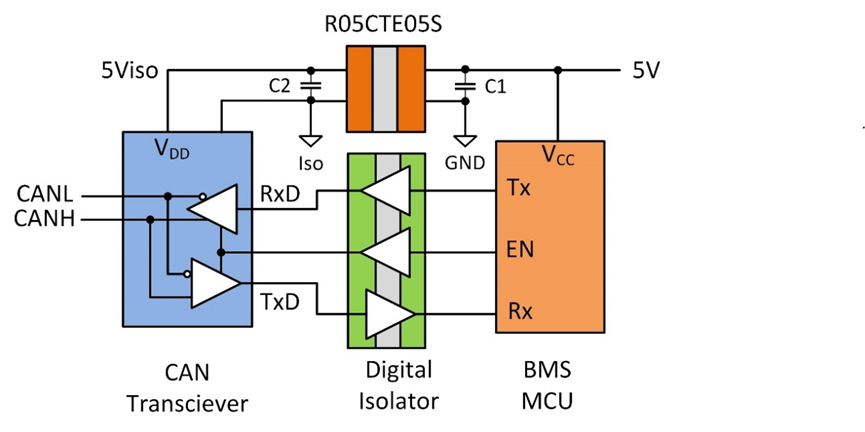
近几年来,强化学习在使命导向型对话体系中得到了广泛的运用,对话体系通常被计算建模成为一个 马尔科夫决议计划进程(Markov Decision Process)模型,通过随机优化的办法来学习对话战略。
使命导向型对话体系用于协助用户完结某个使命如查电影、找饭馆等,它一般由四个模块组成: 天然语言了解模块(Natural Language Understanding, NLU)、对话状况盯梢模块(Dialog State Tracking, DST)、对话战略模块(Dialog Policy, DP)和天然语言生成模块(Natural language Generation, NLG) ,其间 DST 和 DP 合称为 对话办理模块。
在和用户的每轮交互进程中,对话体系运用 NLU 将用户的句子解析成为机器可了解的语义标签,并通过 DST 保护一个内部的对话状况作为整个对话前史的紧凑表明,依据此状况运用 DP 挑选适宜的对话动作,最终通过 NLG 将对话动作转成天然语言回复。对话体系通过和用户进行交互得到的对话数据和运用得分则可用于进行模型的强化学习练习。
然而在实践中,和实在用户的交互本钱贵重,数据回流周期慢,不足以支撑模型的快速迭代,因而研究者们通常会构建一个 用户模仿器(User Simulator, US)作为对话体系的交互环境来进行闭环练习。有了用户模仿器发生恣意多的数据,对话体系可以对状况空间和动作空间进行充分地探究以寻觅最优战略。
一个作用杰出的用户模仿器,咱们希望它 具有以下 3 个特征:
有一个整体的对话方针,可以生成上下文连接的用户动作;有满足的泛化才能,在语猜中未呈现的对话景象里也能生成合理的行为;可以给出定量的反应评分用于辅导模型学习优化。为了完结以上方针,学术界做了很多的研究工作,从最根底的 bi-gram 模型 [4] ,到经典有用的 Agenda-based的办法 [2] ,再到最近依据深度学习的用户模型 [9, 10] ,用户模仿器的作用得到了明显提高,也为对话模型的练习供给了有用的办法。
一个比较典型的用户模仿器,对话开始时用户模仿器依据 User Goal(用户方针)宣布一个话术:“Are there any acTIon movies to see this weekend?”(这个周末有什么动作片可以看的吗?),这句话进到对话体系的天然语言了解模块和对话办理模块后,生成一句体系动作:“request_locaTIon”(问询地址)。
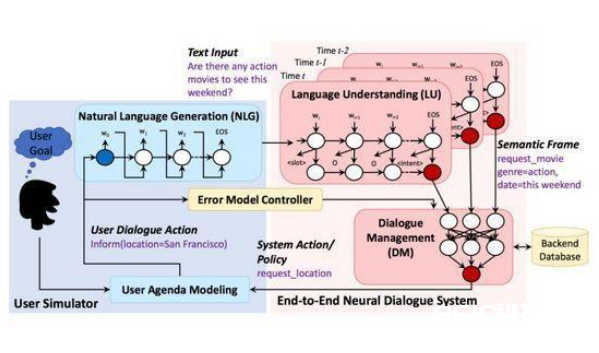
简洁起见,这儿省掉掉体系的 NLG 模块,体系回复直接送到用户模仿器的用户模型(User Model),通过用户状况更新和行为战略挑选,生成用户对话行为:“inform(locaTIon=San Francisco)”(奉告地址为旧金山),接下来通过 Error Model(可选)和 NLG 模块,生成对应的天然语言,比方:“San Francisco, please.”(帮我订旧金山的)。以此往复,用户模仿器和对话体系继续多轮交互,直到对话完毕。
从上面的进程咱们可以看到,典型的用户模仿器和对话体系的结构比较类似,包括以下 4 个根本组成部分:
1. 用户方针(User Goal): 用户模仿的第一步便是生成一个用户对话的方针,对话体系对此是不可知的,但它需求通过多轮对话交互来协助用户完结该方针。一般来说,用户方针的界说和两种槽位相关: 可奉告槽(informable slots)和可问询槽(requestable slots),前者形如“槽=值”是用户用于查询的约束条件,后者则是用户希望向体系问询的特点。
例如:用户方针是 “inform(type=movie, genre=acTIon, location=San Francisco, date=this weekend),request(price)”表达的是用户的方针是想要找一部本周在 San Francisco 上映的动作片,找到电影后再进一步问询电影票的价格特点。有了清晰的对用户方针的建模,咱们就可以确保用户的回复具有必定的使命导向,而不是闲谈。
2. 用户模型(User Model): 用户模型对应着对话体系的对话办理模块,它的使命是依据对话前史生成当时的用户动作。用户动作是预先界说好的语义标签,例如“inform, request, greet, bye”等等。用户动作的挑选应当合理且多样,可以模仿出实在用户的行为。用户模型是用户模仿器的中心组成部分,在接下来的章节里咱们将会详细介绍各种详细模型和办法。
3. 差错模型(Error Model): 它接在 User Model 下流,担任模仿噪声,对用户行为进行扰动以模仿实在交互环境下不确定性。简略的方法有:随机用不正确的目的替换正确的目的、随机替换为不正确的槽位、随机替换为不正确的槽值等;杂乱的方法有模仿依据 ASR 或 NLU 混杂的过错。
4. 天然语言生成(NLG): 假如用户模仿器需求输出天然语言回复,就需求 NLG 模型将用户动作转换成天然语言表述。例如用户动作标签“inform(type=movie, genre=action, date=this weekend)” 进行 NLG 模块后生成天然句子“Are there any action movies to see this weekend?”。