X-Engine 是集团数据库事业部研制的新一代存储引擎,是新一代分布式数据库X-DB的根基。为了到达10倍MySQL功能,1/10存储本钱的方针,X-DB从一开端就运用了软硬件结合的规划思路, 以充分发挥当时软件和硬件范畴最前沿的技术优势。而引进FPGA加快是咱们在定制核算范畴做出的第一个测验。现在FPGA加快版别的X-DB现已在线上开端小规模灰度,在本年6.18,双11大促中,FPGA将助力X-DB, 将在不添加本钱的前提下,满意阿里事务对数据库更高的功能要求。
布景介绍
作为世界上最大的在线买卖网站,阿里巴巴的 OLTP (online transacTIon processing) 数据库体系需求满意高吞吐的事务需求。依据核算,每天 OLTP 数据库体系的记载写入量到达了几十亿,在2017年的双十一,体系的峰值吞吐到达了千万级TPS (transacTIons per second)。阿里巴巴的事务数据库体系首要有以下几个特色:
事务高吞吐而且读操作和写操作的低延时;
写操作占比相对较高,传统的数据库workload,读写比一般在 10:1 以上,而阿里巴巴的买卖体系,在双十一当天读写比到达了 3:1;
数据拜访热门比较会集,一条新写入的数据,在接下来7天内的拜访次数占全体拜访次数的99%,超越7天之后的被拜访概率极低。
为了满意阿里的事务对功能和本钱近乎严苛的要求,咱们从头规划开发了一个存储引擎称为X-Engine。在X-Engine中,咱们引进了许多数据库范畴的前沿技术,包括高效的内存索引结构,写入异步流水线处理机制,内存数据库中运用的达观并发操控等。
为了到达极致的写功能水平,而且便利别离冷热数据以完结分层存储,X-Engine学习了LSM-Tree的规划思维。其在内存中会保护多个 memtable,一切新写入的数据都会追加到 memtable ,而不是直接替换掉现有的记载。因为需求存储的数据量较大,将一切数据存储在内存中是不或许的。
当内存中的数据到达一定量之后,会flush到耐久化存储中构成 SSTable。为了下降读操作的延时,X-Engine经过调度 compacTIon 使命来定时 compact耐久化存储中的 SSTable,merge多个 SSTable 中的键值对,关于多版别的键值对只保存最新的一个版别(一切当时被事务引证的键值对版别也需求保存)。
依据数据拜访的特色,X-Engine会将耐久化数据分层,较为活泼的数据停留在较高的数据层,而相对不活泼(拜访较少)的数据将会与底层数据进行兼并,并存放在底层数据中,这些底层数据选用高度紧缩的办法存储,而且会迁移到在容量较大,相对廉价的存储介质 (比方SATA HDD) 中,到达运用较低本钱存储许多数据的意图。
如此分层存储带来一个新的问题:即整个体系有必要频频的进行compacTIon,写入量越大,Compaction的进程越频频。而compaction是一个compare & merge的进程,十分耗费CPU和存储IO,在高吞吐的写入景象下,许多的compaction操作占用许多体系资源,必定带来整个体系功能断崖式跌落,对运用体系产生巨大影响。
而彻底从头规划开发的X-Engine有着十分优胜的多核扩展性,能到达十分高的功能,只是前台事务处理就简直能彻底耗费一切的CPU资源,其对资源的运用功率比照InnoDB,如下图所示:
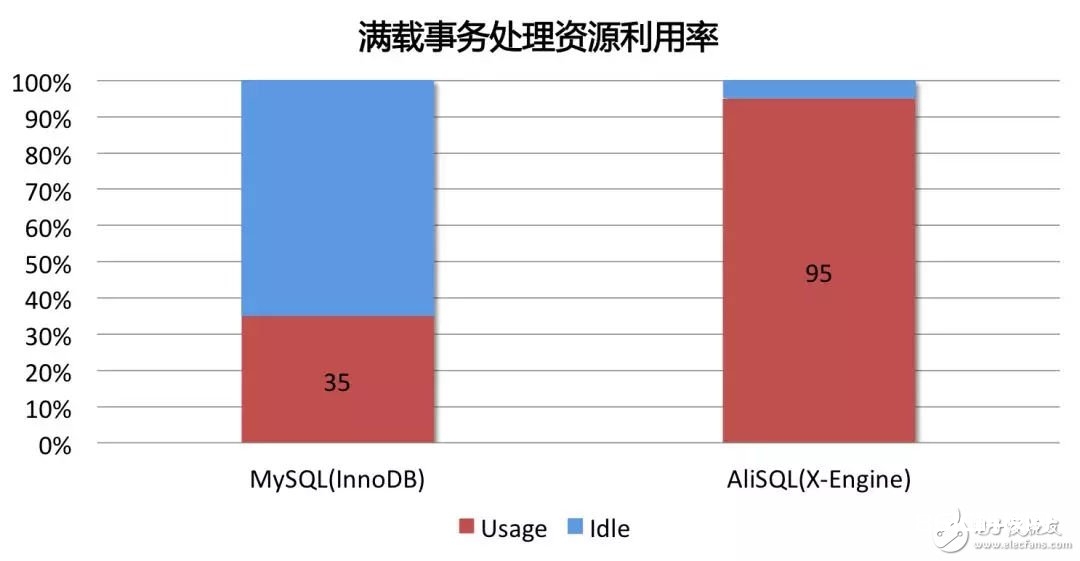
在如此功能水平下,体系没有剩余的核算资源进行compaction操作,不然将承受功能跌落的价值。
经测验,在 DbBench benchmark 的 write-only 场景下,体系会产生周期性的功能颤动,在 compaction 产生时,体系功能跌落超越40%,当 compaction 完毕时,体系功能又康复到正常水位。如下图所示:
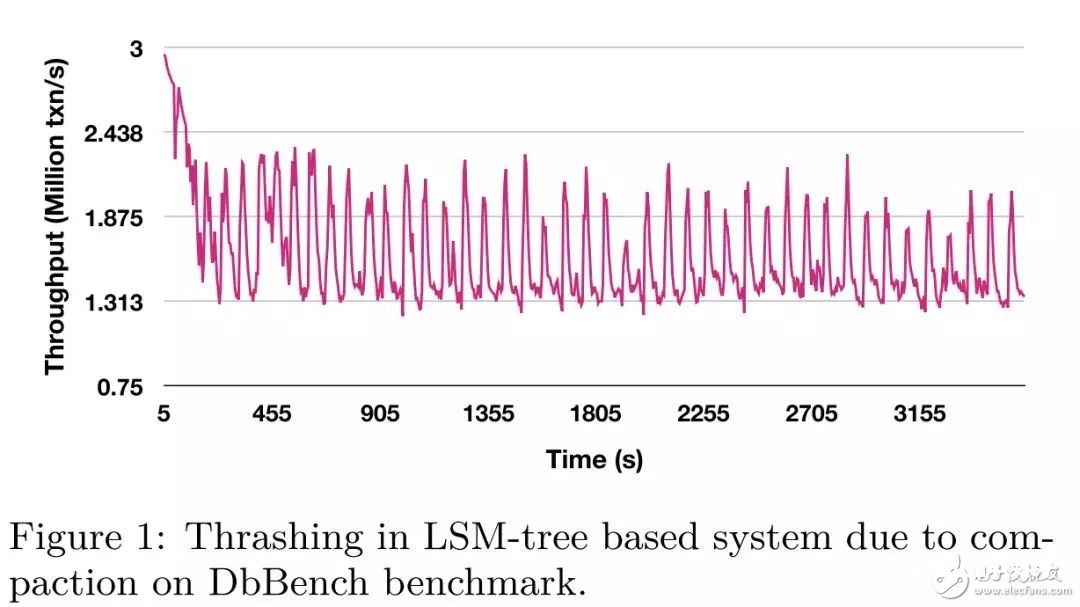
可是假如 compaction 进行的不及时,多版别数据的累积又会严重影响读操作。
为了处理 compaction 的颤动问题,学术界提出了比如 VT-tree、bLSM、PE、PCP、dCompaction 等结构。尽管这些算法经过不同办法优化了 compaction 功能,可是 compaction 自身耗费的 CPU 资源是无法防止的。据相关研讨核算,在运用SSD存储设备时,体系中compaction的核算操作占有了60%的核算资源。因而,不管在软件层面针对 compaction 做了何种优化,关于一切依据 LSM-tree 的存储引擎而言,compaction形成的功能颤动都会是阿喀琉斯之踵。
走运的是,专用硬件的出现为处理compaction导致的功能颤动供给了一个新的思路。实践上,运用专用硬件处理传统数据库的功能瓶颈现已成为了一个趋势,现在数据库中的select、where操作现已offload到FPGA上,而更为杂乱的 group by 等操作也进行了相关的研讨。可是现在的FPGA加快处理计划存在以下两点缺乏:
现在的加快计划根本上都是为SQL层规划,FPGA也一般放置在存储和host之间作为一个filter。尽管在FPGA加快OLAP体系方面现已有了许多测验,可是关于OLTP体系而言,FPGA加快的规划依然是一个应战;
跟着FPGA的芯片尺寸越来越小,FPGA内部的过错比如单粒子翻转(SEU)正在成为FPGA可靠性的越来越大的要挟,关于单一芯片而言,产生内部过错的概率大概是3-5年,关于大规模的可用性体系,容错机制的规划显得尤为重要。
为了缓解compaction对X-Engine体系功能的影响,咱们引进了异构硬件设备FPGA来替代CPU完结compaction操作,使体系全体功能维持在高水位并防止颤动,是存储引擎得以服务事务严苛要求的要害。本文的奉献如下:
FPGA compaction 的高效规划和完结。经过流水化compaction操作,FPGA compaction取得了十倍于CPU单线程的处理功能;
混合存储引擎的异步调度逻辑规划。因为一次FPGA compaction的链路恳求在ms等级,运用传统的同步调度办法会堵塞许多的compaction线程而且带来许多线程切换的价值。经过异步调度,咱们削减了线程切换的价值,提高了体系在工程方面的可用性。
容错机制的规划。因为输入数据的约束和FPGA内部过错,都会形成某个compaction 使命的回滚,为了保证数据的完整性,一切被FPGA回滚的使命都会由平等的CPU compaction线程再次履行。本文规划的容错机制到达了阿里实践的事务需求而且一起规避了FPGA内部的不稳定性。
问题布景
X-Engine的Compaction
X-Engine的存储结构包括了一个或多个内存缓冲区 (memtable)以及多层耐久化存储 L0, L1, … ,每一层由多个SSTable组成。
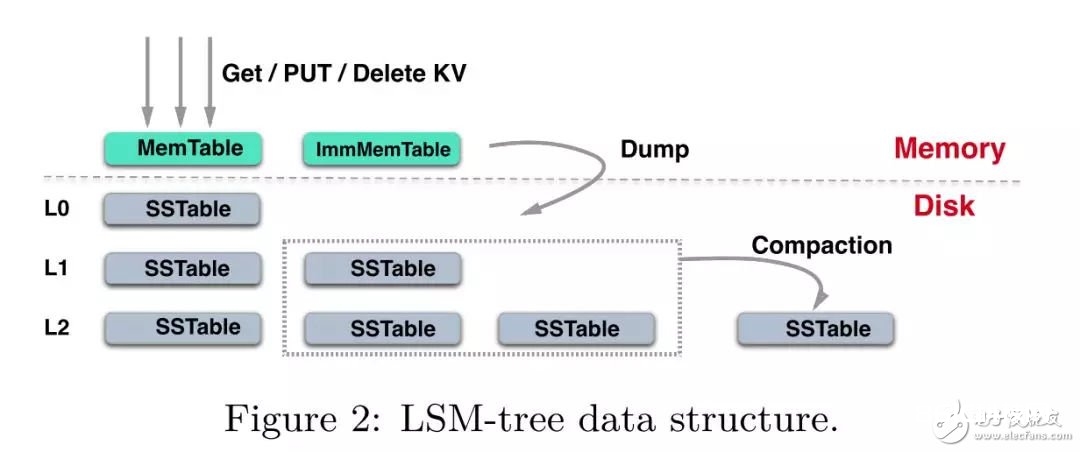
当memtable写满后,会转化为 immutable memtable,然后转化为SSTable flush到L0层。每一个SSTable包括多个data block和一个用来索引data block的index block。当L0层文件个数超越了约束,就会触发和L1层有堆叠key range的SSTable的兼并,这个进程就叫做compaction。相似的,当一层的SSTable个数超越了阈值都会触发和基层数据的兼并,经过这种办法,冷数据不断向下活动,而热数据则驻留在较高层上。
一个compaction进程merge一个指定规模的键值对,这个规模或许包括多个data block。一般来说,一个compaction进程会处理两个相邻层的data block兼并,可是关于L0层和L1层的compaction需求特别考虑,因为L0层的SSTable是直接从内存中flush下来,因而层间的SSTable的Key或许会有堆叠,因而L0层和L1层的compaction或许存在多路data block的兼并。
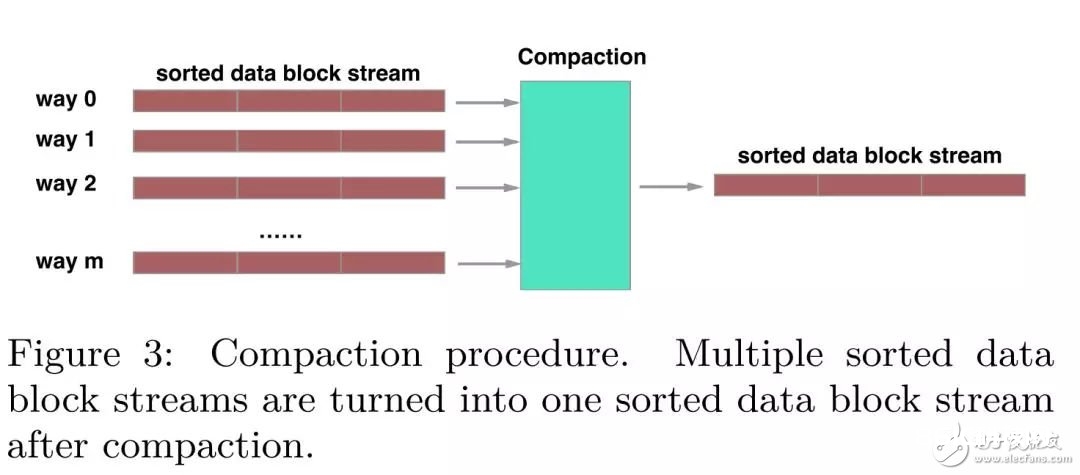
关于读操作而言,X-Engine需求从一切的memtable中查找,假如没有找到,则需求在耐久化存储中从高层向底层查找。因而,及时的compaction操作不只会缩短读途径,也会节约存储空间,可是会争夺体系的核算资源,形成功能颤动,这是X-Engien亟待处理的窘境。
FPGA加快数据库
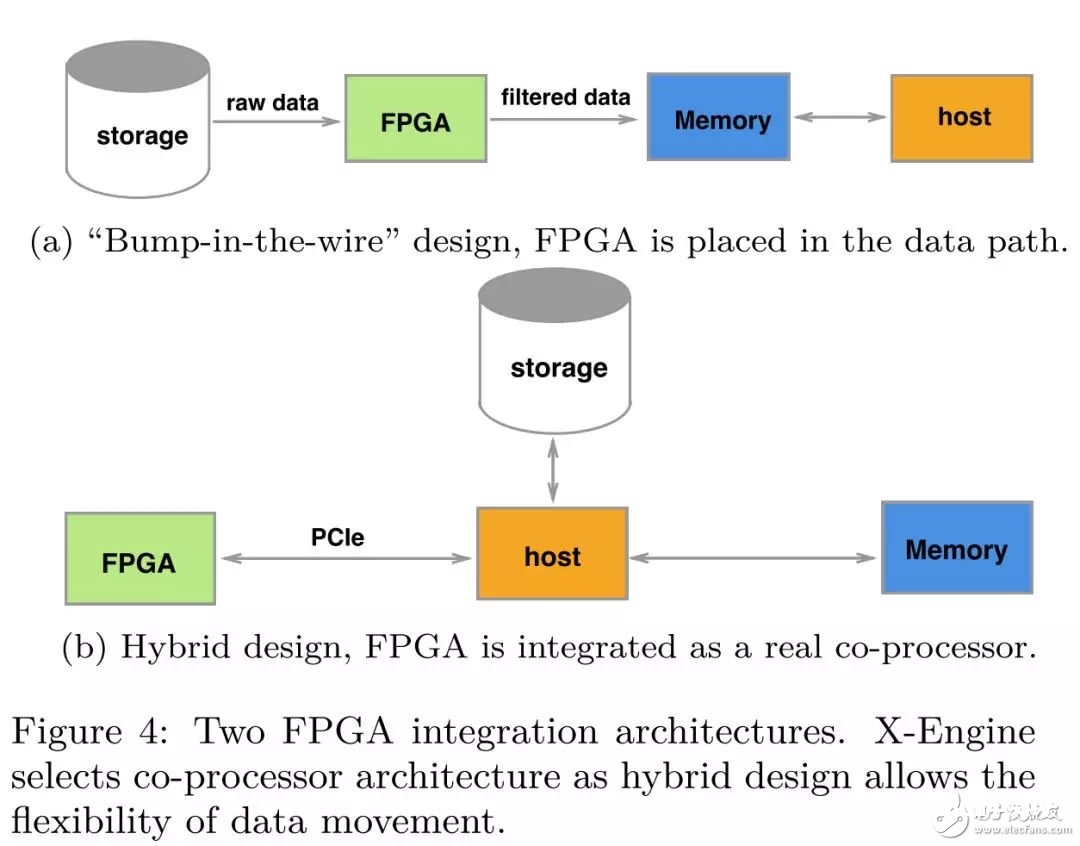
从现在的FPGA加快数据库现状剖析,咱们能够将FPGA加快数据库的架构分为两种,"bump-in-the-wire" 规划和混合规划架构。前期因为FPGA板卡的内存资源不行,前一种架构办法比较盛行,FPGA被放置在存储和host的数据途径上,充任一个filter,这样规划的优点是数据的零复制,可是要求加快的操作是流式处理的一部分,规划办法不行灵敏;
后一种规划计划则将FPGA作为一个协处理器,FPGA经过PCIe和host衔接,数据经过DMA的办法进行传输,只需offload的操作核算满足密布,数据传输的价值是能够承受的。混合架构的规划答应更为灵敏的offload办法,关于compaction这一杂乱操作而言,FPGA和host之间数据的传输是有必要的,所以在X-Engine中,咱们的硬件加快选用了混合规划的架构。
体系规划
在传统的依据LSM-tree的存储引擎中,CPU不只需处理正常的用户恳求,还要担任compaction使命的调度和履行,即关于compaction使命而言,CPU既是出产者,也是顾客,关于CPU-FPGA混合存储引擎而言,CPU只担任compaction使命的出产和调度,而compaction使命的实践履行,则被offload到专用硬件(FPGA)上。
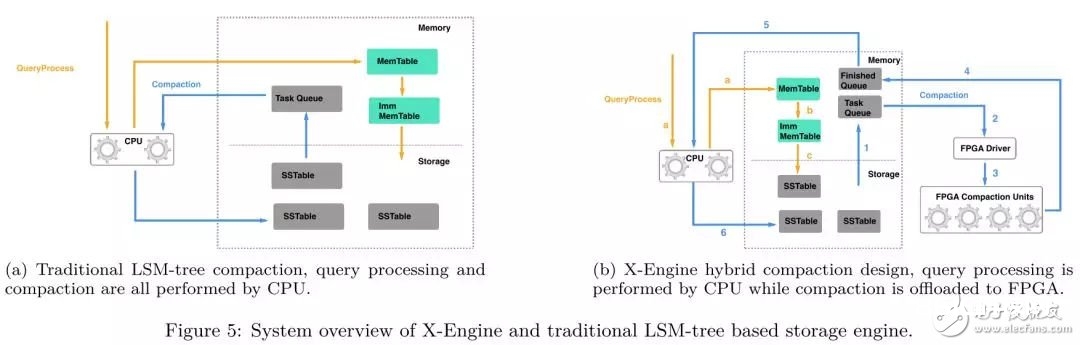
关于X-Engine,正常用户恳求的处理和其他依据LSM-tree的存储引擎相似:
用户提交一个操作指定KV pair(Get/Insert/Update/Delete)的恳求,假如是写操作,一个新的记载会被append到memtable上;
当memtable的巨细到达阈值时会被转化为immutable memtable;
immutable memtable转化为SSTable而且被flush到耐久化存储上。
当L0层的SSTable数量到达阈值时,compaction使命会被触发,compaction的offload分为以下几个进程:
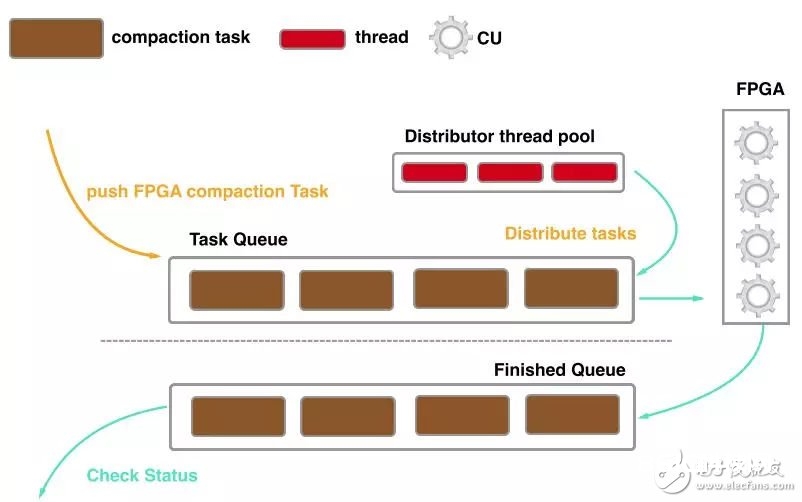
从耐久化存储中load需求compaction的SSTable,CPU经过meta信息依照data block的粒度拆分红多个compaction使命,而且为每个compaction使命的核算成果预分配内存空间,每一个构建好的compaction使命都会被压入到Task Queue行列中,等候FPGA履行;
CPU读取FPGA上Compaction Unit的状况,将Task Queue中的compaction使命分配到可用的Compaction Unit上;
输入数据经过DMA传输到FPGA的DDR上;
Compaction Unit履行Compaction使命,核算完结后,成果经过DMA回传给host,而且顺便return code指示此次compaction使命的状况(失利或许成功),履行完的compaction成果会被压入到Finished Queue行列中;
CPU查看Finished Queue中compaction使命的成果状况,假如compaction失利,该使命会被CPU再次履行;
compaction的成果flush到存储。
具体规划
FPGA-based Compaction
Compaction Unit (CU) 是FPGA履行compaction使命的根本单元。一个FPGA板卡内能够放置多个CU,单个CU由以下几个模块组成:
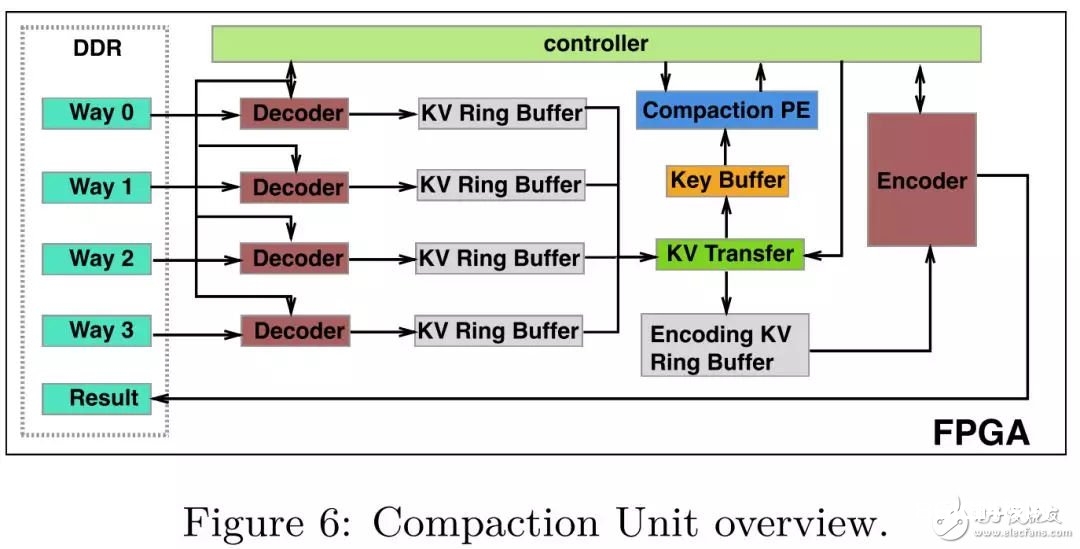
Decoder. 在X-Engine中,KV是经过前序紧缩编码后存储在data block中的,Decoder模块的首要作用是为了解码键值对。每一个CU内部放置了4个Decoder,CU最多支撑4路的compaction,剩余4路的compaction使命需求CPU进行拆分,依据评价,大部分的compaction都在4路以下。放置4个Decoder相同也是功能和硬件资源权衡的成果,和2个Decoder比较,咱们添加了50%的硬件资源耗费,获得了3倍的功能提高。
KV Ring Buffer. Decoder 模块解码后的KV pair都会暂存在KV Ring Buffer中。每一个KV Ring Buffer保护一个读指针(由Controller模块保护)和一个写指针(由Decoder模块保护),KV Ring Buffer 保护3个信号来指示当时的状况:FLAG_EMPTY, FLAG_HALF_FULL, FLAG_FULL,当FLAG_HALF_FULL为低位时,Decoder模块会继续解码KV pair,不然Decoder会暂停解码直到流水线的下流耗费掉现已解码的KV pair。
KV Transfer. 该模块担任将key传输到Key Buffer中,因为KV的merge只触及key值的比较,因而value不需求传输,咱们经过读指针来追寻当时比较的KV pair。 Key Buffer. 该模块会存储当时需求比较的每一路的key,当一切需求比较的key都被传输到Key Buffer中,Controller会告诉Compaction PE进行比较。
Compaction PE. Compaction Processing Engine (compaction PE)担任比较Key Buffer中的key值。比较成果会发送给Controller,Controller会告诉KV Transfer将对应的KV pair传输到Encoding KV Ring Buffer中,等候Encoder模块进行编码。
Encoder. Encoder模块担任将Encoding KV Ring Buffer中的KV pair编码到data block中,假如data block的巨细超越阈值,会将当时的data block flush到DDR中。
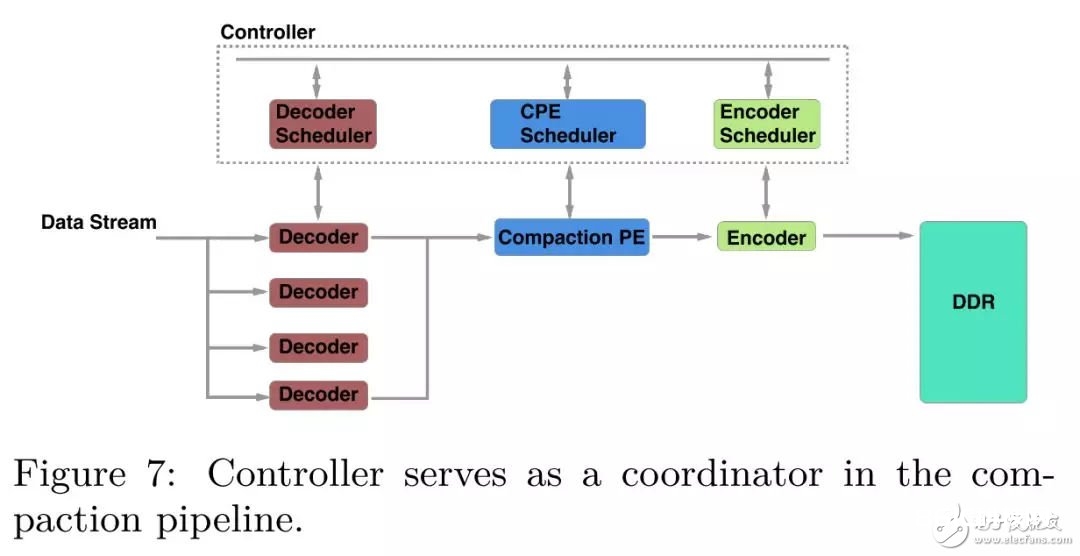
Controller. 在CU中Controller充任了一个和谐器的作用,尽管Controller不是compaction pipeline的一部分,单在compaction 流水线规划的每一个进程都发挥着要害的作用。
一个compaction进程包括三个进程:decode,merge,encode。规划一个适宜的compaction 流水线的最大应战在于每一个进程的履行时刻距离很大。比方说因为并行化的原因,decode模块的吞吐远高于encoder模块,因而,咱们需求暂停某些履行较快的模块,等候流水线的下流模块。为了匹配流水线中各个模块的吞吐差异,咱们规划了controller模块去和谐流水线中的不同进程,这样规划带来的一个额定优点是解耦了流水线规划的各个模块,在工程完结中完结更灵敏的开发和保护。
在将FPGA compaction集成到X-Engine中,咱们期望能够得到独立的CU的吞吐功能,试验的baseline是CPU单核的compaction线程 (Intel(R) Xeon(R) E5-2682 v4 CPU with 2.5 GHz)
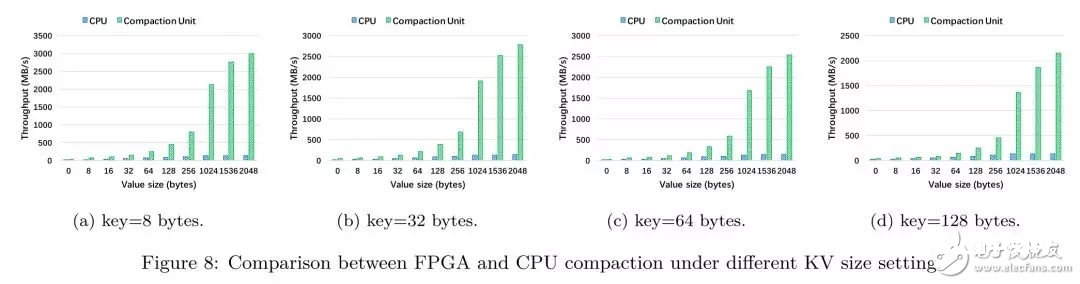
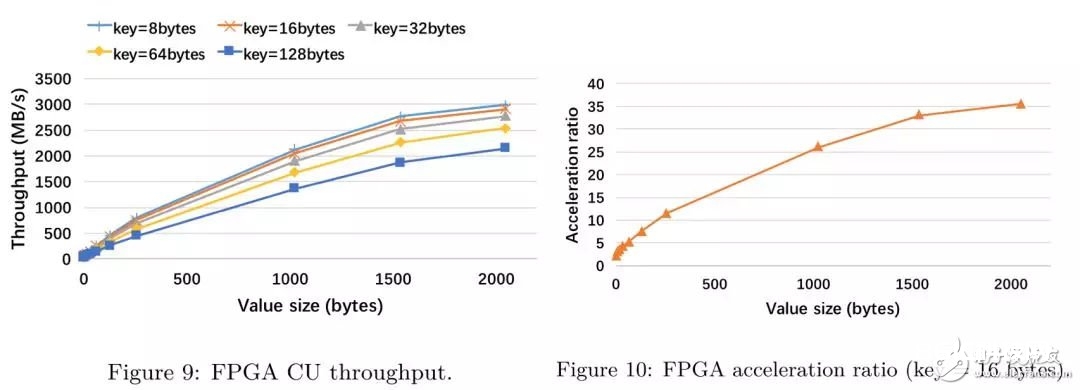
从试验中咱们能够得到以下三个定论:
在一切的KV长度下,FPGA compaction的吞吐都要优于CPU单线程的处理才能,这印证了compaction offload的可行性;
跟着key长度的添加,FPGA compaction的吞吐下降,这是因为需求比较的字节长度添加,添加了比较的价值;
加快比(FPGA throughput / CPU throughput)跟着value长度的添加而添加,这是因为在KV长度较短时,各个模块之间需求频频进行通讯和状况查看,而这种开支和一般的流水线操作比较是十分贵重的。
异步调度逻辑规划
因为FPGA的一次链路恳求在ms等级,因而运用传统的同步调度办法会形成较频频的线程切换价值,针对FPGA的特色,咱们从头规划了异步调度compaction的办法:CPU担任构建compaction task并将其压入Task Queue行列,经过保护一个线程池来分配compaction task到指定的CU上,当compaction完毕后,compaction使命会被压入到Finished Queue行列,CPU会查看使命履行的状况,关于履行失利的使命会调度CPU的compaction线程再次履行。经过异步调度,CPU的线程切换价值大大削减。
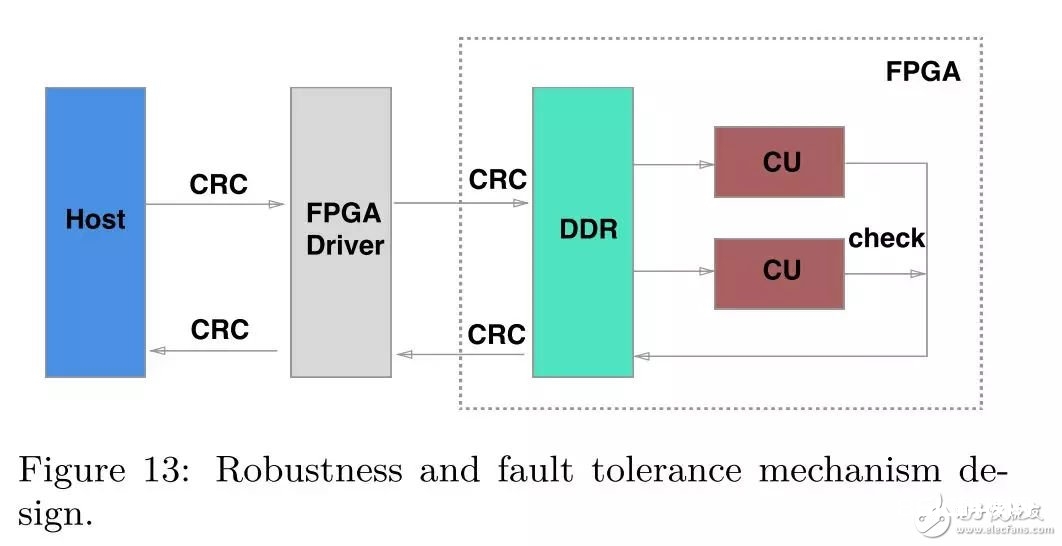
容错机制的规划
关于FPGA compaction而言,有以下三种原因或许会导致compaction 使命犯错
数据在传输进程中被损坏,经过在传输前和传输后别离核算数据的CRC值,然后进行比对,假如两个CRC值不一致,则标明数据被损坏;
FPGA自身的过错(比特位翻转),为了处理这个过错,咱们为每一个CU装备了一个附加CU,两个CU的核算成果进行按位比对,不一致则阐明产生了比特位翻转过错;
compaction输入数据不合法,为了便利FPGA compaction的规划,咱们对KV的长度进行了约束,超越约束的compaction使命都会被判定为不合法使命。
关于一切犯错的使命,CPU都会进行再次核算,保证数据的正确性。在上述的容错机制的下,咱们处理了少数的超越约束的compaction使命而且规避了FPGA内部过错的危险。
试验成果
试验环境
CPU:64-core Intel (E5-2682 v4, 2.50 GHz) processor
内存:128GB
FPGA 板卡:Xilinx VU9P
memtable: 40 GB
block cache 40GB
咱们比较两种存储引擎的功能:
X-Engine-CPU:compaction操作由CPU履行
X-Engine-FPGA:compaction offload到FPGA履行
DbBench
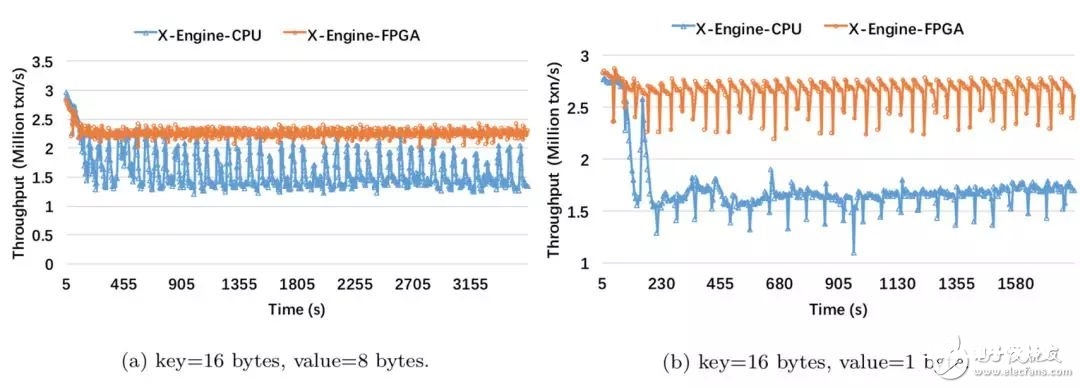
成果剖析:
在write-only场景下,X-Engine-FPGA的吞吐提高了40%,从功能曲线咱们能够看出,当compaction开端时,X-Engine-CPU体系的功能跌落超越了三分之一;
因为FPGA compaction吞吐更高,更及时,因而读途径削减的更快,因而在读写混合的场景下X-Engine-FPGA的吞吐提高了50%;
读写混合场景的吞吐小于纯写场景,因为读操作的存在,存储在耐久层的数据也会被拜访,这就带来了I/O开支,然后影响了全体的吞吐功能;
两种功能曲线代表了两种不同的compaction状况,在左图,体系功能产生周期性的颤动,这阐明compaction操作在和正常事务处理的线程竞赛CPU资源;关于右图,X-Engine-CPU的功能一向稳定在低水位,标明compaction的速度小于写入速度,导致SSTable堆积,compaction使命继续在后台调度;
因为compaction的调度依然由CPU履行,这也就解说了X-Engine-FPGA依然存在颤动,并不是肯定的滑润。
YCSB
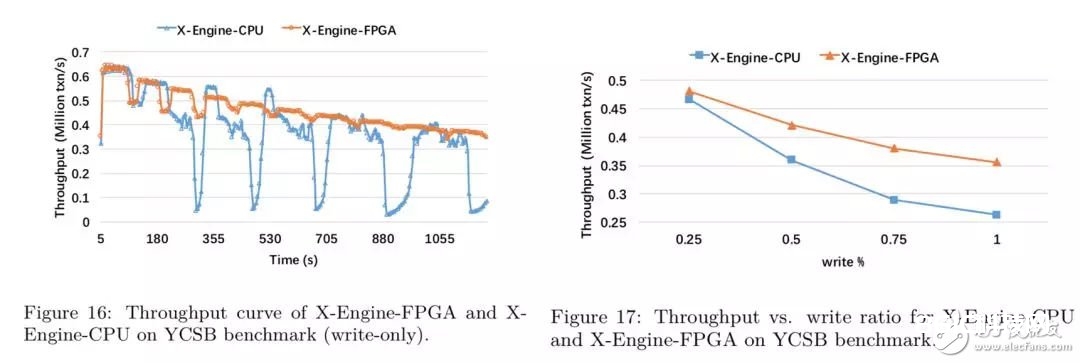
成果剖析:
在YCSB benchmark上,因为compaction的影响,X-Engine-CPU的功能下降了80%左右,而关于X-Engine-FPGA而言,因为compaction调度逻辑的影响,X-Engine-FPGA的功能只要20%的起浮;
check unique的存在引进了读操作,跟着压测时刻的添加,读途径变长,因而两个存储引擎的功能跟着时刻下降;
在write-only场景下,X-Engine-FPGA的吞吐提高了40%,跟着读写比的上升,FPGA Compaction的加快作用逐步下降,这是因为读写比越高,写入压力越小,SSTable堆积的速度越慢,因而履行compaction的线程数削减,因而关于写密布的workload,X-Engine-FPGA的功能提高越显着;
跟着读写比的上升,吞吐上升,因为写吞吐小于KV接口,因而cache miss的份额较低,防止了频频的I/O操作,而跟着写份额的上升,履行compaction线程数添加,因而下降了体系的吞吐才能。
TPC-C (100 warehouses)
ConnectionsX-Engine-CPU X-Engine-FPGA
128
214279
240105
256
203268
230401
512
197001
219618
1024
189697
208532
成果剖析: