人工智能(AI)现在正在为社会的方方面面带来改造。比方,经过结合数据发掘和深度学习的优势,现在能够运用人工智能来剖析各种来历的很多数据,辨认各种形式、供给交互式了解和进行智能猜想。
人工智能(AI)现在正在为社会的方方面面带来改造。比方,经过结合数据发掘和深度学习的优势,现在能够运用人工智能来剖析各种来历的很多数据,辨认各种形式、供给交互式了解和进行智能猜想。
这种立异开展的一个比方便是将人工智能运用于由传感器生成的数据,尤其是经过智能手机和其他顾客设备所搜集的数据。运动传感器数据以及其他信息比方GPS地址,可供给很多不同的数据集。因而,问题在于:“怎么运用人工智能才干充分发挥这些协同效果?”
运动数据剖析
一个说明性的的实在运用程序将能够经过剖析运用数据来确认用户在每个时刻段的活动,无论是在坐姿、走路、跑步或许睡觉情况下。
在这种情况下,智能产品的优点显而易见:
1.进步客户生命周期价值
进步用户参加度能够下降客户流失率。
2.更具竞争力的产品定位
下一代智能产品满意顾客日益增长的等待。
3.为终端用户发明真实的价值
对室内运动的精确检测和剖析可完结活络的导航功用、进行健康危险监控,一起进步设备的功率。 对多种智能手机和可穿戴渠道实践运用情形的深度把握,将大大有助于产品设计师了解用户的重复习气和行为,例如确认正确的电池尺度或确认推送告诉的正确机遇。
智能手机制造商关于人工智能功用的兴趣正浓,这也正突出了辨认简略日常活动,如步数的重要性,这必将开展为更为深化的剖析,例如体育活动。关于像足球这样的盛行体育运动,产品设计师不会只着眼于运动员,而是会为更多的人供给便当,比方教练、球迷乃至是广播公司和运动服装设计公司等大型公司。这些公司将从深层次的数据剖析中获益,然后能够精确量化、进步和猜想运动体现。
数据获取和预处理
在辨认这一商机之后,下一个合理的进程便是考虑怎么有用搜集这些巨大的数据集。
比方在活动盯梢方面,原始数据经过轴向运动传感器得以搜集,例如智能手机、可穿戴设备和其他便携式设备中的加快度计和陀螺仪。这些设备以彻底荫蔽的办法获取三个坐标轴(x、y、z)上的运动数据,即以便于用户运用的办法接连盯梢和评价活动。
练习模型
关于人工智能的监督式学习,需求用符号数据来练习“模型”,以便分类引擎能够运用此模型对实践用户行为进行分类。举例来说,咱们从正在进行跑步或是走路的测验用户那里搜集运动数据,并把这些信息供给给模型来协助其学习。
因为这根本上是一种一次性办法,简略的运用程序和照相体系就能够完结给用户“贴标签”的使命。咱们的经历标明,跟着样本数量的添加,在分类上的人为错误率随之削减。因而,从有限数量的用户那里获取更多的样本集比从很多用户那里获得较小的样本集更有意义。
只获取原始传感器数据是不行的。咱们观察到,要完结高度精确的分类,需求细心确认一些特征,即体系需求被奉告关于区别各个序列重要的特征或许活动。人工学习的进程具有反复性,在预处理阶段,哪些特征最为重要还没有清晰。因而,设备必需求根据或许对分类精确性有影响的专业知识进行一些猜想。
为了进行活动辨认,指示性特征能够包含“滤波信号”,例如身体加快(来自传感器的原始加快度数据)或“导出信号”,例如高速傅里叶改换(FFT)值或标准差核算。
举例来说,加州大学欧文分校的机器学习数据库(UCI)创建了一个界说了561个特征的数据集,这个数据集以30名志愿者的六项根本活动,即站立、坐姿、卧姿、行走、下台阶和上台阶为根底。
形式辨认和分类
搜集了原始运动数据之后,咱们需求运用机器学习技能来将其分类并进行剖析。可供咱们运用的机器学习技能从逻辑回归到神经网络等不胜枚举。
支撑向量机(SVMs)便是这样一个运用于人工智能的学习模型。身体活动,比方走路包含了由多种运动构成的序列,因为支撑向量机擅长于序列分类,因而它是进行活动分类的合理挑选。
支撑向量机的运用、练习、扩展和猜想均十分简略,所以能够轻松地并排设置多个样本搜集试验,以用于处理杂乱的实际生活数据集的非线性分类。支撑向量机还可完结多种不同的尺度和功用优化。
确认一项技能后,咱们有必要为支撑向量机挑选一个软件图书馆。开源库LibSVM是一个很好的挑选,它十分安稳而且有具体的记载,支撑多类分类,并供给一切首要开发者渠道从MATLAB到Android的拓宽。
继续分类的应战
在实践中,用户在移动的一起,运用中的设备要进行实时分类来进行活动辨认。为了将产品本钱降到最低,咱们需求在不影响成果也便是信息质量的前提下,平衡传输、存储和处理的本钱。
假定咱们能够担负数据传输的费用,一切数据都能够在云端上获得存储和处理。实践上,这会为用户带来巨大的数据费用,用户的设备当然要衔接互联网,无线网络、蓝牙或4G模块的费用不可避免地将进一步提高设备本钱。
更糟糕的是,在非城市区域,3G网络的拜访效果一般不抱负,例如徒步旅行、骑自行车或游水时。这种对云端的很多数据传输的依靠会使更新变慢,而且需求定时同步,然后大大抵消人工智能运动剖析带来的实践好处。与之相反,仅在设备的主处理器上处理这些操作会显着导致耗电量的添加,而且削减其他运用的履行周期。同理,将一切数据都储存在设备上会添加存储本钱。
化圆为方
为了处理这些互相抵触的问题,咱们能够遵从四个准则:
1.拆分——将特征处理从分类引擎的履行中拆分。
2.削减——智能挑选精确的活动辨认所需的特征,来削减存储和处理的需求量。
3.运用——运用的传感器须能够以较低耗电量获取数据、施行传感器交融(将多个传感器的数据结合在一起),而且能够为继续履行进行特征预处理。
4.保存——保存能够确认用户活动的体系支撑性数据的模型。
经过将特征处理与分类引擎的履行拆分,与加快度和陀螺仪传感器衔接的处理器能够小得多。这有用避免了将实时数据块接连传输到更强壮的处理器的需求。比方用于将时刻域信号改换为频率域信号的高速傅里叶改换的特征处理将需求低功耗融核处理器,以履行浮点运算。
此外,在实际国际中,单个传感器存在物理约束,而且其输出随时刻产生误差,例如因为由焊接和温度引起的偏移和非线性缩放。为了补偿这种不规则性,需求传感器交融,以及快速、内联和主动的校准。
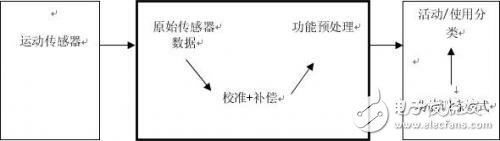
图1:活动分类的功用流程
此外,所挑选的数据捕获速率能够显着影响所需的核算和传输量。一般来说,50Hz采样率关于正常的人类活动就满足了。但在对快速移动的活动或运动进行剖析时,需求200 Hz的采样率。同样地,为了获得更快的呼应时刻,能够装置2 kHz独自加快计来确认用户意图。
为了迎候这些应战,低功耗或许运用特定传感器集线器能够显着下降分类引擎所需的CPU周期。比方Bosch Sensortec的BHI160和BNO055两个产品便是这种传感器集线器。相关软件可直接以不同的传感器数据速率直接生成交融后的传感器输出。




对待处理特征的初始挑选随后会极大地影响练习模型的巨细、数据量以及练习和履行内联猜想所需的核算才能。因而,对特定活动分类和区别所需的特征进行挑选是一项要害的决议,一起也很或许是重要的商业优势。
回忆咱们上文说到的UCI机器学习数据库,其具有561个特征的完好数据集,运用默许的LibSVM内核练习的模型进行活动分类的测验精确度高达91.84%。但是,完结练习和特征排名后,挑选最重要的19项功用足以到达85.38%的活动分类测验精确度。经过对排名进行细心检查,咱们发现最相关的特征是频域改换以及滑动窗口加快度原始数据的平均值、最大值和最小值。风趣的是,这些特征都不能只是经过预处理完结,传感器交融关于保证数据的满足可靠性十分必要,并因而对分类尤为有用。
定论
总而言之,科技开展现在现已到达在便携式设备上运转高档人工智能来剖析运动传感器的数据的程度。这些现代传感器以低功耗运转,而传感器交融和软件分区则显着进步了整个体系的功率和可行性,一起也大大简化了运用程序开发。
为了弥补传感器的根底架构,咱们运用开源库和最佳实践来优化特征提取和分类。
为用户供给真实的个性化体会已成为实际,经过人工智能,体系能够运用由智能手机、可穿戴和其他便携设备的传感器所搜集的数据,为人们供给更多深度功用。未来几年,一系列现在还不可思议的设备和处理方案将会得到更多开展。人工智能和传感器为设计师和用户打开了一个充满了激动人心的时机的新国际。

图4:人工智能和传感器为设计师和用户打开了一个充满了激动人心的时机的新国际。