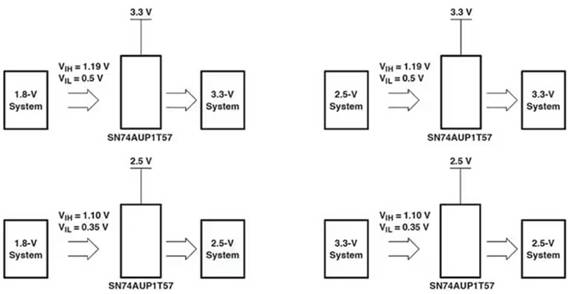
导语:循环神经网络(RNNs)具有保存回忆和学习数据序列的才能。因为RNN的循环性质,难以将其一切核算在传统硬件上完结并行化。当时CPU不具有大规模并行性,而因为RNN模型的次序组件,GPU只能供给有限的并行性。针对这个问题,普渡大学的研究人员提出了一种LSTM在Zynq 7020 FPGA的硬件完结计划,该计划在FPGA中完结了2层128个躲藏单元的RNN,而且运用字符级言语模型进行了测验。该完结比嵌入在Zynq 7020 FPGA上的ARM Cortex-A9 CPU快了21倍。
LSTM是一种特别的RNN,因为共同的规划结构,LSTM适合于处理和猜测时刻序列中距离和推迟十分长的重要事情。规范的RNN能够保存和运用最近的曩昔信息,可是不能学习长时刻的依靠联系。而且因为存在梯度消失和爆破的问题,传统的RNN无法练习较长的序列。为了处理上述问题,LSTM增加了回忆操控单元来决议何时记住、忘记和输出。LSTM的单元结构如图1所示。其间⊙代表element-wise的乘法。

图1
用数学表达式表明图1如图2所示。其间表明Sigmoid函数,是层的输入向量,是模型参数,是回忆单元激活值,是候选回忆单元门,是层的输出向量。下标表明前一时刻,便是相应的输入、忘记和输出门。这些门决议何时记住或忘记一个输入序列,以及何时输出。人们需求对模型进行练习,然后得到所需的输出参数。简略来说,模型练习是一个迭代进程,其间练习数据被输入,然后将得到的输出与方针进行比较。模型经过BP算法进行练习。因为增加了更多的层和更多的不同的功用,模型能够变得适当杂乱。 关于LSTM,每个模块有四个门和一些element-wise的操作。 深层LSTM网络具有多个LSTM模块级联,使得一层的输出是下一层的输入。

图2
了解完了LSTM的特性后,怎么规划LSTM在FPGA上的完结呢?下面咱们来看一下完结计划。
1)硬件
硬件完结的首要操作便是矩阵向量乘法和非线性函数。
矩阵向量乘法由MAC单元核算, MAC单元需求两个流:输入向量流和加权矩阵的行向量流。将相同的矢量流与每个权重矩阵行相乘并累加,以发生与权重矩阵的高相同尺度的输出向量。在核算每个输出元素之后,MAC被重置以防止累积从前的矩阵行核算。能够经过向权重矩阵的终究一列增加偏置向量来将偏置b增加到乘法累加中,一起为输入向量增加一个额定的单位值。这样就不需求为偏置增加额定的输入端口,也能够向MAC单元增加额定的预装备过程。 将MAC单元的成果加在一起。加法器的输出是一个元素的非线性函数,它是用线性映射来完结的。
非线性函数被分割成线性y = ax + b,其间x限于特定规模。在装备阶段,a,b和x规模的值存储在装备寄存器中。每个线性函数段用MAC单元和比较器完结。输入值与线性规模之间的比较决议是处理输入仍是将其传递给下一个线性函数段模块。非线性函数分为13个线段,因而非线性模块包括13个流水线段模块。 施行规划的首要组成部分是如图3所示的门模块。

图3
完结模块运用直接存储拜访(DMA)端口来进行数据的读入或写出。因为DMA端口是独立的,因而即便模块一起激活端口,输入流也不会同步。因而,需求流同步模块。该同步块用来缓存一些流数据,直到一切端口都是流式传输。当终究一个端口开端传输时,同步块开端输出同步流。这样就能保证到MAC单元的向量和矩阵行元素对齐。别的,图3中的门模块还包括一个将32位值转换为16位值的重分区块。MAC单元履行16位乘法,发生32位值。然后运用32位值履行加法以坚持精度。
图2中的公式1,2,3,4都能用上述模块完结,剩余的仅仅核算公式5和6的一些element-wise的运算。为此,计划引进了如图4所示的包括额定的乘法器和加法器的模块。

图4
终究构成的完结LSTM的计划如图5所示。该计划运用图3中的三个模块和图4中的一个。门被预装备为具有非线性函数(tanh或S形)。内部模块由状态机操控以履行一系列操作。完结的规划运用四个32位DMA端口。因为操作以16位完结,每个DMA端口能够传输两个16位流。权重和连接在主存储器中以运用该特征。然后依据要履行的操作将流路由到不同的模块。

图5
2)驱动软件
操控和测验软件用C代码完结。该软件将权重值和输入向量放入主存储器,并运用一组装备寄存器操控硬件模块。权重矩阵的每行结束是相应的偏置值。输入向量包括一个额定的单位值,使得矩阵向量乘法仅增加矩阵行的终究一个元素。零填充用于匹配矩阵行尺度和向量尺度,这使流同步更简单。
因为LSTM的循环性质,每次循环c和h都被掩盖。这样做能够最大极限地削减CPU完结的内存仿制次数。为了完结多层LSTM,将上一层的输出仿制到下一层的方位,以便在层之间保存以进行过错衡量。此外,操控软件还需求经过在操控寄存器中设置不同的存储方位来更改不同层的权重。
试验和试验成果
试验完结了一个字符级言语模型,它猜测了给定前一个字符的下一个字符。依据字符,模型生成一个看起来像练习数据集的文本,它能够是一本书或大于2 MB字的大型互联网语料库。本试验选取莎士比亚的一部分著作进行了练习。试验完结了一个躲藏层巨细为128的2层LSTM模型。
该计划在包括Zynq-7000 SOC XC7Z020的Zedboard上完结。它包括双ARM Cortex-A9 MPCore,该试验选用的C代码LSTM的完结在Zedboard的双ARM Cortex-A9处理器上运转,时钟频率为667 MHz。在FPGA上的完结运转的时钟频率为142 MHz的。芯片总功率为1.942 W,硬件运用率如表1所示。

表1
图6展现了不同嵌入式渠道上的前馈LSTM字符级言语模型的履行时刻,时刻越越好。咱们看到,即便是在142MHz的时钟频率下,该完结仍然比嵌入在Zynq 7020 FPGA上的ARM Cortex-A9 CPU的完结快了21倍。
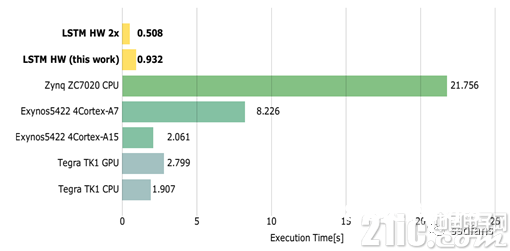
图6
图7展现了不同嵌入式渠道的单位功耗功能(值越大表明功能越好)。从图中成果能够看出,FPGA的完结单位功耗功能远超其他渠道,这进一步说明晰FPGA完结的优越性。
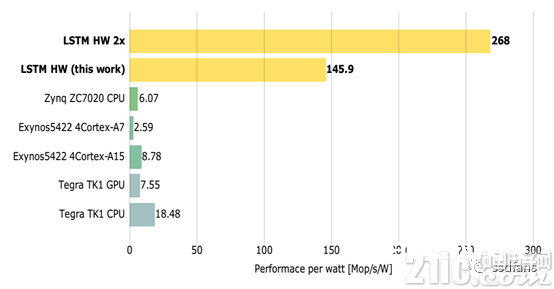
图7