复验证过的、具有特定功用的宏模块,与芯片制作工艺无关,能够移植到不同的半导体工艺中。到了SOC 阶段,IP核规划已成为ASIC电路规划公司和FPGA供给商的重要任务,也是其实力表现。关于FPGA 开发软件,其供给的IP核越丰厚,用户的规划就越便利,其商场占用率就越高。现在,IP核现已变成体系规划的根本单元,并作为独立规划效果被交流、转让和出售。
从IP核的供给方法上,一般将其分为软核、硬核和固核这3类。从完结IP核所花费的本钱来讲,硬核价值最大;从运用灵活性来讲,软核的可复用运用性最高。( 这部分内容前面现已论述,这儿再重申一下)
软核(Soft IP Core)
软核在EDA规划范畴指的是归纳之前的寄存器传输级(RTL) 模型;具体在FPGA规划中指的是对电路的硬件言语描绘,包括逻辑描绘、网表和协助文档等。软核只通过功用仿真,需求通过归纳以及布局布线才干运用。其长处是灵活性高、可移植性强,答运用户自装备;缺陷是对模块的猜测性较低,在后续规划中存在产生过错的可能性,有必定的规划危险。软核是IP 核运用最广泛的方式。
固核(Firm IP Core)
固核在EDA规划范畴指的是带有平面规划信息的网表;具体在FPGA规划中能够看做带有布局规划的软核,一般以RTL 代码和对应具体工艺网表的混合方式供给。将RTL描绘结合具体规范单元库进行归纳优化规划,构成门级网表,再通过布局布线东西即可运用。和软核比较,固核的规划灵活性稍差,但在可靠性上有较大进步。现在,固核也是IP核的干流方式之一。
硬核(Hard IP Core)
硬核在EDA 规划范畴指通过验证的规划地图;具体在FPGA 规划中指布局和工艺固定、通过前端和后端验证的规划,规划人员不能对其修正。不能修正的原因有两个:首要是体系规划对各个模块的时序要求很严厉,不答应打乱已有的物理地图;其次是维护知识产权的要求,不答应规划人员对其有任何改动。IP 硬核的不许修正特色使其复用有必定的困难,因而只能用于某些特定运用,运用范围较窄。
IP Core生成器(Core Generator) 是Xilinx FPGA规划中的一个重要规划东西,供给了很多老练的、高效的IP Core为用户所用,涵盖了汽车工业、根本单元、通讯和网络、数字信号处理、FPGA特色和规划、数学函数、回忆和存储单元、规范总线接口等8 大类,从简略的根本规划模块到杂乱的处理器一应俱全。合作赛灵思网站的IP中心运用,能够大幅度减轻规划人员的作业量,进步规划可靠性。
Core Generator最重要的装备文件的后缀是xco,既可所以输出文件又可所以输入文件,包括了当时工程的特点和IP Core的参数信息。
5.7.2 FFT IP核运用示例
ISE供给了FFT/IFFT的IP Core,能够完结实数、复数信号的FFT以及IFFT运算。FFT的IP Core供给三种结构,分别为:
(1) 流水线,Streaming I/O结构:答应接连的数据处理;
(2) 基4,Burst I/O结构:供给数据导入/导出阶段和处理阶段。此结构具有较小的结构,但转化时刻较长;
(3) 基2,Burst I/O结构:运用最少的逻辑资源,同Radix-4相同,供给两阶段的进程。其装备界面有3页,第一页如图5-57所示,首要用于装备完成结构;第二页装备数据位宽以及数据处理操作;第三页装备数据缓存空间。
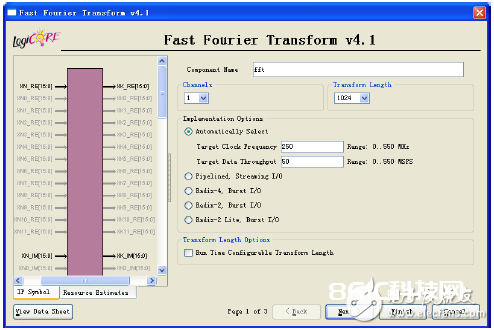
图5-57 FFT IP core的用户界面
在实践硬件操作中,模块的履行速度是很重要的参数,所以本文剖析第一种结构,即流水线Streaming I/O结构,以进行接连的数据处理。在进行当时帧的N点数据时,可加载下一帧的N点数据,一起输出前一帧的N点数据。此结构由多个基2的蝶形处理单元构成,每个单元都有自己的存储单元来存储输入和中心处理的数据,其结构如图5-58所示。
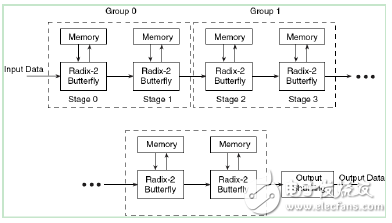
图5-58 FFT模块的流水线,Streaming I/O结构
FFT的核算单元具有丰厚的操控信号,其具体阐明见下文。
XN_RE、XN_IM :输入操作数,分别为实部和虚部,以2 的补码输入。在运用时应当确认其位宽。
START :FFT开端信号,高有用。当此信号变高时,开端输入数据,随后直接进行FFT 转化操作和数据输出。一个START脉冲,答应对一帧进行FFT 转化。假如每N 个时钟有一个START脉冲或许START一直为高,,则都能够接连进行FFT。假如在开端的START前,还没有NFFT_WE,FWD_INV_WE,SCALE_SCH_WE信号,则START变高后就运用这些信号的默认值。由于此IP Core支撑非接连的数据流,因而在任何时刻输入START,即可开端数据的加载。当加载N个数据完毕后,就开端FFT转化运算。
UNLOAD :关于Burst I/O结构,此信号将开端输出处理的成果。关于流水线结构和比特逆序输出的状况,此端口不是必要的。
NFFT :此端口只对实时可装备运用时有用。
NFFT_WE :此端口是NFFT 端口的使能信号。
FWD_INV :用以指示IP Core为FFT仍是IFFT,其等于1时IP Core进行FFT运算,不然进行IFFT 运算。至于选用哪种转化运算是能够逐帧改变的。这一端口给FFT的运用供给了很大的便利。
FWD_INV_WE :作为FWD_INV端口的使能信号。
SCALE_SCH:(1) 在IP Core规划时,假如挑选在核算进程中进行中心数据的减缩,那么此信号才可起作用;(2) 输入的位宽等于2*ceil(NFFT/2),其间NFFT = log2(point size)。(3) 流水线结构中,将每个基2的蝶形处理单元视为一个阶段,每个阶段进行一次数据的减缩,减缩的份额以此输入中对应阶段的两比特表明。(4) 每阶段的两比特数可所以3,2,1或0 :它们表明了数据所需求移动的比特数。
SCALE_SCH_WE :作为SCALE_SCH的使能信号。
SCLR :可选端口。
Reset :重置信号端口。Reset=1时,一切作业都中止且初始化。但内部的帧缓存保存其内容。
CE :可选端口。
CLK :输入时钟。
XK_RE,XK_IM :输出数据总线,以2 的补码输出。SCALE_SCH_WE有用时,输出位宽等于输入;不然,输出位宽= 输入位宽+NFFT+1。
XN_INDEX :位宽等于log2(point size),输入数据的下标。
XK_INDEX :位宽等于log2(point size),输出数据的下标。
RFD :数据有用信号,高有用,在加载数据时为高电平。
BUSY :IP Core 作业状况的指示信号,在核算FFT 转化时为高电平。
DV :数据有用指示信号,当输出端口存在有用数据时变高。
EDONE :高有用。在DONE 信号变高的前一个时钟变为高电平。
DONE :高有用。在FFT 完结后变高,且只存在一个时钟。在DONE 变高后,IP Core开端输出核算成果。
BLK_EXP :当运用Burst I/O 结构时可用,若挑选流水线,则此端口无效
OVFLO :算法溢出指示。在数据输出时,如每帧有溢出,此信号变高。在每帧开端处,此信号重置。
例5.7.1运用IP Core实例化一个16点、位宽为16位的FFT 模块。
IP Core 直接生成的乘法器的Verilog 模块接口为:
module fft16(sclr, fwd_inv_we, rfd, start, fwd_inv, dv, scale_sch_we, done, clk, busy, edone, scale_sch,xn_re, xk_im, xn_index, xk_re, xn_im, xk_index);
input sclr , fwd_inv_we, start, fwd_inv, scale_sch_we, clk;
input [3 : 0] scale_sch;
input [15 : 0] xn_re;
output rfd, dv, done, busy, edone;
output [15 : 0] xk_im;
output [3 : 0] xn_index;
output [15 : 0] xk_re;
input [15 : 0] xn_im;
output [3 : 0] xk_index;
……
endmodule
在运用时,直接调用mulTIply 模块即可,如
module fft16(sclr, fwd_inv_we, rfd, start, fwd_inv, dv, scale_sch_we, done, clk, busy,
edone, scale_sch, xn_re, xk_im, xn_index, xk_re, xn_im, xk_index);
input sclr , fwd_inv_we, start, fwd_inv, scale_sch_we, clk;
input [3 : 0] scale_sch;
input [15 : 0] xn_re;
output rfd, dv, done, busy, edone;
output [15 : 0] xk_im;
output [3 : 0] xn_index;
output [15 : 0] xk_re;
input [15 : 0] xn_im;
output [3 : 0] xk_index;
fft fft1( // 调用FFT 的IPCore
.sclr(sclr), .fwd_inv_we(fwd_inv_we), .rfd(rfd), .start(start), .fwd_inv(fwd_inv),
.dv(dv), .scale_sch_we(scale_sch_we), .done(done), .clk(clk), .busy(busy),
.edone(edone), .scale_sch(scale_sch), .xn_re(xn_re), .xk_im(xk_im),
.xn_index(xn_index), .xk_re(xk_re), .xn_im(xn_im), .xk_index(xk_index));
endmodule
通过仿真测验得到的功用波形图如图5-59所示:

图5-59 FFT的IP core仿真波形